基于汉语短文本对话的立场检测系统理论与实践
阅读大概需要5分钟

汉语短文本对话立场检测的主要任务就是通过以对话的一个人的立场为主要立场,而判断另一个人针对该人的回话的立场。立场包括支持,反对,中立三种立场。基于对话的立场检测应用方向很广,比如人机对话系统,机器需要判断对方说话的立场是什么来决定自己回话的立场;比如情感挖掘,和一个支持者的立场进行对话,就能判断出该对话者的情感倾向。
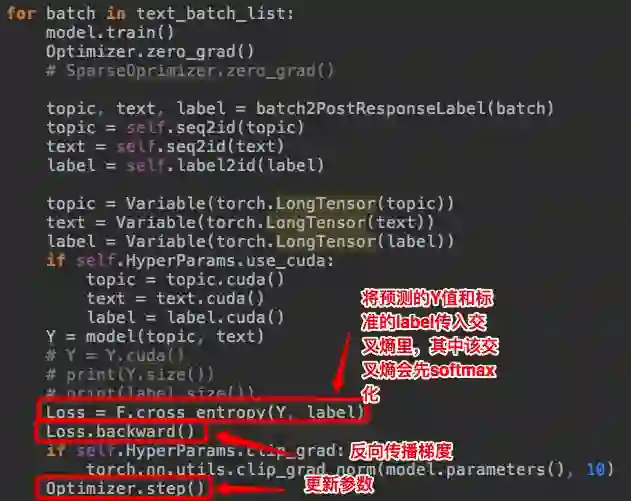
本文采用深度学习的方法,使用双向 LSTM 神经网络进行对给定答案的微博对话语料进行训练。每一份训练样例包含博主的话和回话者的对话,博主和回话者的话都有各自对话的立场表示标注,回话者还有针对博主的立场方向标注自己的立场。本文用的新颖方法是将博主和回话者的话分别经过双向 LSTM,将结果拼接到一起,在经过池化层和线性层得到分类结果。通过该结果和标准的答案比较,通过交叉熵得出损失值,反向传播梯度,更新参数,达到训练模型的效果。最后通过调参得出在测试集上效果最佳的模型为最终的模型。并使用该模型,对人工输入的对话进行真实的立场预测。


[PO]为post,博主说的话,[RE]为response,回答博主的话。而立场检测就是为了站在博主的立场,来检测其他回复的立场。所以需要标记post的立场,这里是积极的,positive,简称p,这里用[PO]STANCE#p表示;而回复response是不支持post的观点的,就是消极的,negative,简称n;但是有时候也是中立的,不支持也不反对post的话,那就是中立的,middle,简称m。
那么这里对数据进行处理:

又因为句子本身的情感极性也会对立场判断有影响,所以再标上每个句子的极性:[PO]是个积极的句子,这里用[PO]POLAR#p来表示,即post 极性为positive;[RE]极性为消极的,即这里用[RE]POLAR#n来表示:

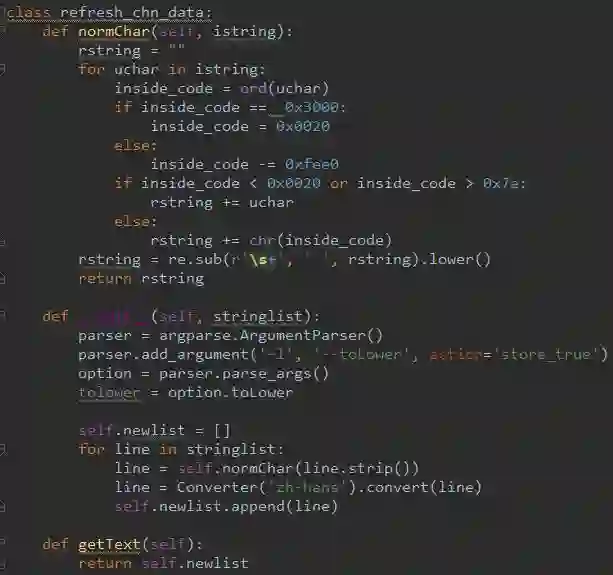
一段文本,中英文都会有,所以对中英文都得分别处理。对中文的处理:
(1)繁体转简体
(2)全角英文字母转半角
(3)全角中文标点转半角
举个例子

代码为:
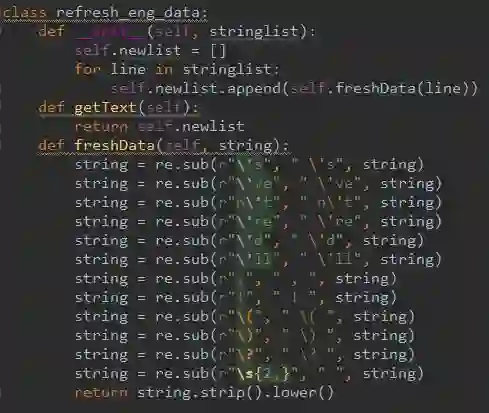
2.对英文语料的清洗
因为中文中掺杂着英文是很正常的事,所以还是有必要处理下英文的文本。
对英文的处理分为以下几个方面:
为了好区分,下面用下划线(_)表示空格
(1)将缩写词用空格分开:
比如Tom’s改为Tom_’s;I’ve改为I_ ‘ve;don’t改为do_n‘t;we’re改为we_’re;you’d改为you_’d;we’ll改为we_’ll
(2)一些标点符号需要和词分开:
比如 , 改为 _,_ ;!改为_!_;(改为_(_;)改为_)_;?改为_?_
(3)连续两个以上的空格修改为一个空格
(4)全都改为小写
建立字典的主要代码
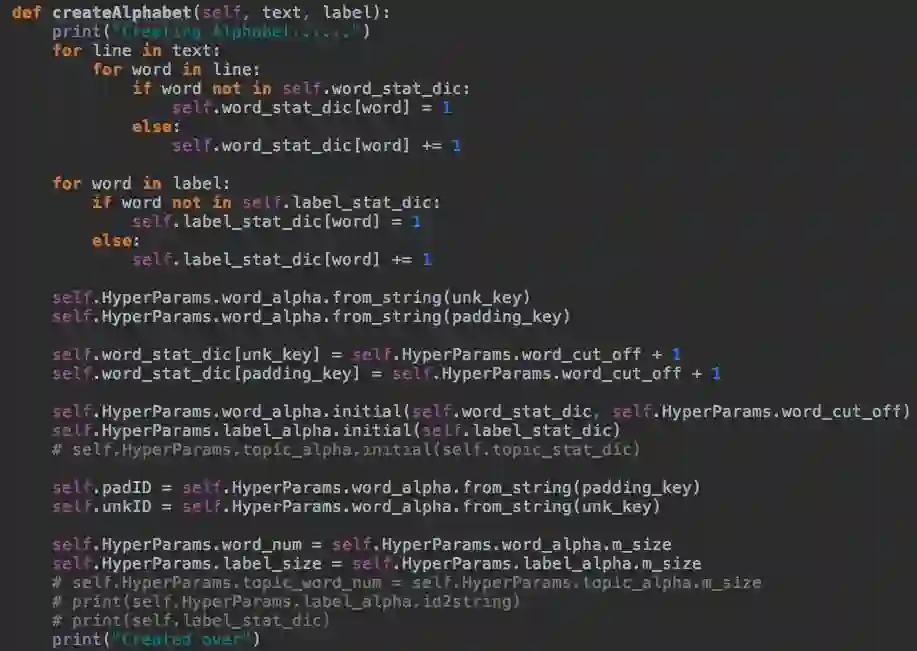
其中想了解HyperParams类代码,在下面的链接里我会附上github源代码。
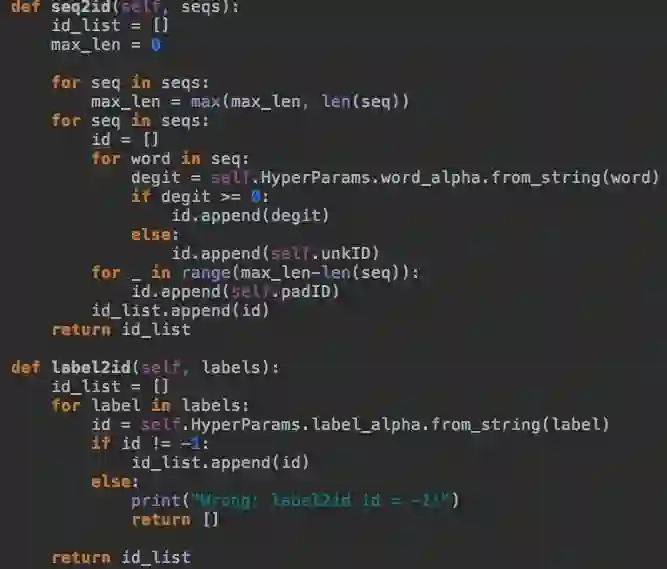
上述流程图为
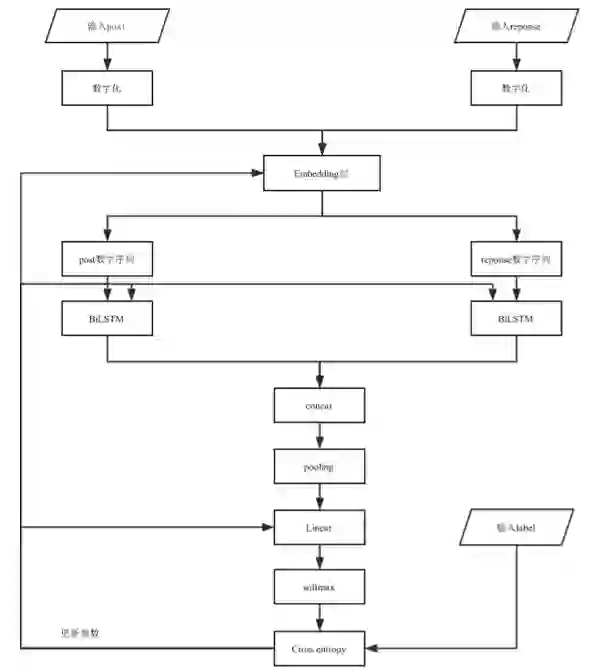
简单的来说,该神经网络总结为post和response先分别经过Embedding层;然后进行dropout;之后将其结果放入biLSTM里,获得输出;然后将该输出concat到一起;再经过pooling层;最后经过线性层映射到分类上即可。
注:其中最后过线性层之前的数据有些庞大,大概有百个数值,直接映射3分类上,会使得数据损失的信息较大。所以这里采用两次经过线性层,中间用了一个激活函数进行非线性变换。
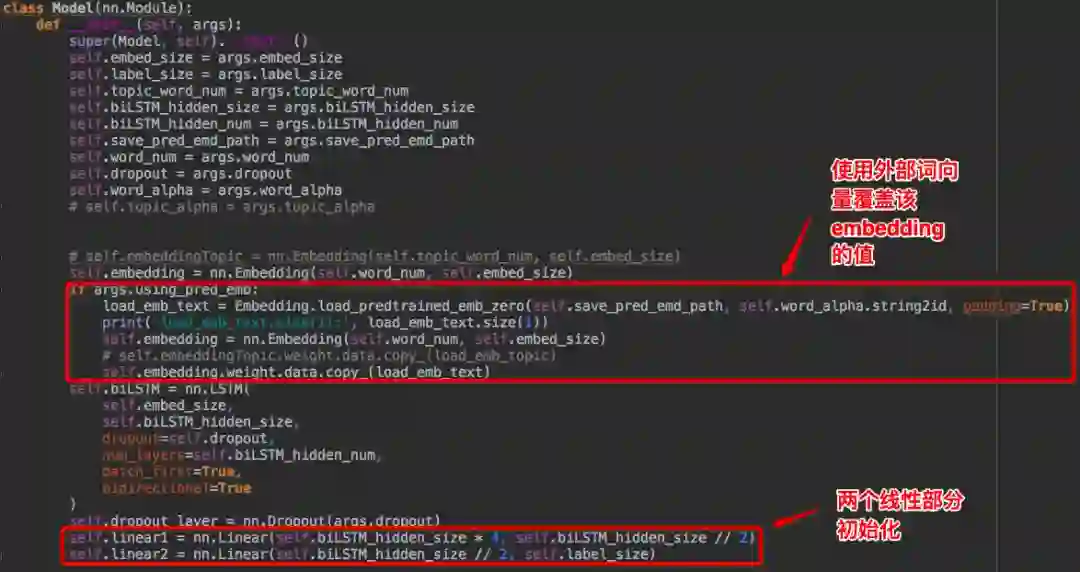
网络代码初始化
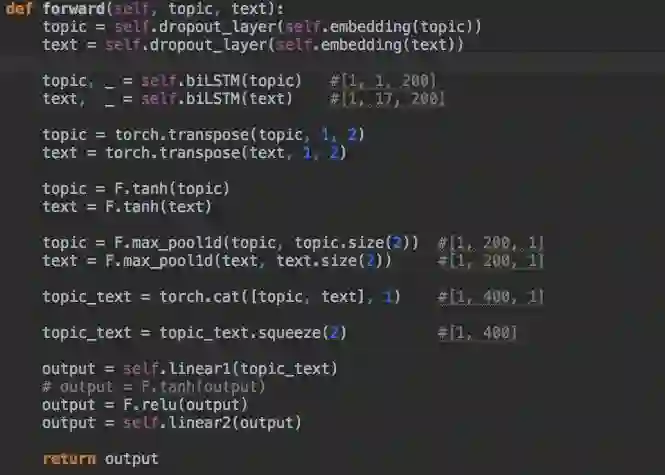
网络数据流动
1.词向量维度,embed_size即Word Embedding size,词被映射到的向量空间的大小



4.批处理的大小batch_size,这里表示一批性处理多少训练语料。不同数据量的batch大小不同,batch越大GPU训练速度越快,但是精度可能会降低,所以需要通过调参来决定具体选择的大小为多少。

5.隐藏层的数量hidden_num,数量越大,训练速度越慢,一般很有可能出现过拟合现象。在简单的网络中,一般隐藏层数为1即可,但是也要看看层数为2的效果,不好的话,就用1层隐藏层。所以,这里需要通过调参获得。

6.权重衰退weight_decay,为了防止过拟合,在原本损失函数的基础上,加上L2正则化,而weight_decay就是这个正则化的lambda参数,一般设置为1e-8,所以调参的时候调整是否使用权重衰退即可。

7.修剪梯度clip_grad,为了防止梯度爆炸(gradient explosion)。原理为:损失函数反向传播的时候,使得每个参数都有了梯度gradient,如果所有的梯度平方和sum_sq_gradient大于clip_grad,那么求出缩放因子:
scale_factor = clip_grad / sum_sq _gradient
接着改变每个gradient,使每个gradient都乘scale_factor,达到缩放的效果,使每个梯度的sum_sq_gradient都被限制在clip_grad里,来达到防止梯度爆炸的效果。通常设置为10,那么调参的内容为是否需要clip_grad机制。

8.学习率衰退lr_decay,一般设置为1e-8,公式为:
lr = lr/(1+step*lr_decay)#lr为学习率,step为当前迭代次数
因为一般情况下循环迭代次数越多的时候,学习率的步伐就应该越来越小,这样才能慢慢接近函数的极值点,。但是有时候也不一定会有效,所以这里需要通过调参来查看是否需要开启lr_decay。

9.外部词向量,即提前提前训练好的词向量,这里指word2vec。因为以前自然语言处理用的是one-hot方法进行对每个词进行编码向量化的,维度为1*字典大小,就一位是1其余位都为0,但是这样在数据量大的情况下会让计算机达到难以计算困难的情况,而且每个词都是独立存在的,之间没有计算相似度的可能性。所以Word2vec在2012年被Google提出来,目的是将文本生成词向量模型,其中包括两个模型,分别是CBOW(continous bag of words)和Skip-Gram。这两个模型分别从两个不同的角度建立词向量模型。其中CBOW是通过一个或多个单词的上下文来对这个词进行预测,而这里用的正是CBOW方法训练的词向量。

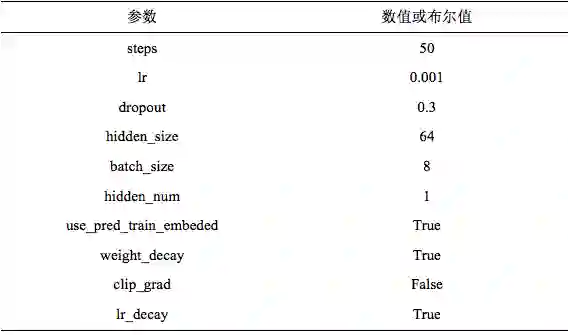
所以最终选择的参数为
测试流程
(1) 从键盘获取post,response的文本。
(2) 然后用jieba分词器进行分词。
(3) 通过word字典将文本转换成数字序列。
(4) 使用上述最佳的模型model。
(5) 将数字化的post,response输入到model里。
(6) 得到每个种类的得分。
(7) 然后找出最大的得分的位置。
(8) 通过label字典,得到对应的立场文字描述即可。
伪代码为

测试样例

在使用外部词向量的时候,人工加入的两种标签在外部向量中是没有的,这里只能用unk表示。因为数据量太小,不能用自己的这个数据来训练词向量。
本文的精确度很低,感觉可以用attention机制等方法来提高F1值。


推荐阅读
基础 | TreeLSTM Sentiment Classification
原创 | Simple Recurrent Unit For Sentence Classification
原创 | Attention Modeling for Targeted Sentiment
 欢迎关注交流
欢迎关注交流




