【ACL2019最佳论文提名】检测文本和语音中的隐瞒信息
导读
摘要
在各行各业和政界发生的臭名昭著的作弊丑闻的推动下,我们解决了在专业领域中检测隐瞒信息的问题。在本研究中,我们收集了专业人士在隐瞒信息的情况下进行口试的特殊语料库,并藉此探究隐瞒现象背后的音韵特征和语言特征。我们在言语和文字中揭示了隐瞒信息的微妙迹象,并将其与欺骗检测文献进行比较,从而揭示欺骗现象和隐瞒信息的联系。
研究背景
首先我们明确一下隐瞒(concealing)和欺骗(deception)的区别,论文作者用下面的表格向我们展示了两者的关系:
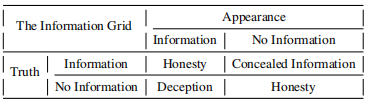
我们可以看到,当发言者的表现和实际情况一致时,也就是所谓的“知之为知之,不知为不知”的情况下,被认为是诚实的。而不懂装懂这种行为在本文中被定义为欺骗(deception),知道信息却装作不知道则是隐瞒(concealing)。在本论文中隐瞒表现为在专业口头考试中,提前知道考试内容却装作不知道。
本实验的一大难点在于,隐瞒与欺骗的过程中,个体会承受更大的压力和认知负荷以保持逻辑清晰,但隐瞒者由于实际上知道更多的信息,因此潜在上会降低其认知负荷,这两者的天然存在和互相抵消的可能使得隐瞒并不像欺骗一样容易辨别。
但不能否认隐瞒与欺骗存在着很大程度上的类似,作者在此借鉴了前人有关欺骗的研究,如欺骗性言语的语调升高(Newman,2003)和其LIWC特征(Pennebaker,2001)等。此外还有模糊表达,动词时态和否定表达等语言特征可以帮助预测其真实性(Levitan,2015)等,详见论文原文。
数据处理
为了模拟作弊丑闻中的情景,作者设计了一个现场实验,实验者进行盲品葡萄酒测试并说出对酒的评价和酒的名字,但在每组实验中安排了一个事先知道所有信息的隐瞒者。实验不仅收集了参与者的录音,视频,同时也将其言语用文字记录下来,另外也收集了作为评判者的专业人士对参加者的看法。同时收集了参与者的性别,母语,领域知识等相关的信息。得到共164小时的语料库,并将其按照70:10:20的比例分为训练集,开发集和测试集,评价结果基于五折交叉验证。
特征提取方面,作者使用Praat,Parselmouth和python的语音特征库,提取了强度均值和最大值,音高均值和最大值等八项基本特征,另外也提取了MFCCs等高级特征。下表是隐瞒信息者的基本特征:
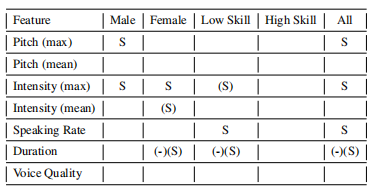
正如多项欺骗检测研究表明,隐瞒信息者也倾向于使用更高音高,强度,速度和更短的持续时间。此外低专业水平者在隐瞒时说话率会显著提高,这为作者之前的猜想提供了佐证,即额外的信息确实可以提高自信水平并抵消隐藏信息时认知负荷的影响。
而在文本方面,作者通过训练一个语言模型来衡量语言和句法的独特性,该模型使用的语料库由各大葡萄酒网站的评论组成。并使用unigrams,bigrams和trigrams进行训练。此外使用TextBlob提取主观性和情绪测度,使用GloVe训练葡萄酒语料库中的单词向量并捕捉语义关系。还有许多特征在此不进行赘述。
下表为用逻辑回归分类得到的隐瞒信息和真实信息的Ngram特征,其F1分数为60.13%。另外,作者将结果与最近的欺骗研究结果进行了比对,用红色代表与其相一致的特征,用蓝色代表与其相反的特征:
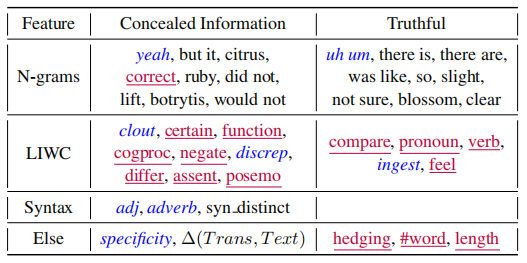
作者发现um等填充停顿词,往往出现在真实谈话当中,而隐瞒信息者倾向于表现出更明确的肯定和否定,以及更积极的情绪,这符合之前有关认知符合,置信水平,和隐瞒信息压力的假设。
实验模型
作者使用逻辑回归作为Ngrams的基线模型,用随机森林分类器作为文本和语音的极限模型。在对LR进行了不同的预处理(停止字,ngrams的数量等)之后,作者发现仅使用bigram特征的LR由最好的效果。对随机森林进行调试后,发现设置800个决策树效果最好。
随后作者使用深度学习模型,采用了词嵌入序列,MLP及其组合训练BiLSTM模型。用GloVe embedding初始化权值,在训练过程中也允许反向传播更新嵌入值。用贝叶斯优化来调整各种超参数(包括学习率,MLP的隐藏层数,每层隐藏单元数等)。最终模型的MLP有四个全连接层,每层680个单元并使用ReLU激活函数。然后用一个两种输出输出的softmax层,分别对应真实和隐瞒两种分类,使用交叉熵作为损失函数。
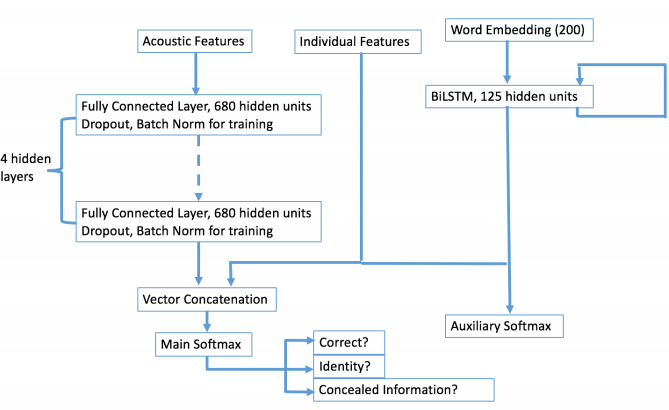
基于上述模型,作者添加了两个使用同样训练集并额外使用品酒师协会的数据训练的任务,一个是预测实验者说的是否正确,另一个是酒的真实名字。该多任务学习的结构如下图所示:
结果和分析
下表显示了每个模型类别中表现最好的模型的F1得分,人类得分在第一行中以红色标出,因为其表现劣于表中的所有其他模型。本文提出的多任务学习的联合模型比普通模型高11%的得分,并且比人类专家的表现高15%。
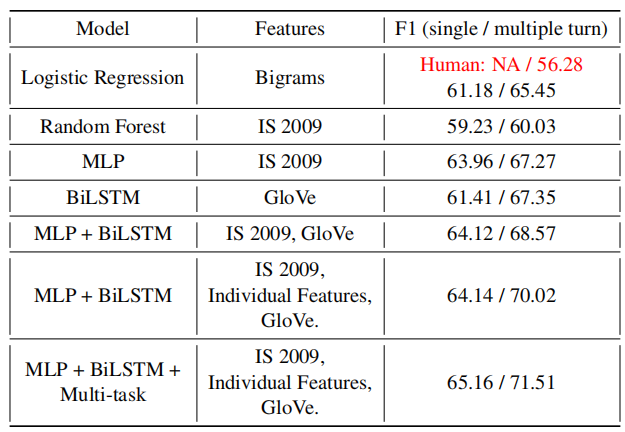
从实验结果中我们可以看出,作者提出的多任务学习有不俗的表现。关于隐瞒信息的研究还有很多值得探索的地方,作者本人也表示这项工作可能会用于揭发金融内幕交易当中。相信这种多任务学习的模型也能为NLP未来的研究带来一些启发。
部分文章








请关注专知公众号(点击上方蓝色专知关注)
后台回复“DCI” 就可以获取《Detecting Concealed Information in Text and Speech》文章下载链接~
-END-
专 · 知
专知,专业可信的人工智能知识分发,让认知协作更快更好!欢迎登录www.zhuanzhi.ai,注册登录专知,获取更多AI知识资料!

欢迎微信扫一扫加入专知人工智能知识星球群,获取最新AI专业干货知识教程视频资料和与专家交流咨询!

请加专知小助手微信(扫一扫如下二维码添加),加入专知人工智能主题群,咨询技术商务合作~

专知《深度学习:算法到实战》课程全部完成!560+位同学在学习,现在报名,限时优惠!网易云课堂人工智能畅销榜首位!

点击“阅读原文”,了解报名专知《深度学习:算法到实战》课程




