【AAAI 2018】腾讯 AI Lab 11篇论文解读:图像描述、NMT 模型、图卷积神经网络、DNN优化等

新智元专栏
来源:腾讯AI Lab
【新智元导读】2 月 2 日至 2 月 7 日,AAAI 2018 将在美国新奥尔良举行,新智元将持续为读者带来本届大会的最新干货。在AAAI 2018,腾讯 AI Lab 有 11 篇论文被录用,涉及图像描述、更低计算成本的预测表现、NMT 模型中的特定翻译问题、自适应图卷积神经网络、DNN面对对抗样本的优化问题等,本文带来全部11篇论文的摘要解读。

1. 学习用于图像描述的引导解码(Learning to Guide Decoding for Image Captioning)
图像描述领域近来取得了很多进展,而且已经有一种编码器-解码器框架在这一任务上得到了出色的表现。在本论文中,我们提出了一种编码器-解码器框架的扩展——增加了一个名叫引导网络(guiding network)的组件。这种引导网络会建模输入图像的属性特性,其输出会被用于组成解码器在每个时间步骤的输入。这种引导网络可以插入到当前的编码器-解码器框架中,并且可以以一种端到端的方式训练。因此,该引导向量可以根据来自解码器的信号而自适应地学习得到,使其自身中嵌入来自图像和语言两方面的信息。此外,还能使用判别式监督来进一步提升引导的质量。我们通过在 MS COCO 数据集上的实验验证了我们提出的方法的优势。
2. 发现和区分多义词的多个视觉含义(Discovering and Distinguishing Multiple Visual Senses for Polysemous Words)
为了减少对有标签数据的依赖,利用网络图像学习视觉分类器的研究工作一直在不断增多。限制他们的表现的一个问题是多义词问题。为了解决这个问题,我们在本论文中提出了一种全新的框架——该框架可通过允许搜索结果中特定于含义的多样性来解决该问题。具体而言,我们先发现一个用于检索特定于含义的图像的可能语义含义列表。然后,我们使用检索到的图像来合并视觉上相似的含义并剪枝掉噪声。最后,我们为每个被选中的语义含义训练一个视觉分类器并使用学习到的特定于含义的分类器来区分多个视觉含义。我们在按含义给图像分类和重新排序搜索结果上进行了大量实验,结果表明了我们提出的方法的优越性。
论文地址:bmc.uestc.edu.cn/~fshen/AAAI18.pdf
3. 使用稳定化Barzilai-Borwein 步长的随机非凸序数嵌入(Stochastic Non-convex Ordinal Embedding with Stabilized Barzilai-Borwein Step Size)
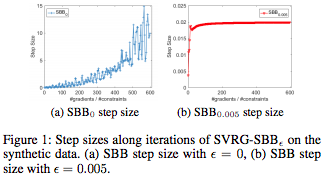
根据相对相似度比较来学习表征的方法通常被称为序数嵌入(ordinal embedding),该方法在近些年得到了越来越多的关注。大多数已有的方法都是主要基于凸优化而设计的批处理方法,比如投影梯度下降法(projected gradient descent method)。但是,由于更新过程中通常采用了奇异值分解(SVD),所以这些方法往往非常耗时,尤其是当数据量非常大时。
为了克服这一难题,我们提出了一种名叫 SVRG-SBB 的随机算法,该算法有以下特性:(a)通过丢弃凸性而不再需要 SVD,而且通过使用随机算法(即方差缩减随机梯度算法(SVRG))而实现了优良的扩展性能;(b)引入一种新的具有自适应的步长选择的稳定化 Barzilai-Borwein(SBB)方法,由于凸问题的原始版本可能无法用于所考虑的随机非凸优化问题。此外,研究表明我们提出的算法能在我们的设置中以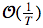
论文地址:https://arxiv.org/abs/1711.06446
4. 降秩线性动态系统(Reduced-Rank Linear Dynamical Systems)
线性动态系统(LDS)在研究多变量时间序列的基本模式方面有广泛的应用。这些模型的一个基本假设是高维时间序列可以使用一些基本的、低维的和随时间变化的隐含状态来表征。但是,已有的 LDS 建模方法基本上是学习一个规定了维数的隐含空间。当处理长度较短的高维时间序列数据时,这样的模型会很容易过拟合。我们提出了降秩线性动态系统(RRLDS),可以在模型学习过程中自动检索隐含空间的固有维数。
我们观察到的关键是 LDS 的动态矩阵的秩中包含了固有的维数信息,而使用降秩正则化的变分推理最终会得到一个简明的、结构化的且可解释的隐含空间。为了让我们的方法能处理有计数值的数据,我们引入了离散性自适应分布(dispersion-adaptive distribution)来适应这些数据本身具备的过离散性/等离散性/欠离散性。在模拟数据和实验数据上的结果表明我们的模型可以稳健地从长度较短的、有噪声的、有计数值的数据中学习隐含空间,并且还显著超越了当前最佳的方法的预测表现。
5. 使用重构模型翻译代词脱落语言(Translating Pro-Drop Languages with Reconstruction Models)
在汉语等代词脱落语言(pro-drop language)中,代词常会被省略,这通常对翻译结果的完整性造成极大的不良影响。到目前为止,很少有研究关注神经网络机器翻译(NMT)中的代词脱落(DP)问题*。在这项研究中,我们提出了一种全新的基于重构的方法,用于缓解NMT 模型中代词脱落所引起的翻译问题。首先,利用双语语料库中提取的对齐信息,将所有源句子中脱落的代词进行自动标注。然后,再使NMT模型中的隐藏层的表示重构回被标注的源句子。使用重构分数来辅助训练目标,用于鼓励隐藏层表征尽可能地嵌入标注的DP信息,从而引导与该NMT模型相关的参数来产生增强的隐藏层表征。我们在汉语-英语和日语-英语对话翻译任务上进行实验,结果表明本方法显著地、持续地超过了强大的NMT基准系统,该基准系统直接建立在标注了DP的训练数据上。
注:论文第一作者王龙跃(微博https://www.weibo.com/5374548129/FucLAAqP0?type=comment) 将 dropped pronoun (DP) problem 称为代词缺失问题。但中文语言学的文献将其称为代词脱落问题,比如http://www.nssd.org/articles/article_detail.aspx?id=1002125785。为了与Pro-Drop Language术语统一,这里使用后者。
6. 改进序列到序列的成分句法分析(Improving Sequence-to-Sequence Constituency Parsing)
序列到序列的成分句法分析,通过自上而下的树线性化(tree linearization),将结构预测转化成一般的序列到序列的问题来处理,因此它可以很容易地利用分布式设备进行并行训练。这种模型依赖于一种概率注意机制,尽管这种机制在一般的序列到序列问题取得了成功,但在句法分析特定场景中它无法保证选择充分的上下文信息。之前的研究工作引入了一种确定性注意(deterministic attention)机制来为序列到序列的句法分析选择有信息量的上下文,但这种方法只能适用于自下而上的线性化,而且研究者也已经观察到:对标准的序列到序列的成分句法分析而言,自上而下的线性化优于自下而上的线性化。在这篇论文中,我们对该确定性注意力机制进行了拓展,使其可以适用于自上而下的树线性化。我们进行了大量实验,结果表明我们的句法分析器相比于自下而上的线性化取得了显著的准确度提升;在不使用重排序(reranking)或半监督训练的情况下,我们的方法在标准的英文PTB 和 中文CTB数据集上分别达到了92.3 和 85.4 Fscore。
7. 用于众包配对排名聚合的使用信息最大化的 HodgeRank(HodgeRank with Information Maximization for Crowdsourced Pairwise Ranking Aggregation)
众包近来已经成为了许多领域解决需要人力的大规模问题的有效范式。但是,任务发布者通常预算有限,因此有必要使用一种明智的预算分配策略以获得更好的质量。在这篇论文中,我们在 HodgeRank 框架中研究了用于主动采样策略的信息最大化原理;其中 HodgeRank 这种方法基于多个众包工人(worker)的配对排名数据的霍奇分解(Hodge Decomposition)。该原理给出了两种主动采样情况:费希尔信息最大化(Fisher information maximization)和贝叶斯信息最大化(Bayesian information maximization)。其中费希尔信息最大化可以在无需考虑标签的情况下基于图的代数连接性(graph algebraic connectivity)的序列最大化而实现无监督式采样;贝叶斯信息最大化则可以选择从先验到后验的过程有最大信息增益的样本,这能实现利用所收集标签的监督式采样。实验表明,相比于传统的采样方案,我们提出的方法能提高采样效率,因此对实际的众包实验而言是有价值的。
论文地址:https://arxiv.org/abs/1711.05957
8. 自适应图卷积神经网络(Adaptive Graph Convolutional Neural Networks)
图卷积神经网络(Graph CNN)是经典 CNN 的方法,可用于处理分子数据、点云和社交网络等图数据。Graph CNN 领域当前的过滤器是为固定的和共享的图结构构建的。但是,对于大多数真实数据而言,图结构的规模和连接性都会改变。本论文提出了一种有泛化能力的且灵活的Graph CNN,其可以使用任意图结构的数据作为输入。通过这种方式,可以在训练时为每个图数据都学习到一个任务驱动的自适应图。为了有效地学习这种图,我们提出了一种距离度量学习。我们在九个图结构数据集上进行了大量实验,结果表明我们的方法在收敛速度和预测准确度方面都有更优的表现。
9. 多维长时数据的隐含稀疏模型(Latent Sparse Modeling of Longitudinal Multi-dimensional Data)
我们提出了一种基于张量的模型,可用于对由多样本描述单个对象的多维数据进行分析。该模型能同时发现特征中的模式以及揭示会影响到当前结果的过去时间点上的数据。其模型系数,一个 k-模的张量,可分解为 k 个维数相同的张量的总和。为了完成特征选择,我们引入了张量的“隐含F-1模”作为我们的公式中的分组惩罚项。此外,通过开发一个基于张量的二次推断函数(quadratic inference function, QIF),我们提出的模型还能考虑到每个对象的所有相关样本的内部关联性。我们提供了当样本量趋近于无穷大时对模型的渐进分析(asymptotic analysis)。为了解决对应的优化问题,我们开发了一种线性化的块坐标下降算法(linearized block coordinate descent algorithm),并证明了其在样本量固定时的收敛性。在合成数据集以及真实数据集:功能性磁共振成像( fMRI) 和 脑电图(EEG) 上的计算结果表明我们提出的方法比已有的技术有更优的表现。
论文地址:http://www.engr.uconn.edu/~jinbo/doc/AAAI_18_v5.pdf
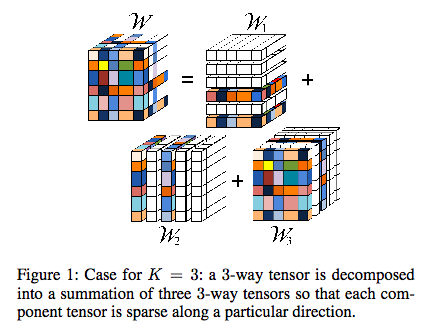
10. 使用用户-物品联合自回归模型的协同过滤(Collaborative Filtering with User-Item Co-Autoregressive Models)
深度神经网络已经表现出了在协同过滤(CF)方面的潜力。但是,已有的神经方法要么是基于用户的,要么就是基于项目的,这不能明确地利用所有的隐含信息。我们提出了 CF-UIcA,这是一种用于 CF 任务的神经联合自回归模型,其利用了用户和物品两个域中的结构相关性。这种联合自回归允许为不同的任务集成其它额外的所需特征。此外,我们还开发了一个有效的随机学习算法来处理大规模数据集。我们在 MovieLens 1M 和 Netflix 这两个流行的基准上对 CF-UIcA 进行了评估,并且在评级预测和推荐最佳 N 项的任务上都实现了当前最佳的表现,这证明了 CF-UIcA 的有效性。
论文地址:https://arxiv.org/abs/1612.07146
11. EAD:通过对抗样本实现对深度神经网络的弹性网络攻击(EAD: Elastic-Net Attacks to Deep Neural Networks via Adversarial Examples)
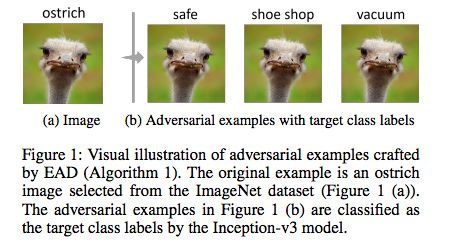
近来的一些研究已经突出说明了深度神经网络(DNN)面对对抗样本时的脆弱性——我们可以轻松创造出在视觉上难以区分,却能让经过良好训练的模型分类错误的对抗图像。已有的对抗样本创造方法是基于 L2 和 L∞ 失真度量的。但是,尽管事实上 L1 失真就能说明整体的变化情况且鼓励稀疏的扰动,但在创造基于 L1 的对抗样本上的发展则很少。
在本论文中,我们将使用对抗样本攻击 DNN 的过程形式化为了使用弹性网络正则化的优化问题。我们对 DNN 的弹性网络攻击(EAD)使用了面向 L1 的对抗样本,并且还包含了当前最佳的 L2 攻击作为特例。在 MNIST、CIFAR10 和 ImageNet 上的实验结果表明 EAD 可以得到一组明确的具有很小 L1 失真的对抗样本,并且能在不同攻击场景中实现与当前最佳方法近似的攻击表现。更重要的是,EAD 能改善攻击可迁移性以及帮补 DNN 的对抗训练,这为在对抗机器学习中利用 L1 失真以及 DNN 的安全意义提供了全新的见解。
论文地址:https://arxiv.org/abs/1709.04114

加入社群
新智元AI技术+产业社群招募中,欢迎对AI技术+产业落地感兴趣的同学,加小助手微信号: aiera2015_1 入群;通过审核后我们将邀请进群,加入社群后务必修改群备注(姓名-公司-职位;专业群审核较严,敬请谅解)。
此外,新智元AI技术+产业领域社群(智能汽车、机器学习、深度学习、神经网络等)正在面向正在从事相关领域的工程师及研究人员进行招募。
加入新智元技术社群 共享AI+开放平台



