MIT 的新型开源系统 Taco 将数据分析速度提升 100 倍 !(附论文)
麻省理工学院(MIT)开发的一种新型计算机系统为涉及“稀疏张量”(sparse tensor)的计算加快了速度,稀疏张量是主要由0组成的多维数据数组。
我们生活在大数据时代,但是这些数据大多数是“稀疏数据”。比如设想一下,一个庞大表格列出了亚马逊的所有顾客与其所有商品对应的信息,“1”对应于某个顾客购买的每件商品,“0”对应于未购买的每件商品。此表格基本上以0为主。
如果是稀疏数据,分析算法最后执行涉及0的大量加法和乘法操作,这浪费了计算资源。为了规避这个问题,程序员们编写自定义代码来避免0数据项,不过这种代码很复杂,而且通常只适用于一小批问题。
在美国计算机协会(ACM)召开的系统、编程、语言和应用程序:为人类所用的软件(SPLASH)大会上,来自 MIT、法国替代能源和原子能委员会以及 Adobe Research 的研究人员最近介绍了一种新的系统,可自动生成针对稀疏数据优化的代码。
这种代码比未经过优化的现有软件包快100倍。其性能与针对特定的稀疏数据操作而精心手动优化的代码不相上下,但只需要程序员做极少的工作。
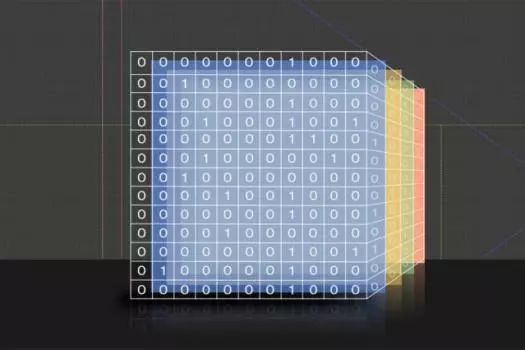
这个系统名为Taco,意指稀疏代数编译器(Tensor Algebra COmpiler)。用计算机科学术语来说,像上面亚马逊表格这样的数据结构名为“矩阵”(matrix),张量只是相当于更高维度的矩阵。如果亚马逊表格还将顾客和产品与该顾客在亚马逊网站上的产品评价和产品评价中所用的词语对应起来,结果就是四维张量。
萨曼•阿马拉辛格(Saman Amarasinghe)是MIT电气工程和计算机科学(EECS)教授,也是这篇新论文的主要作者。他说:“稀疏表示问世至今已有60多年,但没有人知道如何自动为它们生成代码。人们搞清楚了几种非常特定的操作――稀疏矩阵与向量相乘、稀疏矩阵与向量相乘后与向量相加、稀疏矩阵与矩阵相乘以及稀疏矩阵与矩阵、矩阵相乘。我们所做的最大贡献就是,在矩阵是稀疏的情况下能够为任何张量代数表达式生成代码。”
与阿马拉辛格一同撰写论文的还有第一作者MIT EECS研究生弗雷德里克•肖尔斯塔德(Fredrik Kjolstad)、同样是EECS研究生的斯蒂芬•周(Stephen Chou)、法国替代能源和原子能委员会的大卫•卢加托(David Lugato)以及Adobe Research的肖艾布•卡米尔(Shoaib Kamil)。
定制核心
近些年来,张量的数学运算(张量代数)不仅对大数据分析来说至关重要,对机器学习来说也至关重要。从爱因斯坦时代以来,张量代数就是科学研究的一个重要组成部分。
过去,要处理张量代数,数学软件将张量操作分解成多个组成部分。所以比如说,如果某个计算需要两个张量相乘,然后与第三个张量相加,软件就会对前两个张量执行标准张量相乘操作,将结果存储起来,然后执行标准张量相加操作。
然而在大数据时代,这种方法太费时间了。肖尔斯塔德解释道,为了在庞大数据集上执行高效操作,张量操作的每个序列需要各自的“核心”,也就是计算模板。
肖尔斯塔德说:“如果你在一个核心中处理,可以一次性完成处理,你还可以让它处理得更快,而不是非得将结果存放到内存中,然后读回结果,以便你可以与别的东西相加。你在同一个循环中即可完成。”
计算机科学研究人员已为机器学习和大数据分析中最常见的一些张量操作开发了核心,比如说阿马拉辛格上面列举的那些张量操作。但潜在核心的数量却是无限的:比如说,将三个张量相加的核心不同于将四个张量相加的核心,而将三个三维张量相加的核心又不同于将三个四维张量相加的核心。
许多张量操作涉及将来自一个张量的项与来自另一个张量的项相乘。如果其中一个项是0,结果也是 0,处理庞大稀疏矩阵的程序会浪费大量的时间对0执行相加和相乘操作。
针对稀疏张量手动优化的代码可识别出是0的项,并简化含有这些项的操作――加法时对非0项进位相加,或者完全忽略与0相乘。这大大加快了张量操作,但大大增加了程序员的工作量。
比如说,如果矩阵很稠密(意味着没有一项被省略),两个矩阵相乘(一种简单的张量,只有两个维度,像表格那样)的代码只有12行。但如果矩阵很稀松,同样的操作可能需要至少100行代码来跟踪分析省略和删节。
Taco应运而生
Taco自动添加所有这些额外的代码。程序员只要指定张量的大小、张量很稠密还是很稀疏以及导入值的那个文件的位置。就针对两个张量的任何特定操作而言,Taco 建立一张层次图,该图先表明来自两个张量的哪些配对项非0,然后表明来自每个张量的哪些项与0配对。所有0与0配对的一律被丢弃。
Taco还使用一种高效的索引方案,只存储稀疏张量的非0值。如果包含0项,来自亚马逊的一个公开发布的张量(将顾客的ID号与购买物品和从评论提取的描述词语对应起来)要占用 107 艾字节(EB)数据,相当于谷歌所有服务器的估计存储容量的10倍。但使用Taco压缩方案,它仅仅占用13吉字节(GB),小得足以在智能手机上装得下。
未参与这项研究的俄亥俄州立大学计算机科学和工程系教授萨代•萨达亚潘(Saday Sadayappan)说:“在过去的二十年,许多研究小组试图解决稀疏矩阵计算的编译器优化和代码生成问题,但进展甚微。弗雷德和萨曼最近取得的进展却表明这个长期悬而未决的问题有了根本性的突破。”
他继续说:“他们的编译器现在让应用程序开发人员能够用一种非常容易、方便的高级标记方法来指定非常复杂的稀疏矩阵或张量计算,编译器因此可自动生成非常高效的代码。对于几种稀疏计算而言,结果表明编译器生成的代码与精心手动开发的代码一样好,或甚至更好。这有望真正地改变游戏规则。它是编译器优化领域近期取得的最激动人心的进步之一。”