经历6年时间,在各团队的努力下,阿里巴巴集团大规模推荐稀疏模型训练/预测引擎DeepRec正式对外开源,助力开发者提升稀疏模型训练性能和效果。
DeepRec(PAI-TF)是阿里巴巴集团统一的大规模稀疏模型训练/预测引擎,广泛应用于淘宝、天猫、阿里妈妈、高德、淘特、AliExpress、Lazada等,支持了淘宝搜索、推荐、广告等核心业务,支撑着千亿特征、万亿样本的超大规模稀疏训练。
DeepRec在分布式、图优化、算子、Runtime等方面对稀疏模型进行了深度性能优化,同时提供了稀疏场景下特有的Embedding相关功能。
DeepRec项目从2016年开发至今,由阿里巴巴集团内AOP团队、XDL团队、PAI团队、RTP团队以及蚂蚁集团AIInfra团队共建,并且得到了淘宝推荐算法等多个业务算法团队的支持。DeepRec的研发也得到了Intel CESG软件团队、Optane团队和PSU团队,NVIDIA GPU计算专家团队及Merlin HughCTR团队的支持。
开源地址:
https://github.com/alibaba/DeepRec
用户手册:https://deeprec.rtfd.io
在TensorFlow引擎上支持大规模稀疏特征,业界有多种实现方式,其中最常见的方式是借鉴了ParameterServer的架构实现,在TensorFlow之外独立实现了一套ParameterServer和相关的优化器,同时在TensorFlow内部通过bridge的方式桥接了两个模块。这个做法有一定的好处,比如PS的实现会比较灵活,但也存在一些局限性。
DeepRec采取了另一种架构设计方式,遵循“视整个训练引擎为一个系统整体”的架构设计原则。TensorFlow是一个基于Graph的静态图训练引擎,在其架构上有相应的分层,比如最上层的API层、中间的图优化层和最下层的算子层。TensorFlow通过这三层的设计去支撑上层不同Workload的业务需求和性能优化需求。
DeepRec也坚持了这一设计原则,基于存储/计算解耦的设计原则在Graph层面引入EmbeddingVariable功能;基于Graph的特点实现了通信的算子融合。通过这样的设计原则,DeepRec可以支持用户在单机、分布式场景下使用同一个优化器的实现和同一套EmbeddingVariable的实现;同时在Graph层面引入多种优化能力,从而做到独立模块设计所做不到的联合优化设计。
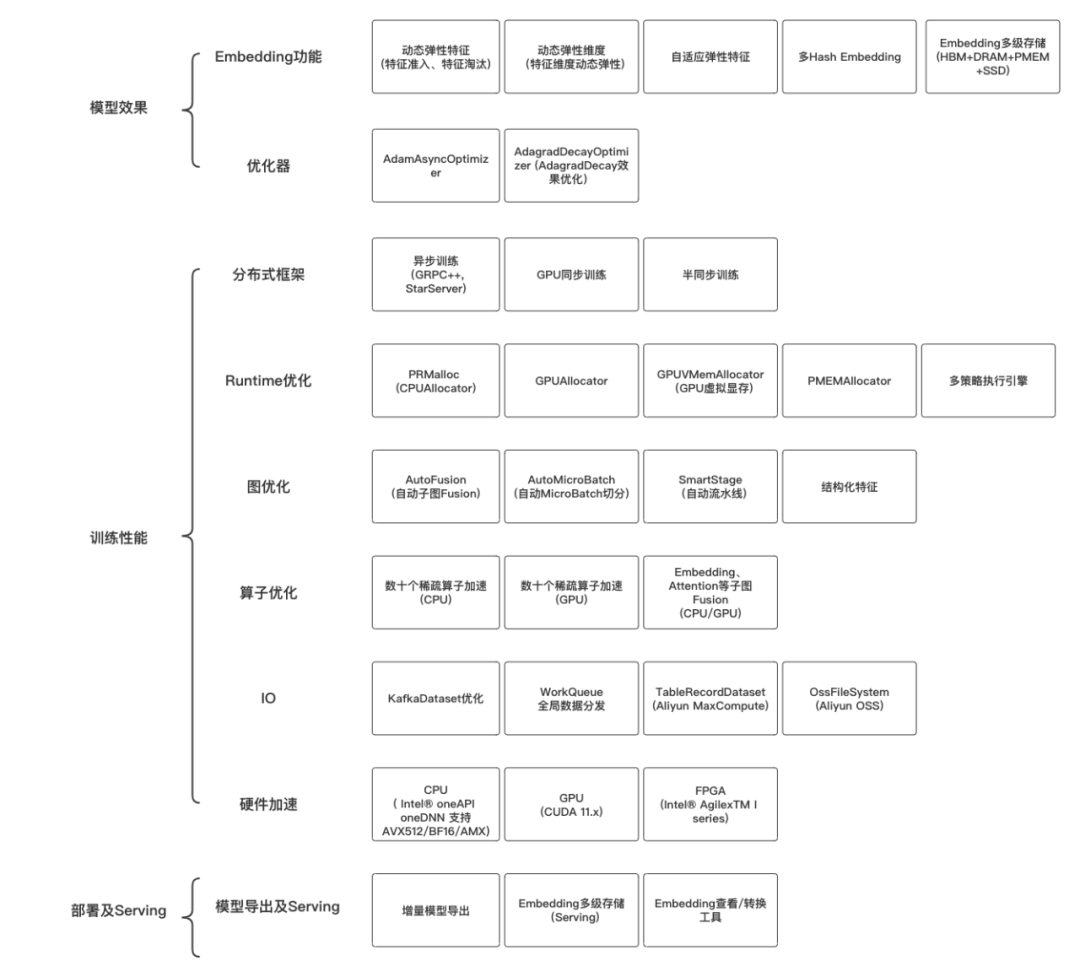
DeepRec是基于TensorFlow1.15、Intel-TF、NV-TF构建的稀疏模型训练/预测引擎,针对稀疏模型场景进行了定制深度优化,主要包含以下三类功能优化:
![]()
DeepRec提供了丰富的稀疏功能支持,提高模型效果的同时降低稀疏模型的大小,并且优化超大规模下Optimizer的效果。下面简单介绍Embedding及Optimizer几个有特色的工作:
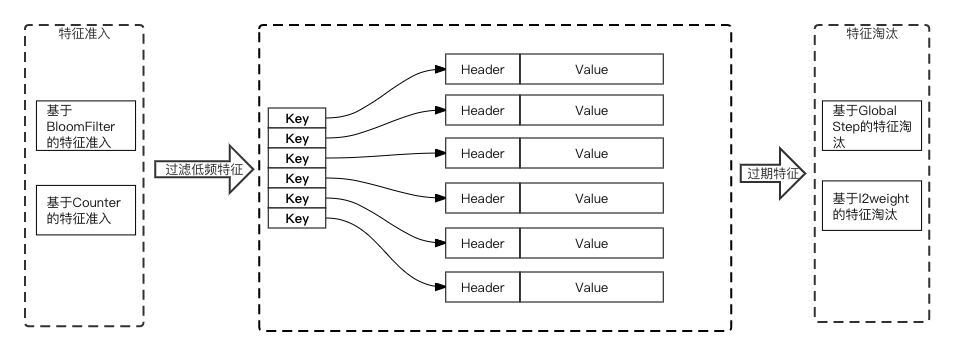
1)解决了静态Shape Variable的vocabulary_size难以预估、特征冲突、内存及IO冗余等问题,并且在DeepRec中提供了丰富的EmbeddingVariable的进阶功能,包括不同的特征准入方式、支持不同的特征淘汰策略等,能够明显提高稀疏模型的效果。
![]()
2)在访问效率上,为了达到更优化的性能和更低的内存占用,EmbeddingVariable的底层HashTable实现了无锁化设计,并且进行了精细的内存布局优化,优化了HashTable的访问频次,使得在训练过程中前后向只需访问一次HashTable。
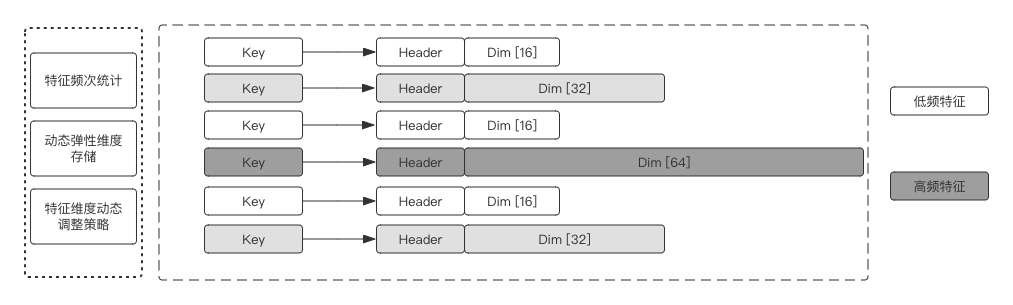
在典型的稀疏场景中,同类特征的出现频次往往极度不均匀。通常情况下,同一个特征列的特征都被设置成统一维度,如果Embedding维度过高,低频特征容易过拟合,而且会额外耗费大量内存;如果维度设置过低,高频部征特征可能会由于表达不够而影响效果。
Dynamic Dimension Embedding Variable提供了同一特征列的不同特征值,根据特征的冷热自动配置不同的特征维度,高频特征可以配置更高维度增强表达能力,而低频特征因为给定低维度embedding缓解了过拟合的问题,而且可以极大程度节省内存(低频长尾特征的数量占据绝对优势)。
![]()
当使用动态弹性特征功能时,低频特征存在过拟合问题。EmbeddingVariable中所有的特征都从initializer设定的初始值(一般设为0)开始学起,对于一些出现频次从低到高的特征,也需要逐渐学习到一个较好的状态,不能共享别的特征的学习结果。AdaptiveEmbedding功能使用静态Shape Variable和动态EmbeddingVariable共同存储稀疏特征,对于新加入的特征存于有冲突的Variable,对于出现频率较高的特征存于无冲突的EmbeddingVariable,特征迁移到EmbeddingVaraible可以复用在有冲突的静态Shape Variable的学习结果。
![]()
为支持超大规模训练而提出的一种改进版Adagrad优化器。当模型训练的样本量大,同时持续增量训练较长时间时,Adagrad优化器的梯度会趋近于0,导致新增训练的数据无法对模型产生影响。已有的累积打折的方案虽然可以解决梯度趋近0的问题,但也会带来模型效果变差的问题(通过iteration打折策略无法反映实际的业务场景特点)。Adagrad Decay Optimizer基于周期打折的策略,同一个周期内的样本相同的打折力度,兼顾数据的无限累积和样本顺序对模型的影响。
此外,DeepRec还提供Multi-HashEmbedding、AdamAsyncOptimizer等功能,在内存占用、性能、模型效果等方面为业务带来实际的帮助。
DeepRec针对稀疏模型场景在分布式、图优化、算子、Runtime等方面进行了深度性能优化。其中,DeepRec对不同的分布式策略进行了深度的优化,包括异步训练、同步训练、半同步训练等,其中GPU同步训练支持HybridBackend以及NVIDIA HugeCTR-SOK。DeepRec提供了丰富的针对稀疏模型训练的图优化功能,包括自动流水线SmartStage、结构化特征、自动图Fusion等等。DeepRec中优化了稀疏模型中数十个常见算子,并且提供了包括Embedding、Attention等通用子图的Fusion算子。DeepRec中CPUAllocator和GPUAllocator能够大大降低内存/显存的使用量并显著加速E2E的训练性能。在线程调度、执行引擎方面针对不同的场景提供了不同的调度引擎策略。下面简单介绍分布式、图优化、Runtime优化方面几个有特色的工作:
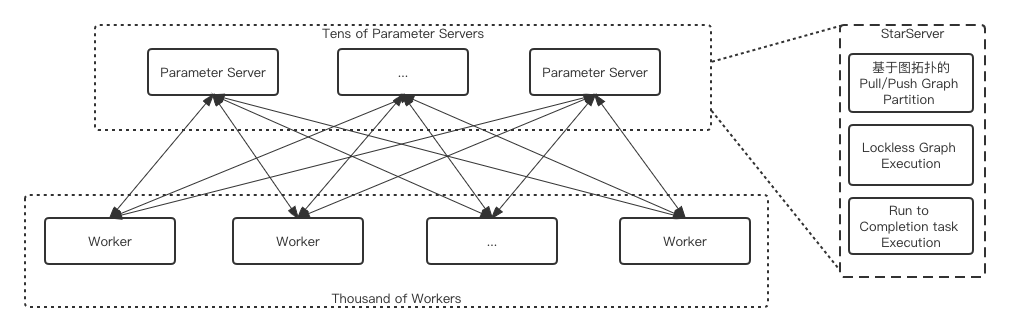
在超大规模任务场景下(几百、上千worker),原生开源框架中的一些问题被暴露出来,譬如低效的线程池调度、关键路径上的锁开销、低效的执行引擎、频繁的小包rpc带来的开销导致ParameterServer在分布式扩展时成为明显的性能瓶颈。StarServer进行了包括图、线程调度、执行引擎以及内存等优化,将原有框架中的send/recv语义修改为pull/push语义,并且在子图划分上支持了该语义,同时实现了ParameterServer端图执行过程中的lockfree,实现了无锁化的执行,大大提高了并发执行子图的效率。对比原生框架,能够提升数倍的训练性能,并且支持3000worker规模的线性分布式扩展。
![]()
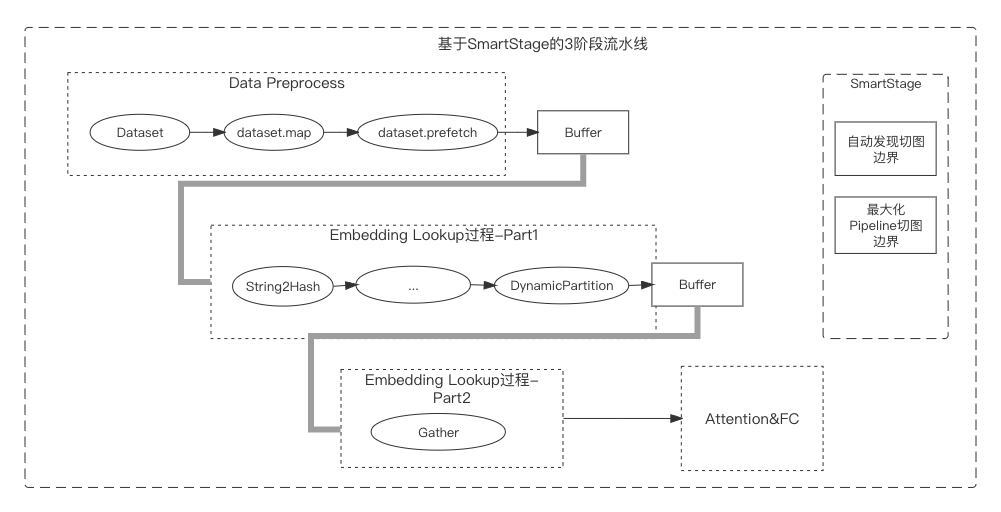
稀疏模型训练通常包含样本数据的读取、Embedding查找、Attention/MLP计算等,样本读取和Embedding查找非计算密集操作,同时并不能高效利用计算资源(CPU、GPU)。原生框架中提供的dataset.prefetch接口可以异步化样本读取操作,但Embedding查找过程中涉及特征补齐、ID化等复杂的过程,这些过程无法通过prefetch进行流水线化。SmartStage功能能够自动分析图中异步流水线化的边界并自动插入,可以使并发流水线发挥最大的性能提升。
![]()
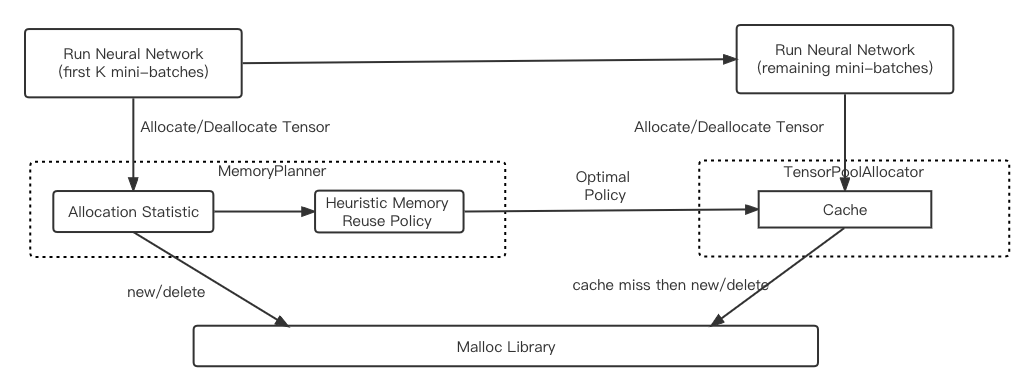
如何做到既高效又有效的使用内存,对于稀疏模型的训练非常关键,稀疏场景模型训练中大块内存分配使用造成大量的minor pagefault,此外,多线程分配效率存在比较严重的并发分配效率问题。针对稀疏模型训练前向、后向,Graph计算模式的相对固定、多轮反复迭代的特点,DeepRec设计了一套针对深度学习任务的内存管理方案,提高内存的使用效率和系统性能。使用DeepRec中提供的PRMalloc能够极大降低训练过程中minor pagefault,提高多线程并发内存分配、释放的效率。
![]()
基于PMDK的底层libpmem库实现的PMEM allocator将从PMEM map出的一块空间分为若干segment,每个segment又分成若干blocks,block是allocator的最小分配单元。分配block的线程为避免线程竞争,缓存一些可用空间,包括一组segment和free list。可用空间中为每种record size(若干个block)维护一个free list和segment。各record size对应的segment只分配该大小的PMEM空间,各record size对应的free list中的所有指针均指向对应record size的空闲空间。此外,为了均衡各thread cache的资源,由一个后台线程周期地将thread cache中的free list移动到后台的pool中,pool中的资源由所有前台线程共享。实验证明,基于持久内存实现的内存分配器在大模型的训练性能方面与基于DRAM的训练性能差别很小,但是TCO会有很大的优势。
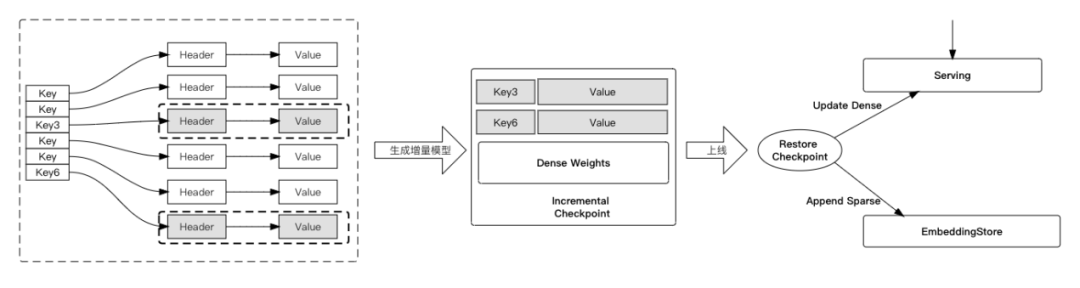
时效性要求高的业务,需要频繁的线上模型更新,频率往往达到分钟级别甚至秒级。对于TB-10TB级别的超大模型而言,分钟级别的模型生成到上线很难完成。此外,超大模型的训练和预测存在着资源浪费、多节点Serving延时加大等问题。DeepRec提供了增量模型产出及加载能力,极大加速了超大模型生成和加载。
![]()
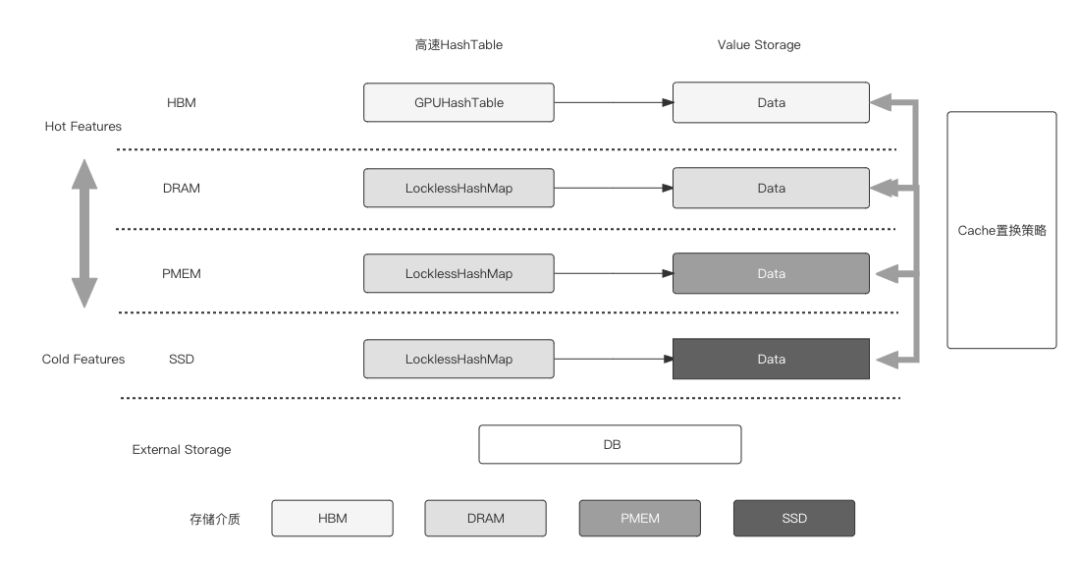
稀疏模型中特征存在冷热倾斜的特性,这产生了某些冷门特征很少被访问和更新导致的内存/显存浪费问题,以及超大模型内存/显存放不下的问题。DeepRec提供了多级混合存储(支持最多四级的混合存储HBM+DRAM+PMEM+SSD)的能力,自动将冷门特征存放到廉价的存储介质中,将热门特征存放到访问更快、更贵的存储介质上,通过多级混合存储,使得单节点可以进行TB-10TB模型的Training和Serving。
![]()
通过多级混合存储,能够更大发挥GPU训练稀疏模型的能力,同时降低由于存储资源限制造成的计算资源浪费,可以使用更少的机器进行相近规模的模型训练,或者使用相同数量的机器进行更大规模的训练。多级混合存储也能使得单机进行超大模型预测时避免分布式Serving带来的latency增大问题,提高大模型的预测性能的同时降低成本。多级混合存储功能也拥有自动发现特征的访问特性,基于高效的热度统计策略,将热度高的特征放置到快速的存储介质中,将低频的特征offload到低速存储介质中,再通过异步方式驱动特征在多个介质之间移动。
开源深度学习框架都不能很好地支持稀疏场景中对于稀疏Embedding功能的需求、模型训练性能需求、部署迭代和线上服务的需求。DeepRec经过阿里巴巴集团搜索、推荐、广告等核心业务场景及公有云上各种业务场景的打磨,能够支持不同类型的稀疏场景训练效果和性能需求。
阿里巴巴希望通过建立开源社区,和外部开发者开展广泛合作,进一步推动稀疏
模型训练/预测框架的发展,为不同业务场景中的搜推广模型训练和预测带来业务效果和性能提升。
今天DeepRec的开源只是我们迈出的一小步。我们非常期待得到您的反馈。最后,如果你对DeepRec有相应的兴趣,你也可以来转转,为我们的框架贡献一点你的代码和意见,这将是我们莫大的荣幸。
推荐阅读
由于公众号试行乱序推送,您可能不再准时收到机器学习与推荐算法的推送。为了第一时间收到本号的干货内容, 请将本号设为星标,以及常点文末右下角的“在看”。