赛尔原创 | AAAI 2019 使用循环条件注意力结构探索回答立场检测任务
论文名称:Exploring Answer Stance Detection with Recurrent Conditional Attention
论文作者:袁建华,赵妍妍,许静芳,秦兵
原创作者:哈工大 SCIR 博士生袁建华
1. 引言
社区问答平台是社会媒体的重要组成部分,其中蕴含大量与人们生活息息相关的提问及回答文本。从这些社区问答QA对中提取人们对问题的观点立场倾向性是一个有意思的问题,用自动化方法挖掘某一问题下所有回答针对该问题的立场倾向性,能为人们提供合理、整体的参考信息。
在现有的研究立场分析的大部分工作中,立场表达针对的对象(target)要么是实体(entity),要么是声明(claim)。不同于以往的立场分析任务,在我们研究的答案立场分析任务中,立场针对的对象是整个问题,需要先理解问题中提问者关心的内容的语义。相比之前的研究问题,更难去建模依赖问题的(target-dependent)回答句表示。
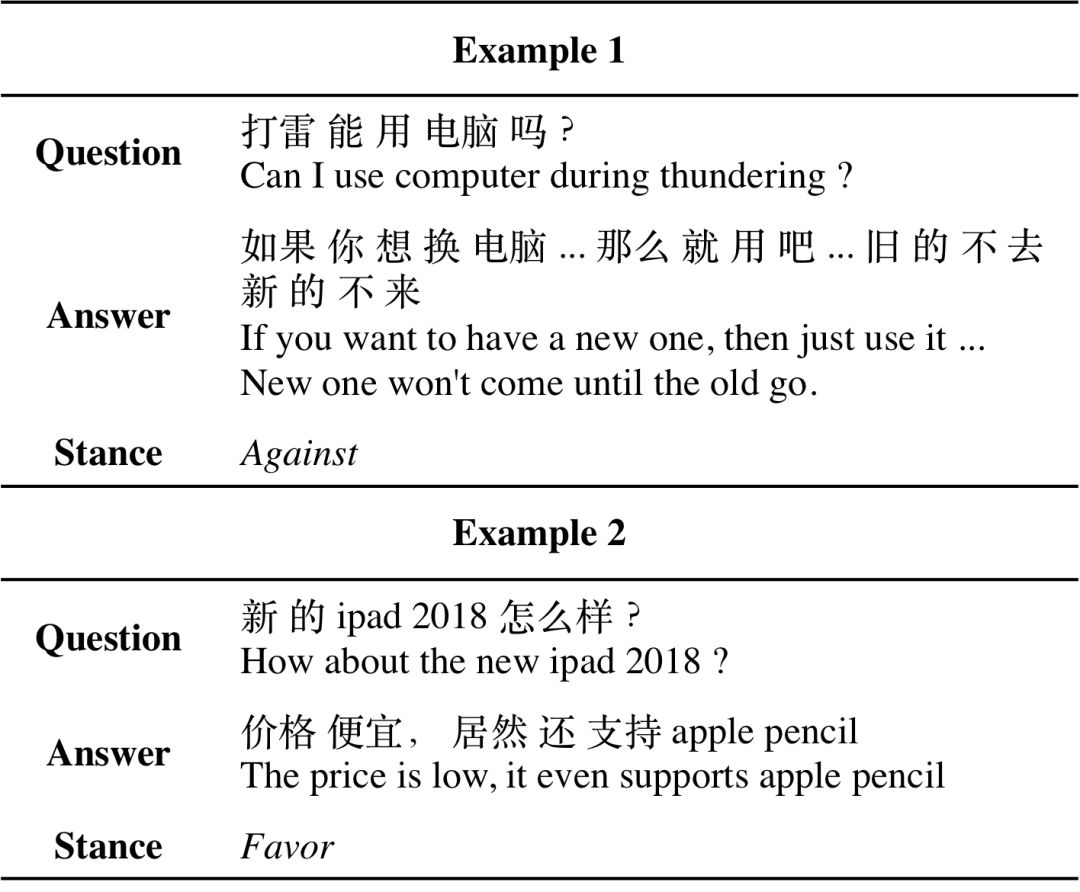
图1 两类回答立场检测任务示例
我们人工收集标注了一个13000多条的社区问答立场倾向性数据集。在该数据集上,我们将RCA与多个性能优异的现有立场分析模型进行对比。相比四个强基线模型,我们的RCA模型在macro-f1值平均提高2.90%,在micro-f1值上平均提高2.66%,在Accuracy指标上也显著优于所有基线模型,证明了我们的模型循环阅读和交错更新结构的有效性。
2. 问题定义
这里,我们给出AnswerStance classification(回答立场分类)的任务定义,我们把它当做一个target-dependent任务来处理。
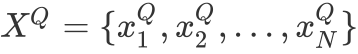

3. 模型
问题句和回答建模网络
依赖于问题句信息的回答句表示网络
立场倾向性表示迭代更新网络
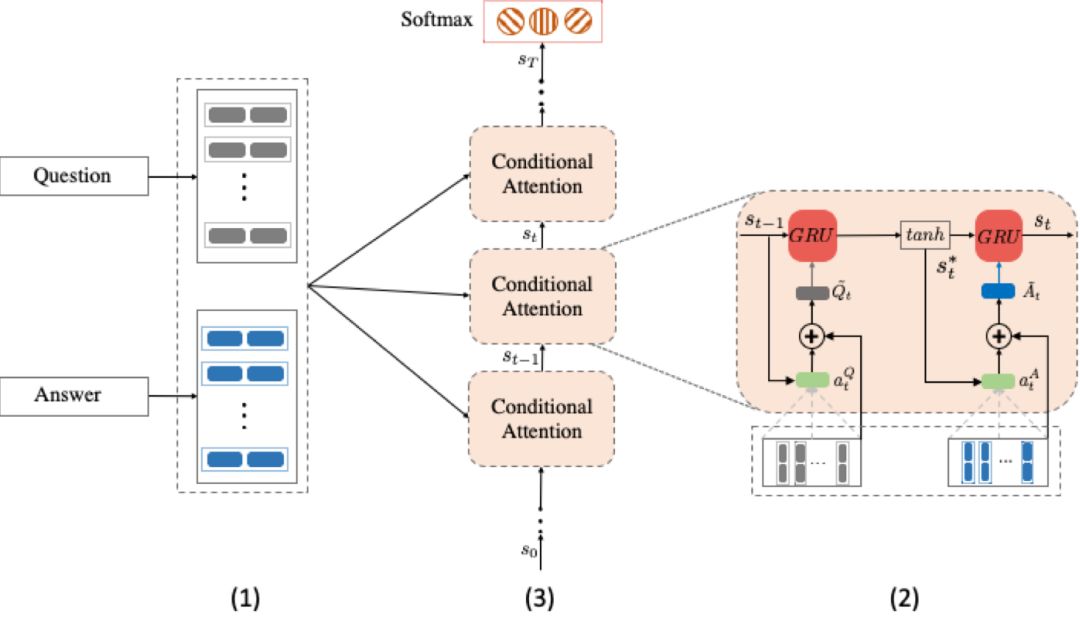
图2 RCA整体架构
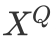
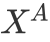

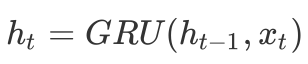
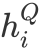
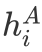
3.2 条件注意力网络
显而易见,判别最终的立场应该同时考虑回答句和问题句的内容,需要利用二者的互相关系,发掘文本中与立场倾向相关的语义内容。下面介绍如何从问题句和回答句的表示中,构建立场倾向性的特征表示。
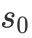
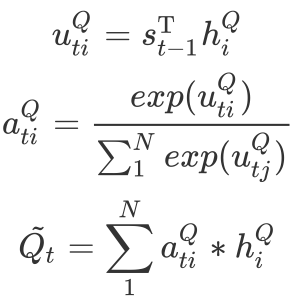
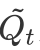
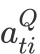
3.2.2 回答句注意力网络
同样地,回答句中不同词对于判断其立场倾向的贡献也存在差异。我们用类似的方法有侧重地学习回答句的表示。这里,CA模块先使用新的问题句信息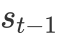
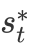
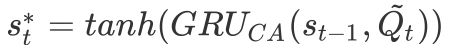
因为
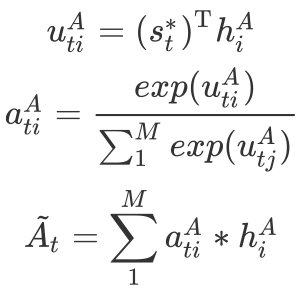
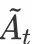
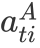
3.3 立场表示迭代更新网络
显然,最终的立场类别直接依赖于最新的回答句内容,我们需要将
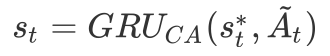
到此为止,我们完成了RCA模型对问答对的一次阅读过程。注意,这里的一次阅读过程对应两个GRU时刻更新。
。这里,我们根据实验结果将k设为3。
在多步阅读过程中,立场状态向量
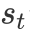
4. 实验设置
4.1 数据集
我们从百度知道、搜狗问问、明医等网站爬取、清洗并标注数据,最终得到的13591条问答对语料,语料主要涉及怀孕、食品、安全、疾病等话题。语料的统计信息如下表:
表1 社区问答中带标注的回答立场数据统计

4.2 评价方法
neutral类别的结果。我们采用favor和against两类的宏平均和微平均F1值作为评价指标。另外我们也提供了所有标签的accuracy作为各模型对比的参考指标。
4.3 对比模型
实验中,我们对比了基础的词袋模型、双向LSTM模型、CNN模型,以及近年来在立场分类和QA等任务上取得较好成绩的TAN(IJCAI2017)、BiCond(EMNLP2016)、AoA(ACL2017)和RAM(EMNLP2017)模型。
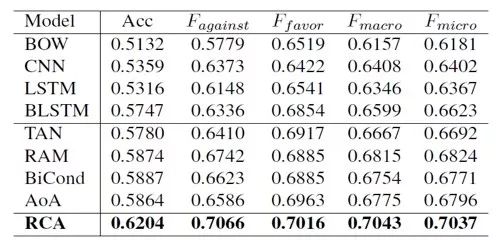
5. 实验结果
从实验结果来看,我们的RCA模型在宏平均、微平均以及Accuracy等指标上,取得了优于所有基线模型的效果,证明了RCA模型的有效性。
表2 测试集上不同立场检测模型的性能比较
另外通过对Attention权重的可视化,我们可以看到不同模型在提取问题句和回答句语义的差别。这个例子中,只有RCA模型在判断立场类别时,能同时给问题句和回答句词合适的权重。

图3 四个模型的注意力权重的可视化图。注意,只有RCA和AoA会在问题上产生注意力,而且我们只会在RAM和RCA模型的最后读取步骤中表示注意力。更深的颜色意味着更大的概率。
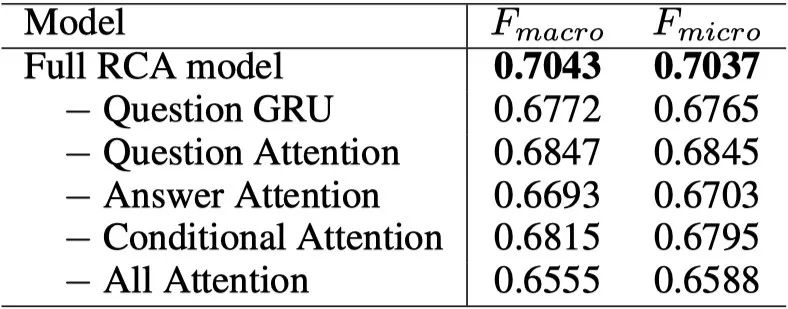
为了分析RCA模型各部分结构对于模型性能的影响,我们做了结构抹除测试。从表格中我们可以看出,问题句的表示对于模型性能影响很大;使用问题句信息从回答句中寻找重要的语义信息比用回答句从问题句提取信息来得更重要。
表3 RCA模型在测试集上的消融测试。呈现宏观和微观平均F1分数。
在下面的两个例子中,我们发现RCA模型的确能在多次阅读过程中,逐步调整问题句和回答句中词的权重,改变其对应的特征表示,并最终做出正确的立场倾向性判断。
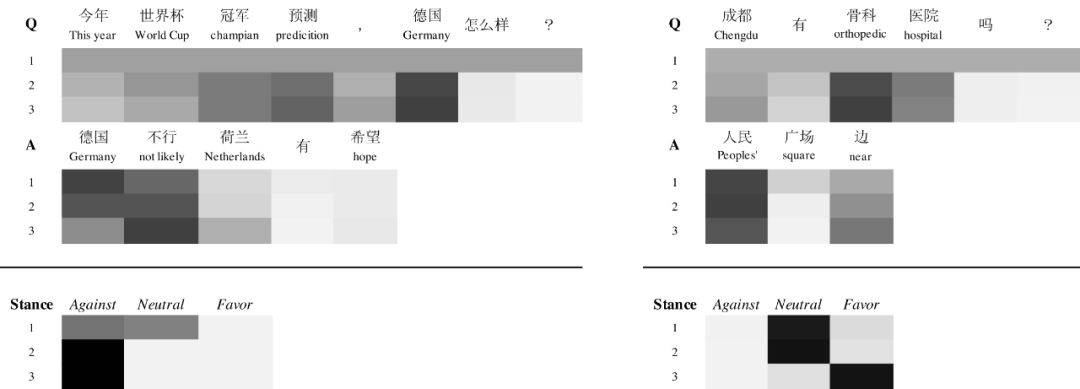
图4 通过softmax分类器和针对示例的每个问题和答案词的注意权重在每个读取步骤中的立场状态的可视化。更深的颜色意味着更大的概率。具有3个读取步骤的RCA模型用于说明。
6. 结论
在本文中,我们针对社区问答中的立场分析任务(AnswerStance),开发了RCA模型,它通过建模问题句和回答句之间的相互表示,在多次阅读过程中不断提炼问答对的语义表示,逐步更新立场状态,并最终做出更准确的立场判断。
在未来的工作中,RCA模型既可以应用到句对作为输入的任务上,如文本蕴含、句子匹配等任务;也可以结合强化学习方法,根据句对输入的语义复杂程度,动态决定阅读次数。
本期责任编辑:刘一佳
本期编辑:赖勇魁
“哈工大SCIR”公众号
主编:车万翔
副主编:张伟男,丁效
责任编辑:张伟男,丁效,刘一佳,崔一鸣
编辑:李家琦,吴洋,刘元兴,蔡碧波,孙卓,赖勇魁
长按下图并点击 “识别图中二维码”,即可关注哈尔滨工业大学社会计算与信息检索研究中心微信公共号:”哈工大SCIR” 。


