阿里 BladeDISC 深度学习编译器正式开源

一 导读
二 BladeDISC是什么
1 主要特性
-
多款前端框架支持:TensorFlow,PyTorch -
多后端硬件支持:CUDA,ROCM,x86
-
完备支持动态shape语义编译 -
支持推理及训练
-
轻量化API,对用户通用透明 -
支持插件模式嵌入宿主框架运行,以及独立部署模式
三 深度学习编译器的背景
1 AI浪潮与芯片浪潮共同催生——从萌芽之初到蓬勃发展
框架性能优化在模型泛化性方面的需求
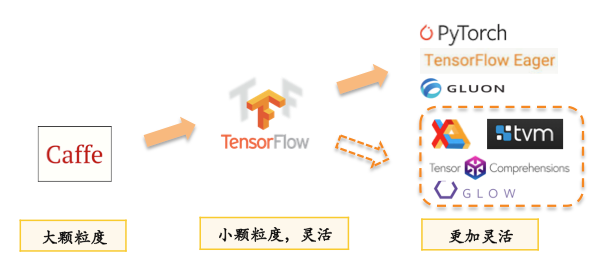
AI框架在硬件泛化性方面的需求
AI系统平台对前端AI框架泛化性方面的需求
2 什么是深度学习编译器
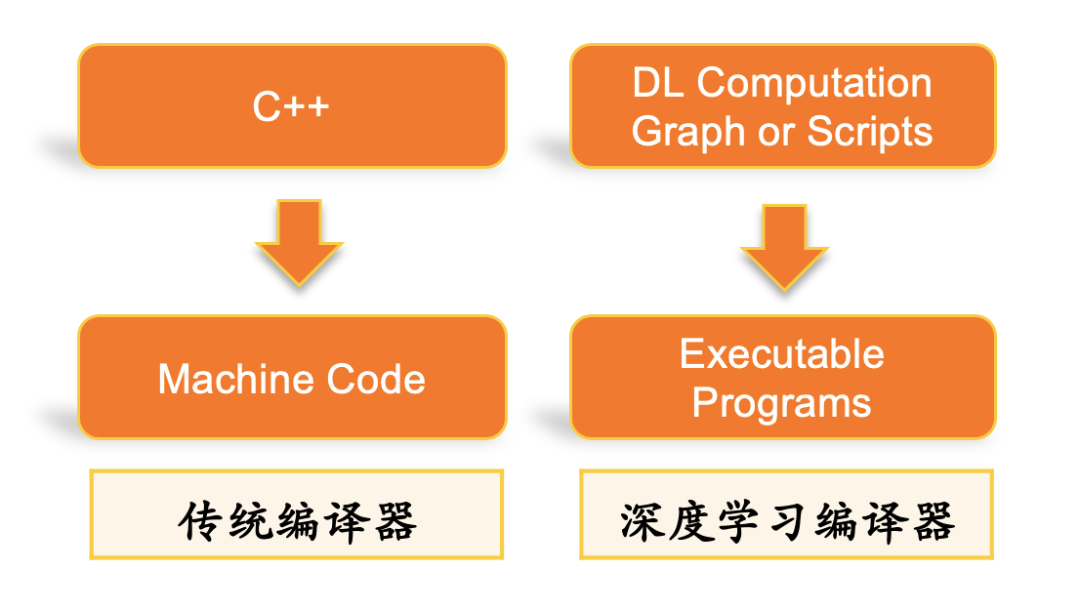
3 距离大规模应用面临的瓶颈问题
易用性
-
与前端框架对接的问题。不同框架对深度学习任务的抽象描述和API接口各有不同,语义和机制上有各自的特点,且作为编译器输入的前端框架的算子类型数量呈开放性状态。如何在不保证所有算子被完整支持的情况下透明化的支持用户的计算图描述,是深度学习编译器能够易于为用户所广泛使用的重要因素之一。
-
动态shape问题和动态计算图问题。现阶段主流的深度学习编译器主要针对特定的静态shape输入完成编译,此外对包含control flow语义的动态计算图只能提供有限的支持或者完全不能够支持。而AI的应用场景却恰恰存在大量这一类的任务需求。这时只能人工将计算图改写为静态或者半静态的计算图,或者想办法将适合编译器的部分子图提取出来交给编译器。这无疑加重了应用深度学习编译器时的工程负担。更严重的问题是,很多任务类型并不能通过人工的改写来静态化,这导致这些情况下编译器完全无法实际应用。
-
编译开销问题。作为性能优化工具的深度学习编译器只有在其编译开销对比带来的性能收益有足够优势的情况下才真正具有实用价值。部分应用场景下对于编译开销的要求较高,例如普通规模的需要几天时间完成训练任务有可能无法接受几个小时的编译开销。对于应用工程师而言,使用编译器的情况下不能快速的完成模型的调试,也增加了开发和部署的难度和负担。
-
对用户透明性问题。部分AI编译器并非完全自动的编译工具,其性能表现比较依赖于用户提供的高层抽象的实现模版。主要是为算子开发工程师提供效率工具,降低用户人工调优各种算子实现的人力成本。但这也对使用者的算子开发经验和对硬件体系结构的熟悉程度提出了比较高的要求。此外,对于新硬件的软件开发者来说,现有的抽象却又常常无法足够描述创新的硬件体系结构上所需要的算子实现。需要对编译器架构足够熟悉的情况下对其进行二次开发甚至架构上的重构,门槛及开发负担仍然很高。
鲁棒性
性能问题
四 BladeDISC的主要技术特点
-
大幅增加编译开销。引入离线编译预热过程,大幅增加推理任务部署过程复杂性;训练迭代速度不稳定甚至整体训练时间负优化。
-
部分业务场景shape变化范围趋于无穷的,导致编译缓存永远无法收敛,方案不可用。
-
内存显存占用的增加。编译缓存额外占用的内存显存,经常导致实际部署环境下的内存/显存OOM,直接阻碍业务的实际落地。
-
人工padding为静态shape等缓解性方案对用户不友好,大幅降低应用的通用性和透明性,影响迭代效率。
五 关键技术
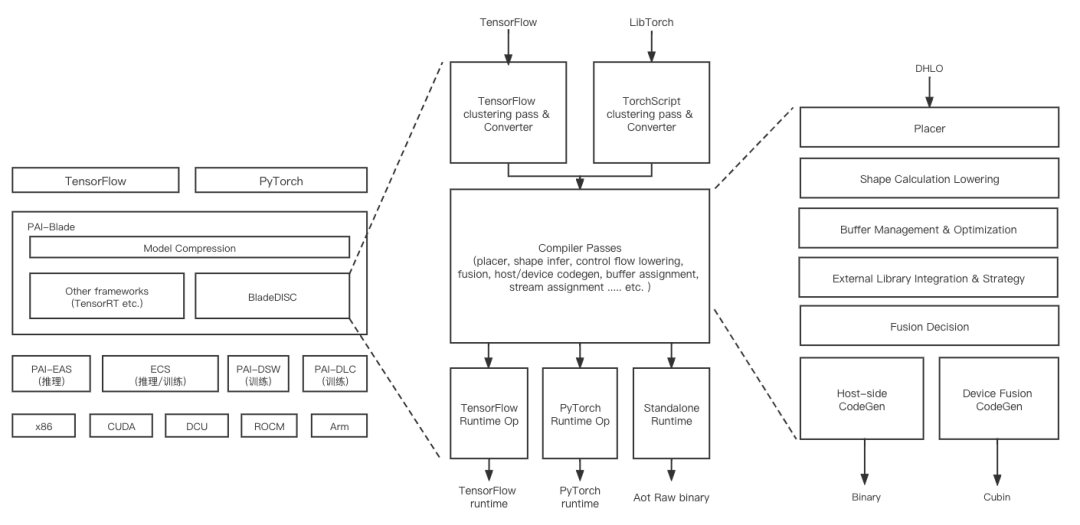
1 MLIR基础架构
2 动态shape编译
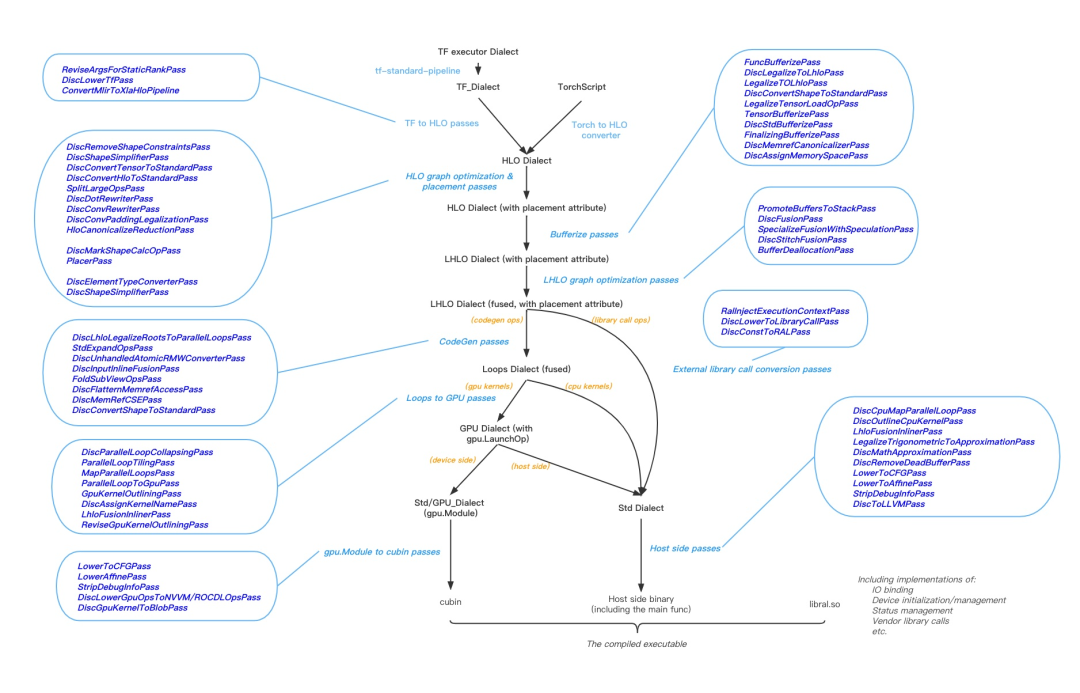
图层IR设计
运行时Shape计算、存储管理和Kernel调度
动态shape下的性能问题
大颗粒度算子融合
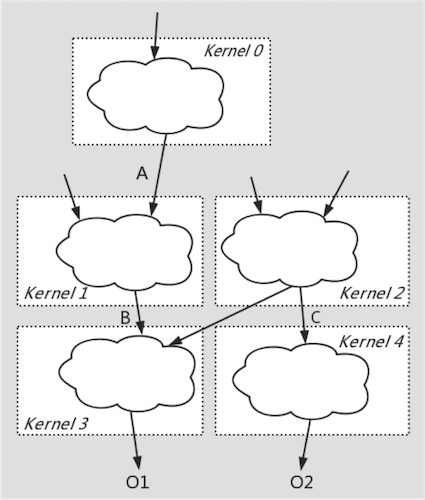
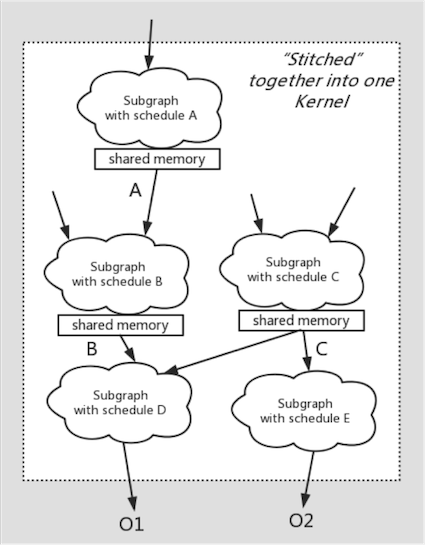
3 多前端框架支持
4 运行时环境适配
-
全图编译,独立运行。当整个计算图都支持编译时,RAL提供了一套简易的runtime以及在此之上RAL Driver的实现,使得compiler编译出来结果可以脱离框架直接运行,减少框架overhead。
-
TF中子图编译运行。
-
Pytorch中子图编译运行。
六 应用场景
-
应对动态shape业务完备的动态shape语义支持
-
基于compiler based的技术路径的模型泛化性在非标准模型上的性能优势
-
更为灵活的部署模式选择,以插件形式支持前端框架的透明性优势
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
七 开源生态——构想和未来
-
BladeDISC发源于阿里云计算平台团队的业务需求,在开发过程中与MLIR/MHLO/IREE等社区同行之间的讨论和交流给了我们很好的输入和借鉴。在我们自身随着业务需求的迭代逐渐完善的同时,也希望能够开源给社区,在目前整个AI编译器领域实验性项目居多,偏实用性强的产品偏少,且不同技术栈之间的工作相对碎片化的情况下,希望能够将自身的经验和理解也同样回馈给社区,希望和深度学习编译器的开发者和AI System的从业者之间有更多更好的交流和共建,为这个行业贡献我们的技术力量。
-
我们希望能够借助开源的工作,收到更多真实业务场景下的用户反馈,以帮助我们持续完善和迭代,并为后续的工作投入方向提供输入。
-
持续的鲁棒性及性能改进
-
x86后端补齐计算密集型算子的支持,端到端完整开源x86后端的支持
-
GPGPU上基于Stitching的大颗粒度自动代码生成
-
AMD rocm GPU后端的支持
-
PyTorch训练场景的支持
-
更多新硬件体系结构的支持和适配,以及新硬件体系结构下软硬件协同方法学的沉淀
-
计算密集型算子自动代码生成和动态shape语义下全局layout优化的探索
-
稀疏子图的优化探索
-
动态shape语义下运行时调度策略、内存/显存优化等方面的探索
-
模型压缩与编译优化联合的技术探索
-
图神经网络等更多AI作业类型的支持和优化等
开源地址:
参考文献
-
"DISC: A Dynamic Shape Compiler for Machine Learning Workloads", Kai Zhu, Wenyi Zhao, Zhen Zheng, Tianyou Guo, Pengzhan Zhao, Feiwen Zhu, Junjie Bai, Jun Yang, Xiaoyong Liu, Lansong Diao, Wei Lin -
Presentations on MLIR Developers' Weekly Conference: 1, 2
-
"AStitch: Enabling A New Multi-Dimensional Optimization Space for Memory-Intensive ML Training and Inference on Modern SIMT Architectures", Zhen Zheng, Xuanda Yang, Pengzhan Zhao, Guoping Long, Kai Zhu, Feiwen Zhu, Wenyi Zhao, Xiaoyong Liu, Jun Yang, Jidong Zhai, Shuaiwen Leon Song, and Wei Lin. The 27th ACM International Conference on Architectural Support for Programming Languages and Operating Systems (ASPLOS), 2022. [to appear] -
"FusionStitching: Boosting Memory Intensive Computations for Deep Learning Workloads", Zhen Zheng, Pengzhan Zhao, Guoping Long, Feiwen Zhu, Kai Zhu, Wenyi Zhao, Lansong Diao, Jun Yang, and Wei Lin. arXiv preprint
Java面试疑难点串讲1:面试技巧及语言基础
登录查看更多
相关内容
专知会员服务
54+阅读 · 2020年2月4日
Arxiv
0+阅读 · 2022年4月15日



相关VIP内容
专知会员服务
54+阅读 · 2020年2月4日
相关资讯
相关论文
Arxiv
0+阅读 · 2022年4月15日