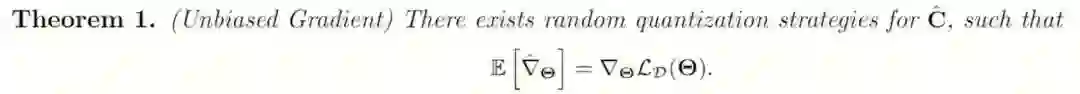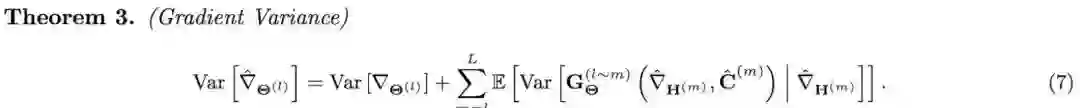计算机视觉研究院专栏
作者:Edison_G
随着超大规模深度学习模型逐渐成为 AI 的趋势,如何在有限的 GPU 内存下训练这些模型成为了一个难题。
本篇文章转自于“机器之心”
本文将介绍来自加州伯克利大学的 ActNN,一个基于 PyTorch 的激活压缩训练框架。在同样的内存限制下,ActNN 通过使用 2 bit 激活压缩,可以将 batch size 扩大 6-14 倍,将模型尺寸或者输入图片扩大 6-10 倍。ActNN 相关论文已被 ICML 2021 接收为 Long Talk,代码开源于 github。
论文
https://arxiv.org/abs/2104.14129
代码
https://github.com/ucbrise/actnn
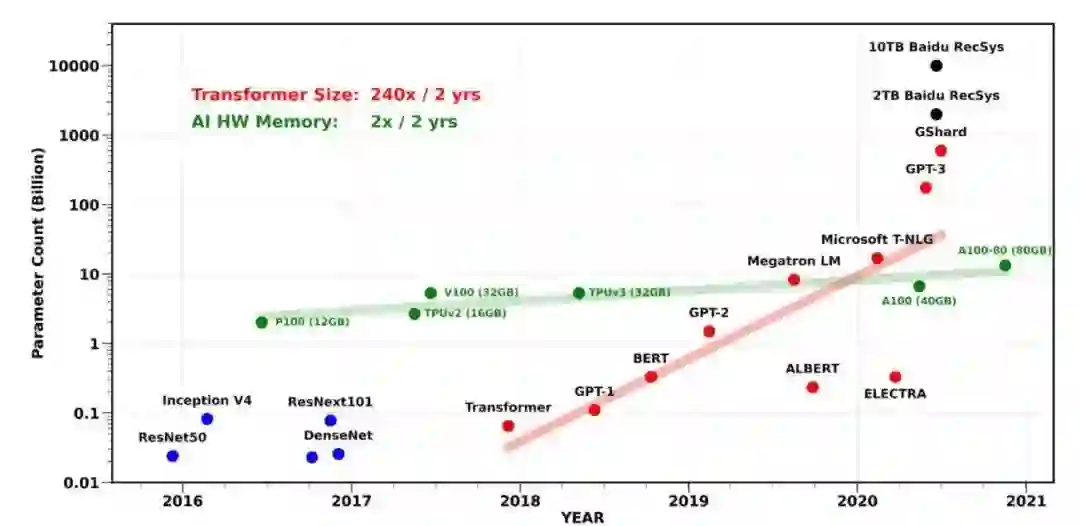
从 AlexNet,ResNet 到 GPT-3,深度学习性能的突破都离不开模型规模的疯狂增长。大模型有更好的性能已经成为业界的共识。过去几年,不仅训练一个最先进模型需要的算力在指数增长,训练一个最先进模型需要的内存也在指数增长。如下图所示,大型 Transformer 模型的参数量以每两年翻 240 倍的速度指数增长。但是,单个 GPU 的内存却只以每两年翻 2 倍的速度在缓慢增长。另外,在训练模型时,不光要存储模型参数,还要存储中间结果激活值和优化器状态,所需要的内存更多。如何在有限的 GPU 内存下训练这些大规模模型成为了挑战。
![]()
source:Gholami A, Yao Z, Kim S, Mahoney MW, Keutzer K. AI and Memory Wall. RiseLab Medium Blog Post, University of California Berkeley
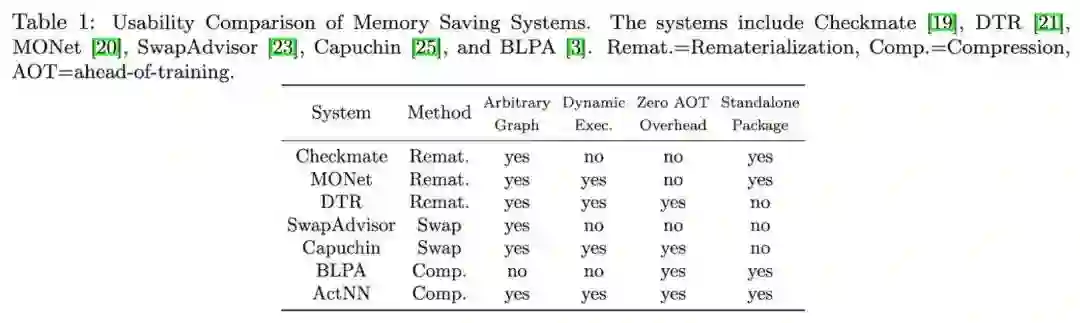
目前,节省训练内存的方法主要有三类:1. 重计算(Gradient checkpointing/Rematerialization) 2. 使用 CPU 内存进行交换 (swapping) 和 3. 使用分布式训练将 Tensor 分散存储在多个 GPU 上。这三类方法互相不冲突,可以结合使用。大部分机器学习框架对这些方法都提供了一些支持,也有不少相关的论文。但是,想要高效、自动化地实现这些策略并不容易。与已有方法不同,我们提出了 ActNN,一个新的基于压缩的内存节省框架。在提供理论证明的同时,我们基于 PyTorch 提供了一个高效易用的实现。Table.1 比较了 ActNN 和已有的一些内存节省系统。ActNN 支持 PyTorch 的动态图执行模式,并且不需要预先进行复杂的策略搜索。ActNN 作为一个独立的 Python 库,使用时 import 即可,不需要修改或重新编译 PyTorch。与已有的工作相比,ActNN 灵活且易于使用。同时,ActNN 在理论上也可以和已有的技术相互叠加。
![]() ActNN:2 bit 激活压缩训练
ActNN:2 bit 激活压缩训练
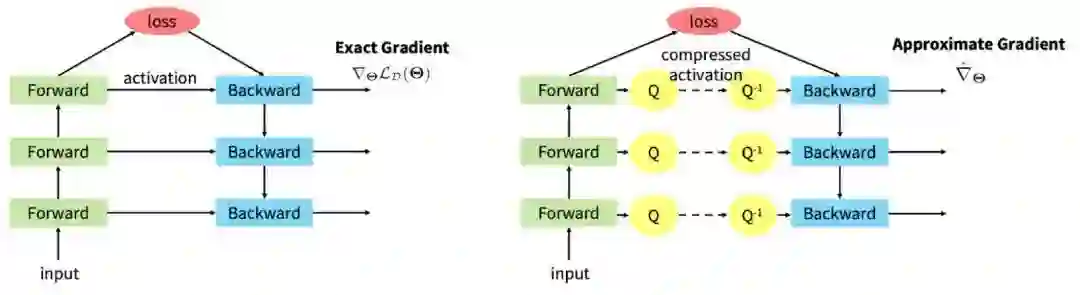
在训练一个多层神经网络时,在前向传播中,每一层的中间结果都要被存下来用于计算反向传播的梯度。这些中间结果,又被叫做「激活值」(activation),实际上占据了大部分的内存消耗,尤其是在 batch size 较大或者输入图片较大的时候。ActNN 的原理是就是压缩这些激活值来节省内存。如下图所示,左图表示的是普通的前向传播和反向传播,前向传播时会存下所有层的 fp32 激活值用于反向传播,内存使用在计算 loss 的时候达到峰值。右图表示的是 ActNN 的训练方法:在前向传播时,通过一个压缩操作 Q 将激活值压缩后再存储;反向传播时,通过解压缩操作 Q^-1 将激活值解压再计算梯度。
如果只是为了节省内存,这里可以使用各种压缩算法,但是大部分现有的压缩算法并不能高效地运行在 GPU 上,会引入较大的开销。ActNN 选择了使用 2-bit 量化作为这里的压缩算法。量化操作的代价较小,而且有一些好的数学性质允许我们使用有损压缩达到较大的压缩比。
把 fp32 浮点数量化为 2-bit 整数是一个有损压缩,会引入一些误差。论文从理论上分析了量化引入的误差是如何影响训练的收敛性的。
第一,存在一个随机化的量化策略,使得使用有损量化压缩后,估计出的有损梯度是原梯度的一个无偏估计。
在这一条件下,我们套用已有的随机梯度下降收敛性定理,得出最后收敛时的误差会被梯度的方差所限制。
第二,我们推导出了使用量化压缩之后,随机梯度下降计算出的梯度的方差。
等号右边的第一项是随机梯度下降在 minibatch 采样时产生的方差,等号右边的第二项是有损压缩额外引入的方差。这条公式显示地刻画了有损压缩带来的影响。注意到,当有损量化压缩带来的方差远小于原来随机梯度下降自带的方差时,ActNN 引入的有损压缩就不会影响训练的收敛性。更多关于公式的推导和可视化参见文末的论文链接。论文对不同的算子(conv2d,batch norm,linear等)都提供了详细的分析。
由上述公式启发,我们提出了一些新的量化技巧用于降低有损压缩引入的额外方差。我们引入了新的量化技巧 ( Per-group Quantization,Fine-Grained Mixed-Precision,Runtime Adaptation) 来利用梯度在不同样本,不同纬度,不同层之间的异构特性。最后的压缩算法会分配更多的 bit 给更重要的激活值。平均每个浮点数分配到 2 bit。
在具体实现压缩算法时,还有很多可以调节的参数。这里产生了一个内存节省和训练速度的取舍。一般来说,使用更复杂的压缩算法可以节省更多的内存,但是也会引入更多额外的开销,使训练速度变慢。为了给用户较大的灵活性,ActNN 提供了 5 个优化等级 L1-L5 供用户选择。低的优化等级节省的内存较少,但是运行速度快。高的优化等级节省的内存多,但是运行也更慢。在最高优化等级 L5 下,ActNN 会结合一个简单的内存交换策略,将压缩后的激活值移到 CPU 内存上,进一步节省内存。
要在 PyTorch 实现 ActNN 算法非常简单。对于一个 PyTorch nn Module,我们只需要在其 forward 函数里加入量化压缩,在其 backward 函数里加入解压缩操作。所有的计算还是在 fp32 下进行,与原来一样,伪代码如下图所示。
ActNN 为大部分常用的 PyTorch nn.Module 实现了使用量化压缩的版本。用户只需将模型里的所有 PyTorch nn.Module 替换成 ActNN 对应的 Module (如把 nn.Conv2d 替换成 actnn.Conv2d),即可节省内存,不需要更改其他代码。ActNN 同时也提供了一个 wrapper 实现一行代码自动替换。
![]()
因为 ActNN 进行的是有损压缩,所以最重要的一点是先验证 ActNN 是否会影响模型的精度。下图是使用 ActNN 在 ImageNet 上训练 ResNet-50 的结果。FP 代表普通的 fp32 训练, BLPA 是来自 NeurIPS 2019 的一个相关工作。可以看到,在 ActNN 的 2-bit 压缩模式下,模型几乎没有损失精度。在更极限的 1.25 bit 的情况下,ActNN 也能收敛,只不过会损失一些精度。而之前的工作 BLPA 在小于 4 bit 的情况就下无法收敛。
我们还在图像分割,物体检测,以及自监督学习等多个任务上进行了实验。ActNN 都能在 2-bit 压缩模式下达到和普通 fp32 几乎一样的结果。在部分任务上,因为 ActNN 可以使用更大的 batch size,甚至可以取得更好的测试结果。详细的实验结果和训练记录参见文末的论文与 github 链接。
之后,我们对比了 ActNN 与普通 fp32 训练的实际内存使用情况。如下表所示,ActNN 可以将激活值占用的内存压缩 12 倍,将训练使用的总内存压缩 4 - 7 倍。这一实际内存压缩效果符合理论推导。为什么激活值压缩倍率是 12 而不是 32 bit / 2 bit = 16?主要是因为 ActNN 不能使用 inplace 的 ReLU,以及需要存储少量额外的 min 和 scale 用于解压缩。
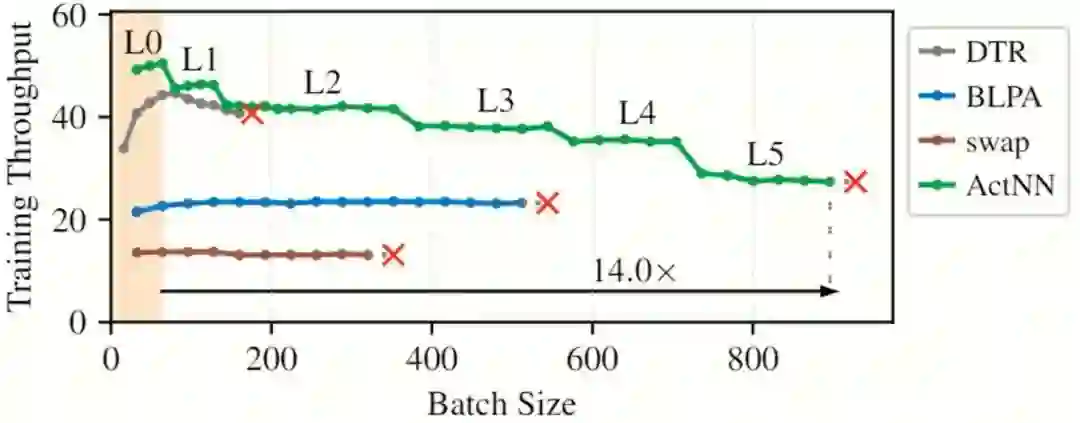
最后,我们测试了 ActNN 的训练速度。因为 ActNN 在训练过程中进行了压缩,这些压缩在节省内存的同时也会引入额外的计算开销。一般来说,省得内存越多,进入的额外开销就越多,训练也就越慢。我们在 NVIDIA T4 (16 GB 内存) 上对比了 ActNN 和已有内存节省系统的训练速度。如下图所示,DTR (ICLR 2020),BLPA (NeurIPS 2019)和 swap 分别是基于重计算,压缩和内存交换的三种方法,红叉代表 Out-of-memory。y 轴是训练吞吐量 (images per second),越高越好。绿色的曲线是综合 ActNN 在不同优化等级下的最优结果。可以看到,ActNN 不仅能开到最大的 batch size(即最省内存),同时在所有 batch size 下都比 baseline 的训练速度更快。
我们还对更多的网络进行了测试。在同样的内存限制下,
ActNN 可以将 batch size 扩大 6-14 倍,将模型尺寸或者输入图片扩大 6-10 倍
。详细的实验设置和结果参见文末的论文链接。
import actnn
model = actnn.QModel(model)
ActNN 提供了一个自动模型转换封装。只需在训练脚本里插入两行代码,即可将普通的 PyTorch 模型转换为使用 ActNN 的模型。同时,ActNN 也提供了更高级的 API 支持定制化的使用场景。
更多的例子参见 github 链接。我们提供了在图像识别、图像分割、物体检测,以及自监督学习等多个任务上使用 actnn 的完整例子和训练记录,欢迎试用!
© THE END
计算机视觉研究院主要涉及深度学习领域,主要致力于人脸检测、人脸识别,多目标检测、目标跟踪、图像分割等研究方向。研究院接下来会不断分享最新的论文算法新框架,我们这次改革不同点就是,我们要着重”
研究
“。之后我们会针对相应领域分享实践过程,让大家真正体会
摆脱理论
的真实场景,培养爱动手编程爱动脑思考的习惯!
公众号ID|ComputerVisionGzq
学习群|扫码在主页获取加入方式