学界 | 百度AAAI 2018录用论文:基于注意力机制的多通道机器翻译模型
AI 科技评论消息,近日,百度机器翻译团队在 arxiv.org 上发布了最新研究成果「Multi-channel Encoder for Neural Machine Translation」,这一论文已被 AAAI 2018 录用。
论文链接:https://arxiv.org/abs/1712.02109
以下内容是 AI 科技评论根据论文内容进行的部分编译。
摘要:文章提出一种多通道的基于注意力机制(Attention-based)的编码器(MCE,Multi-channel Encoder)。MCE 在基于 RNN 编码器中加入了隐层状态,使得其具有两大优势:1)改善了原编码过程中在字嵌入(Word embedding)时合成处理的效果;2)针对更加复杂的合成场景,对神经图灵机(NTM,Neural Turing Machine)的外存使用做了特别的优化设计。在中英翻译方面,相较开源的 DL4MT 系统有 6.25 BLEU 的提升;在 WMT14 英法翻译数据集上 BLEU=38.8,领先于目前最新算法。
基于注意力的神经翻译系统
目前,很多研究工作者提出了许多基于注意力的神经翻译系统(NMT,Neural Machine Translation)的改进方法,其中效果最优的是基于注意力架构的编解码系统。图 1. 提供了基于注意力 NMT 模型的结构原理,共包括三个部分:编码、解码层,及中间级联的引入注意力机制的结构。
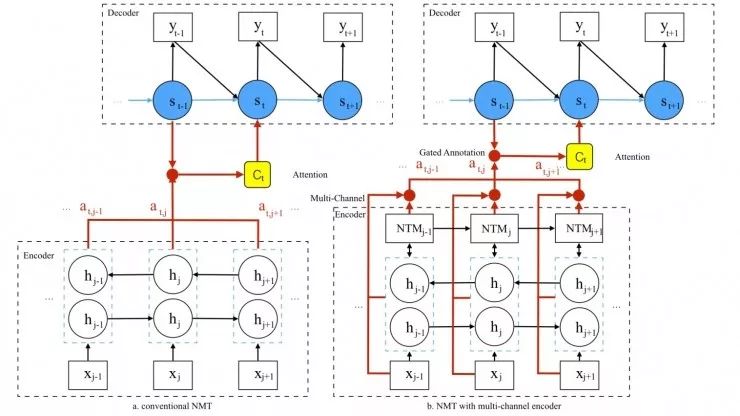
图 1. 基于注意力的 NMT 模型。左侧是基于卷积的 NMT,右侧是文章提出的多通道 NMT。
NMT 系统首先将所有完成分割的符号转换到一个序列中,即:字嵌入过程(Word Embedding)。在这一过程中,每个字符都要进行单独处理,最后生成字嵌入后的原序列。图中在字嵌入层的上方,NMT 使用双向循环神经网络(biRNN) 经训练得到整个原序列的表示。在编码层与解码层之间,加入注意力机制融合输入序列的全部的时间步(time step),并将注意力放到解码层的当前时间步上。在生成目标词的过程中,控制器会整合:上一生成词、当前隐层状态、由注意力机制计算出的上下文信息这三项,从而确定最终的目标词。
多通道编码
RNN 编码层对基于注意力模型的 NMT 而言是十分重要的,然而传统 RNN 实现多层信息整合是存在一定困难的,而机器翻译越来越需要这种网络结构。因此,这篇文章提出了多通道的注意力机制编码器,其网络如图 1. 右侧所示。该结构增加了一个外部存储辅助 RNN 完成更为复杂的整合学习。此外,RNN 的隐层状态与字嵌入序列共同为编解码层之间的注意力机制生成门控注释。从另一个角度考虑,将字嵌入序列整合输入到注意力机制模型中也可以看作建立了一条短路连接,可以减轻退化问题(He. 等于 2016 年证明,见引文 [1])。这种短路连接在增强网络功能的同时没有引入任何额外参数而且没有引起及计算复杂的提升。
[1] He, K.; Zhang, X.; Ren, S.; and Sun, J. 2016. Deep residual learning for image recognition. In Proceedings of the IEEE conference on computer vision and pattern recognition, 770–778.(https://arxiv.org/abs/1512.03385)
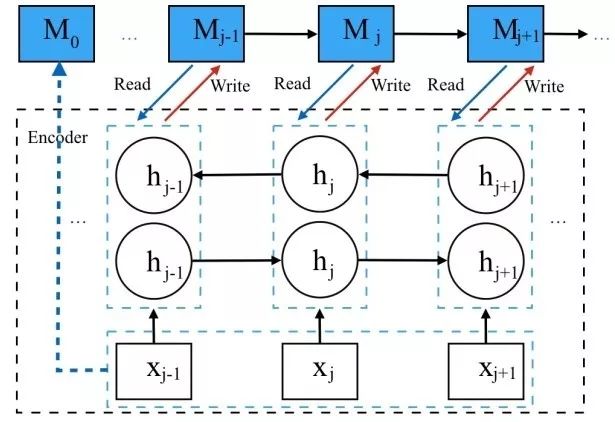
图 2. 多通道注意力机制编码器中,内存读写示意图。
图 2. 中阐述了神经翻译系统的编码层内存读写的详细规则。在每一时间步内,RNN 内状态节点在内存查询上下文信息,内存按照基于注意力机制存储。这一设计中,使用前一状态节点查询并获取上下文信息作为门控循环单元(GRU, gated recurrent unit)的输入状态,以此取代直接将前一状态反馈给 GRU。这一操作保证了控制器在生成当前状态前可以获取更多的上下文信息,可以潜在地帮助 GRU 做出判断。在设计读取内存操作的同时,系统中也设计了写操作。这一设计的目的,据该文百度团队研究工作在描述,是希望 RNN 和 NTM 能够学习不同类型的关联分别通过不同的更新策略。
翻译效果实验验证
1. 汉-英翻译
表 1. 表示汉译英翻译任务的表现情况。该数据在开源系统 DL4MT 下测试以确保其鲁棒性。首先,与 DL4MT 系统相比,文章提出的多通道基于注意力机制的神经网络翻译系统有较大提升:与 DL4MT 相比,文中提出的方法在 BLUE 指标上有 4.94 点的提升。考虑到文中的 RNN 系统是一种基础的基于注意力机制的应用,这一设计可以与目前最新近的技术相结合,比如结合均匀初始化所有参数、给嵌入式矢量增加偏差、将前向 RNN 的输出作为后向 RNN 的输入并且加入动态学习率来训练等,以发挥更大的效果。
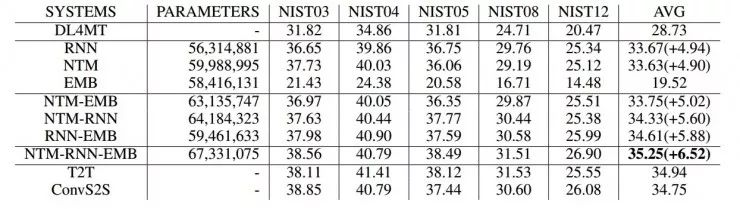
表 1. 不同系统对 NIST 汉译英翻译任务的表现情况。与目前较强的开源系统 DL4MT 相比, 文章提出的模型有较大改进。T2T 和 ConvS2S 是另外两个新出版的开源工具箱,也作为对比试验。值得注意的是,T2T 和 ConvS2S 都是多层深度模型,而文中方法能够达到与之相近的效果。
2. 英-法翻译
表二为英译法表现情况,并将文中提出的 NMT 系统与各种各样的系统进行对比,如深度 RNN 模型、深度 CNN 模型及基于注意力的深度模型。为了实验的公平性,表2列举了这些方法所在文献的结果。在英译法任务中,文中设计的方法在 目前最新的机器翻译系统中,表现很有竞争力,甚至可与深度模型达到相近的效果。此外,与其他 RNN 模型相比,该系统非常具有竞争力,尽管是一种浅层模型。
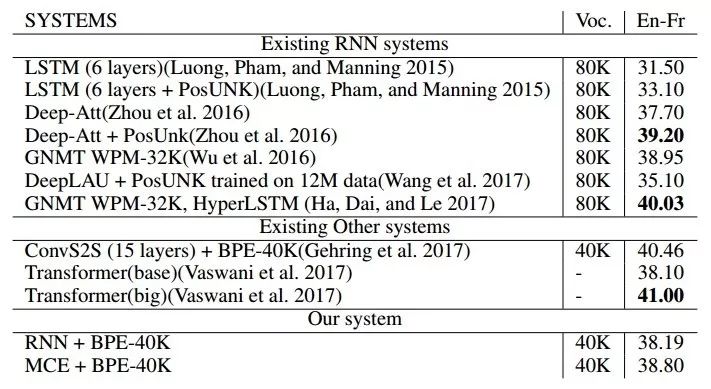
表 2. 文章方法的英译法 BLEU 分数。最下面一栏中 RNN 是文中的基本模型,MCE 是结合了三种编码组件:嵌入字,RNN 隐层状态,以及 NTM 外存。
今年的 AAAI 2018 将于 2 月 2 日 - 2 月 7 日 在美国新奥尔良举行, AI 科技评论也将到现场进行一线报道。如果你也有论文被 AAAI 录用 ,欢迎在后台留下你的联系方式,我们将与您联系,并进行更多交流!
————— 新人福利 —————
关注AI 科技评论,回复 1 获取
【数百 G 神经网络 / AI / 大数据资源,教程,论文】
————— AI 科技评论招人了 —————
AI 科技评论期待你的加入,和我们一起见证未来!
现诚招学术编辑、学术兼职、学术外翻
详情请点击招聘启事
————— 给爱学习的你的福利 —————
上海交通大学博士讲师团队
从算法到实战应用,涵盖CV领域主要知识点;
手把手项目演示
全程提供代码
深度剖析CV研究体系
轻松实战深度学习应用领域!
详细了解请点击阅读原文
▼▼▼

————————————————————




