伯克利团队新研究:不用神经网络,也能快速生成优质动图

NeRF 模型 demo
基于神经辐射场(NeRF, NeuralRadiance Fields)的图像生成,可实现逼真、新颖的视点渲染,可以捕捉场景几何和视点相关(view-dependent)的效果。
然而,这种令人印象深刻的方法背后,需要付出的是大量的计算时间,以进行训练和渲染。围绕 NeRF,随后的研究中都聚焦于如何降低计算成本(尤其是渲染)上,但单个 GPU 训练仍然需要数小时,此瓶颈显然制约了逼真容积重建(VR, Volumetric Reconstruction)的实际应用。
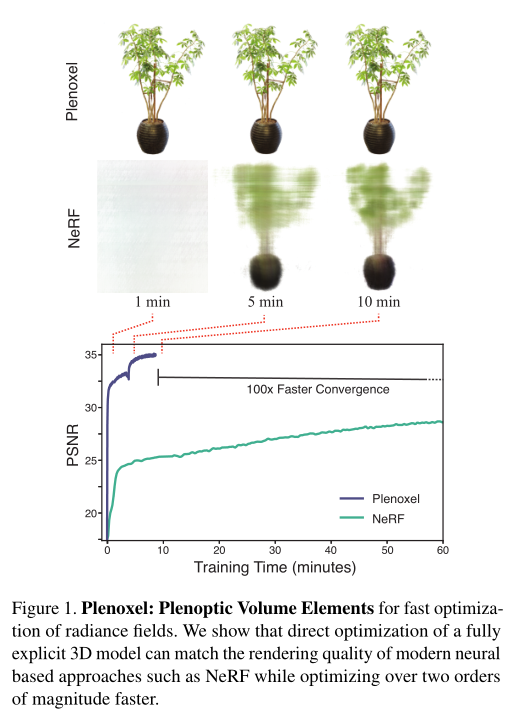
就在近日,来自加州大学伯克利分校的研究团队,发表了一篇题为“Plenoxels: Radiance Fields without Neural Networks”的论文,介绍了一种无需神经网络,便可以从头开始训练辐射场的方法,并且在保持 NeRF 质量的同时,将优化时间减少两个数量级。

在用于逼真的场景建模和新颖的视点渲染时,这种名为 Plenoxels(plenoptic voxels)的方法产生的效果不仅与最先进的保真度相当,而且训练时间更短(相关视频和代码,请参阅https://alexyu.net/plenoxels)。
具体方法
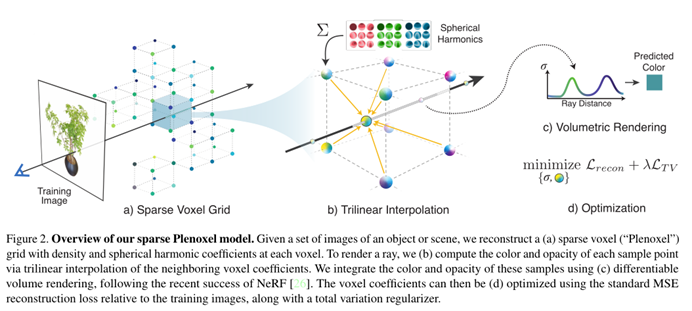
给定一组校准的图像,研究团队直接使用训练射线上的渲染损失来优化模型(如图 2),详细的步骤如下:
(1)立体渲染(volume rendering)
团队成员使用与 NeRF 中相同的可微模型进行立体渲染,其中光线的颜色是通过对沿着光线采集的样本进行积分来近似的:
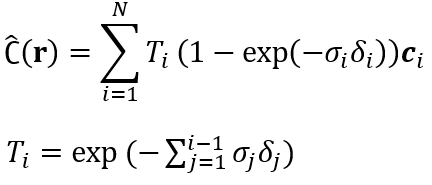
其中,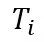
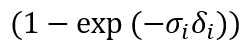
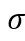
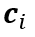
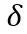
(2)带有球谐的体素网格
与 PlenOctrees 类似,团队成员使用稀疏体素网格作为几何模型。然而,为了简单方便地实现三线性插值,不再使用八叉树三维数据结构。相反地,研究团队将带有指针的密集 3D 索引阵列存储到单独的数据数组中,该数据数组仅包含已占用体素的值。如 PlenOctrees 一样,每个被占用的体素为每个颜色通道存储标量不透明度和球谐系数矢量。然后,球面谐波形成了定义在球面上的函数的正交基,低次谐波编码平滑的颜色变化,高次谐波编码更高频率的效果。样本的颜色简单来说,就是每个颜色通道的谐波基函数的和,通过相应的优化系数加权,并在合适的视图方向上评估。团队采用 2 度的球面谐波,也就要求,每种颜色通道需要 9 个系数,每个体素总共有 27 个谐波系数。之所以采用 2 次谐波,是因为先前的研究发现,高次谐波只能带来最小的效益。
(3)插值(Interpolation)
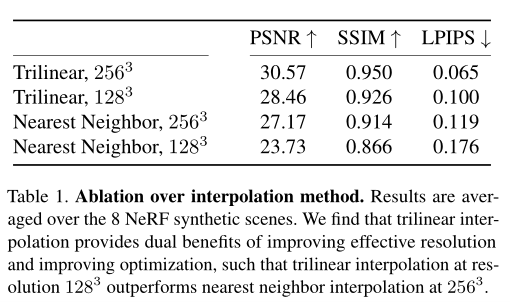
通过存储在最近的 8 个体素上的不透明度和谐波系数的三线性插值,计算每条射线上每个样本点的不透明度和颜色。研究团队发现,三线性插值显著优于简单的最近邻插值(如表 1 所示)。插值的优势有二:其一,插值通过表示颜色和不透明度的亚体素(sub-voxel)变化来提高有效分辨率;其二,插值产生连续函数近似,这对成功的优化至关重要。
表 1 很好地呈现了这两种影响:将最近邻插值 Plenoxel 的分辨率加倍,可以在固定分辨率下缩小最近邻插值和三线性插值之间的大部分间隙,但由于不连续模型难以优化,仍然存在一些差距。实际上,研究团队发现,与最近邻插值相比,三线性插值在学习速率变化方面更加稳定。
(4)优化策略:由粗到细
通过一种从粗到细的策略来实现高分辨率,该策略从低分辨率的密集网格开始,优化、删除不必要的体素,进而在每个维度中,将每个体素细分成两半来细化剩余的体素,并继续优化。比如说,在合成情况下,从 256^3 分辨率开始,一直向上采样到 512^3。在每个体素细分步骤之后,借助三线性插值来初始化网格值。事实上,可以利用三线性插值在任意分辨率之间调整大小。体素剪枝沿用的是 PlenOctrees 方法,它可对所有训练辐射场中每个体素的最大权重应用一个阈值。考虑到研究使用的是三线性插值,一旦修剪欠佳,会对表面附近的颜色和密度产生不利影响,因为这些点的值会插值到直接外部的体素。为解决此问题,团队成员决定执行扩张操作,在此设置下,一个体素只有在它自己和邻居都被认为是空闲状态时,才被修剪。
(5)优化过程
相对于均方误差(MSE, Mean SquaredError)渲染像素颜色,全变分(TV, Total Variation)正则化而言,研究团队需要对体素不透明度和球谐系数进行优化。具体来说,损失函数可表示如下:
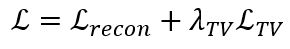
其中,MSE 的重建损失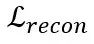
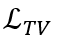
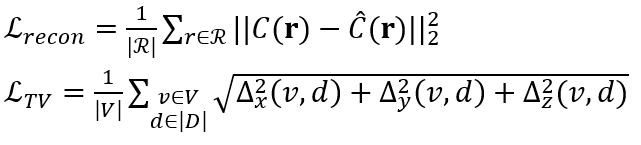
为了加快迭代速度,团队成员在每个优化步骤中使用射线 R 的随机样本来评估 MSE 项,并使用体素 V 的随机样本来评估每个优化步骤中的 TV 项。研究团队采用与 JAXNeRF 和 Mip-NeRF 相同的学习速率时间表,但针对不透明度和谐波系数,分别调整了初始学习速率。
(6)无限的场景
研究证明,Plenoxels 可以超出原始 NeRF 论文的合成场景,进行各种设置的优化。通过微小的修改,Plenoxels 便可以延伸到真实的、无界的场景,包括前向场景和 360° 场景。对于前向场景,团队使用相同的稀疏体素网格结构,并采用标准化的设备坐标。而对于 360° 场景,团队成员使用 MSI 背景模型来增强稀疏体素网格前景表示。此外,该模型还应用了学习到的体素颜色和不透明度以及球体内部和球体之间的三线性插值。
(7)正则化
图 3 形象的说明了 TV 正则化的重要性。除了鼓励平滑,并在所有场景中使用 TV 正则化之外,对于某些特定类型的场景,团队还应用了额外的正规化。

在真实、前向和 360° 场景中,团队成员采用了基于 Cauchy 损失的稀疏性先验,表示如下:
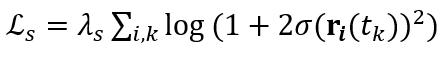
其中,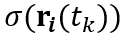
在真实的 360° 场景中,研究团队还对每个小批量中,对每条射线的累积前景透过率(transmittance)使用 beta 分布正则化器。其中,损失项通过鼓励前向完全不透明或为空,来促进前景-背景的清晰分解。Beta 损失可以表示为:
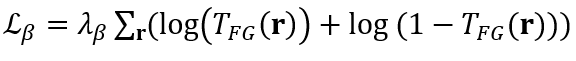
其中 r 为训练射线,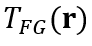
(8)方案实施
考虑到在目前的 autodiff 库中,稀疏体素的容积渲染尚未得到很好地支持,所以研究团队创建了一个定制的 PyTorch CUDA 扩展库,目的是实现快速可微的容积渲染。团队成员希望,研究者能够发现该方法的有用性。除此之外,研究团队还提供了一个更慢、更高级别的 JAX 实现版本。重要的是,这两种执行方案均开源。
如图 4 所示,提高运行速度自然不在话下,其中很大程度上源于 Plenoxel 模型的梯度变得非常稀疏。在优化的前 1-2 分钟内,仅有不到 10% 的体素具有非零梯度。
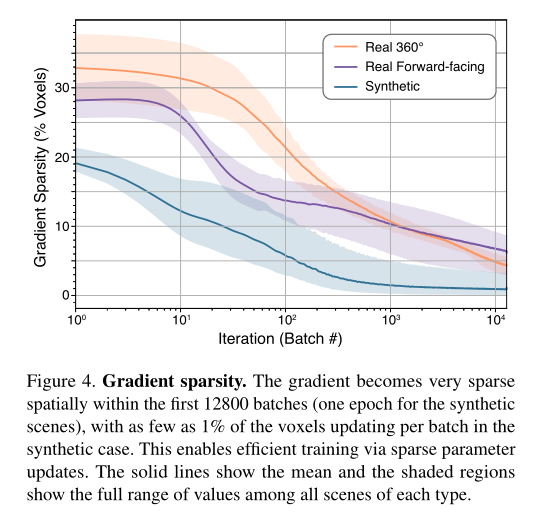
实验结果及分析
研究团队在合成的有限场景上,呈现了实验结果。
其中,包含(1)真实的、无界、面向前方的场景;(2)真实的、无界、360° 场景。与先前的方法相比较,本文的方法在训练速度上展示了绝对的优势。表2给出了定量比较的结果,而图 6、7 和 8 则直观地展现了视觉对比的情况。



可以很容易的观察到,本文的方法在第一个优化阶段之后,在不到 1.5 分钟的时间内即获得了高质量的结果,如图 5 所示。

额外地,团队成员也给出了各种消融研究的结果,完整的实验细节请参阅论文的附录部分。
(1)合成场景实验
在合成实验中,选用了 NeRF 中的 8 个场景:椅子、鼓、榕属、热狗、乐高、材料、麦克风和船舶。具体地,每个场景包括 100 个分辨率为 800 × 800 的地面实况训练视图,这些视图来自已知的机位,随机分布在面对对象的上半球,设置在纯白背景下。每个场景在 200 个测试视图上进行评估,同样为 800 × 800 的分辨率,并且已知摄像头在上半球的内朝向位置。表 2 中提供定量比较结果,图 6 呈现了视觉对比的效果。
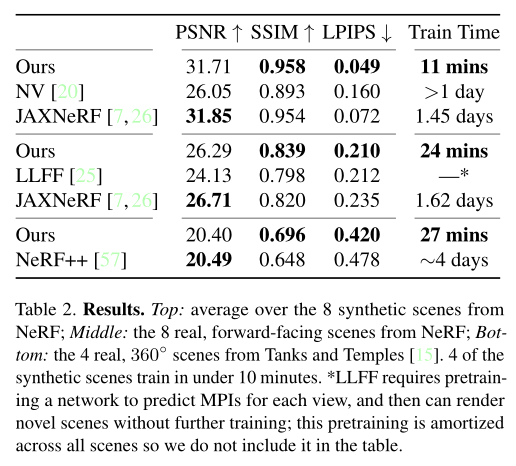
研究团队在对比实验的过程中,分别与神经体积(NV, Neural Volumes)(作为一种使用 3D 卷积网络预测每个场景的网格的先前方法)和JAXNeRF分别展开了比较。结果显示,本文的方法达到了与最佳基线相当的质量,同时在单个 GPU 上,每个场景的平均训练仅为 11 分钟,并且支持交互式渲染。
(2)真实的前向场景实验
研究团队通过使用归一化设备坐标将其方法扩展到无界的、前向的场景。在有界合成场景上,除了整个优化过程中使用了 TV 正则化(具有更强的权重)外,也使用了相同的版本。研究成员将提出的方法与局部光场融合(LLFF)(一种使用 3D 卷积网络预测每个输入视图的网格的先前方法)和 JAXNeRF 进行了比较。具体地,表 2 中提供定量比较结果,在图 7 中展示了视觉对比的情况。
(3)真实的 360° 场景实验
研究团队将方法扩展到真实的,无界的,360° 场景,通过使用 MSI 背景模型包围稀疏体素网格,其中每个背景球体也是一个简单的体素网格与三线性插值。实验采用 Tanks 和 Temples 数据集,包含以下 4 个场景:M60,操场,火车和卡车。团队成员将提出的方法与 nerf++(通过背景模型来增强 NeRF,以表示无边界场景)做了对比。具体地,表 2 中提供定量比较结果,在图 8 中展示了视觉对比的情况。
(4)消融实验
在这一部分,研究团队通过一个简单的模型,对本文的方法进行了广泛的消融研究,以充分了解哪些特征是其成功的核心。由表 1 可得,与最近邻插值相比,连续插值在保真度上有显著的提高。而在表 3 中,团队考虑了如何在 8 个合成场景中,让本文方法更好地处理训练数据急剧减少的情况,从 100 视图到 25 个视图。通过与 NeRF 的对比实验发现,尽管它缺乏复杂的神经网络先验知识,但通过增加 TV 正则化,即使在有限的数据范围内,本文方法也可以优于 NeRF。
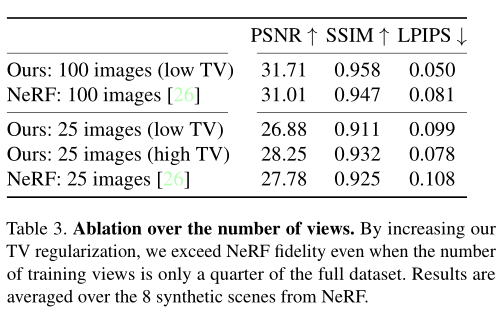
这种消融也揭示了,在真实的、前向场景上,为什么模型使用更高的 TV 正则化比合成场景表现得更好?原因就在于,真实场景有更少的训练图像,更强的正则化有助于将优化平稳地扩展到稀疏的监督区域。
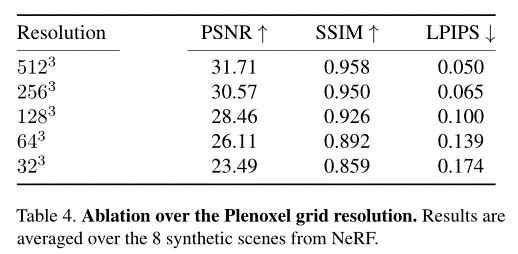
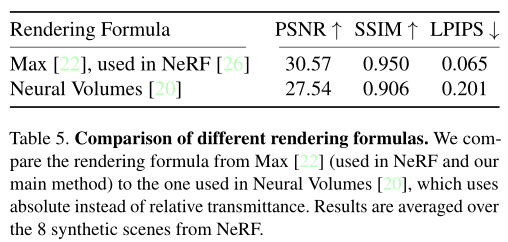
此外,Plenoxel 网格分辨率和渲染公式的消融实验结果,分别呈现在表 4 和表 5 中。
结论
本文的方法不仅简单明了,而且成功揭示了解决 3D 逆向问题时,所必需的核心元素:可微正向模型,连续表示(通过三线性插值),以及适当的正则化。
研究团队承认,尽管这种方法的元素已经可用很长时间了,但是计算机视觉从业者最近才可以访问具有数千万变量的非线性优化。
当然,该方法也存在一定的限制,与任何未敲定的逆向问题一样,很容易受到伪影(Artifacts)的干扰。
本文提出的方法表现出与神经方法不同的伪影,如图9所示,但两种方法在标准度量方面实现了相似的质量效果。研究团队表示,未来的工作可能会通过研究不同的正则化先验或更精确的微分渲染函数来调整或减小这些残余的伪影。


关于【数据实战派】

热门视频推荐
更多精彩视频,欢迎关注学术头条视频号
winter
【学术头条】持续招募中,期待有志之士的加入




