
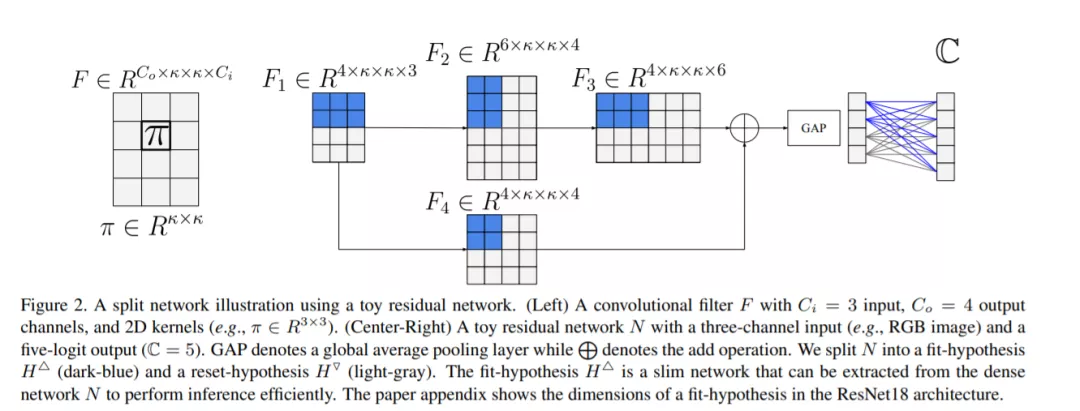
深度学习依赖于大量数据的可用性(有标记的或无标记的)。因此,一个挑战性的尚未解决的问题是:如何在相对较小的数据集上训练深度网络?为了解决这个问题,我们提出了一种演化启发的训练方法来提高相对较小的数据集的性能。知识演化方法将深度网络分为两个假说: 拟合假说和重置假说。我们通过对重置假说的干扰,对拟合假说内的知识进行多次迭代演化。该方法不仅提高了网络的性能,而且学习出了一个具有较小推理成本的超薄网络。KE与普通卷积网络和剩余卷积网络无缝集成。KE减少了过拟合和数据收集的负担。
我们在不同的网络结构和损耗函数上评估KE。我们使用相对较小的数据集(如CUB-200)和随机初始化的深度网络来评估KE。KE在最先进的基础上实现了绝对21%的改进幅度。与此同时,推理成本也相对降低了73%。KE在分类和度量学习基准方面取得了最先进的成果。代码可在http://bit.ly/3uLgwYb
成为VIP会员查看完整内容
相关内容

人工神经网络(Artificial Neural Network,即ANN ),是20世纪80 年代以来人工智能领域兴起的研究热点。它从信息处理角度对人脑神经元网络进行抽象, 建立某种简单模型,按不同的连接方式组成不同的网络。在工程与学术界也常直接简称为神经网络或类神经网络。神经网络是一种运算模型,由大量的节点(或称神经元)之间相互联接构成。每个节点代表一种特定的输出函数,称为激励函数(activation function)。每两个节点间的连接都代表一个对于通过该连接信号的加权值,称之为权重,这相当于人工神经网络的记忆。网络的输出则依网络的连接方式,权重值和激励函数的不同而不同。而网络自身通常都是对自然界某种算法或者函数的逼近,也可能是对一种逻辑策略的表达。
最近十多年来,人工神经网络的研究工作不断深入,已经取得了很大的进展,其在模式识别、智能机器人、自动控制、预测估计、生物、医学、经济等领域已成功地解决了许多现代计算机难以解决的实际问题,表现出了良好的智能特性。

相关VIP内容
相关资讯
相关论文