化繁为简,弱监督目标定位领域的新SOTA - 伪监督目标定位方法(PSOL) | CVPR 2020
加入极市专业CV交流群,与10000+来自腾讯,华为,百度,北大,清华,中科院等名企名校视觉开发者互动交流!
同时提供每月大咖直播分享、真实项目需求对接、干货资讯汇总,行业技术交流。关注 极市平台 公众号 ,回复 加群,立刻申请入群~
论文提出伪监督目标定位方法(PSOL)来解决目前弱监督目标定位方法的问题,该方法将定位与分类分开成两个独立的网络,然后在训练集上使用Deep descriptor transformation(DDT)生成伪GT进行训练,整体效果达到SOTA,论文化繁为简,值得学习。

-
论文地址:https://arxiv.org/abs/2002.11359
Introduction
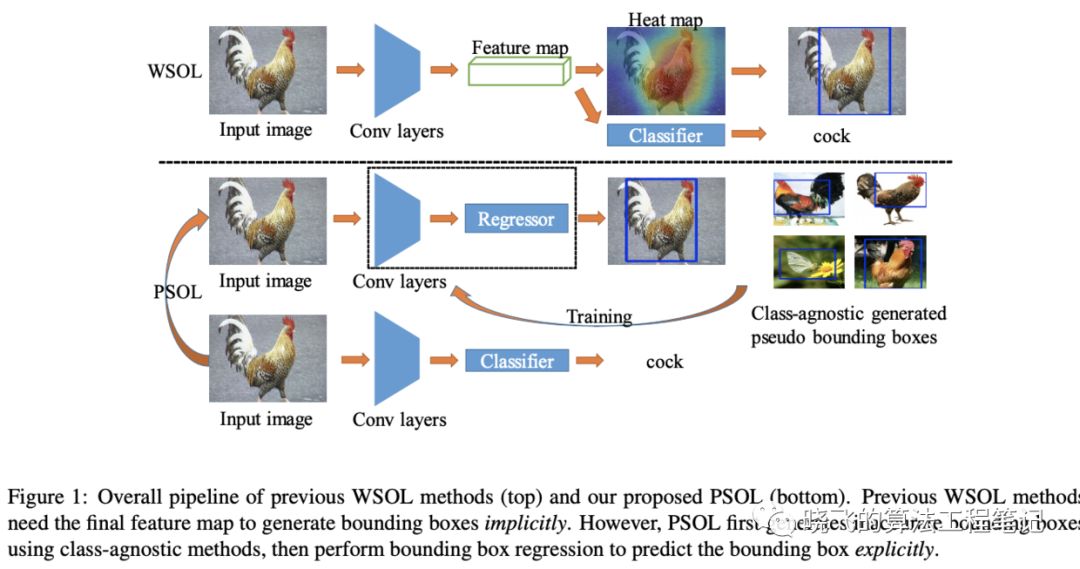
-
弱监督目标定位应该分为类不可知目标定位和目标分类两个独立的部分,提出PSOL算法 -
尽管生成的bbox有偏差,论文仍然认为应该直接优化他们而不需要类标签,最终达到SOTA -
在不同的数据集上,PSOL算法不需要fine-tuning也能有很好的定位迁移能力
Related Works
A paradigm shift from WSOL to PSOL
-
学习目标不明确,导致定位任务性能下降。独立的CNN不能同时进行定位和分类任务,因为定位需要目标的全局特征,而分类只需要目标的局部特征 -
CAM(Class Activation Mapping)存储一个三维特征图用于计算类别的heatmap,再用阈值过滤,但是一般阈值十分难确定
The PSOL Method

-
Bounding Box Generation
-
WSOL methods
-
DDT recap
-
Localization Methods
Experiments
Experimental Setups
-
Datasets,使用ImageNet-1k和CUB-200,测试数据的bbox是准确标注的,而训练集上的bbox则通过前面提到的方法进行生成 -
Metrics,验证3个指标:知道GT类别的定位准确率(GT-known Loc),当预测与GT的 时正确;Top-1定位准确率(Top-1 Loc),Top-1的分类正确且GT-known Loc正确;Top-5定位准确率(Top-5 Loc),Top-5结果中存在分类正确且GT-known Loc正确 -
Base Models,有VGG16/Inception V3/ResNet50/DenseNet161,没有增大图片输入,一些WSOL方法要用到类别信息的权重(单层全连接)来生成heatmap,而PSOL不用。为了公平起见,增加VGG-GAP,将所有全连接层换成单层全连接,而对于回归模型,仍然使用双层全连接层加对应的ReLU -
Joint and Separate Optimization,对于联合优化模型(-Joint),在原来的基础上加入bbox回归分支,然后同时训练模型的分类和定位。对于独立优化模型(-Sep),单独训练两个模型
Results and Analyses
Ablation Studies on How to Generate Pseudo Bounding Boxes
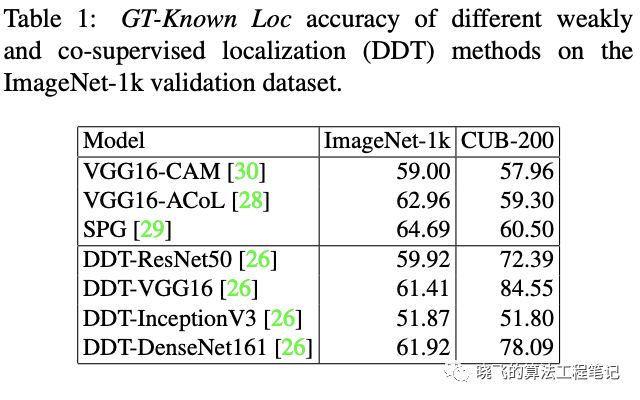
Comparison with State-of-the-art Methods
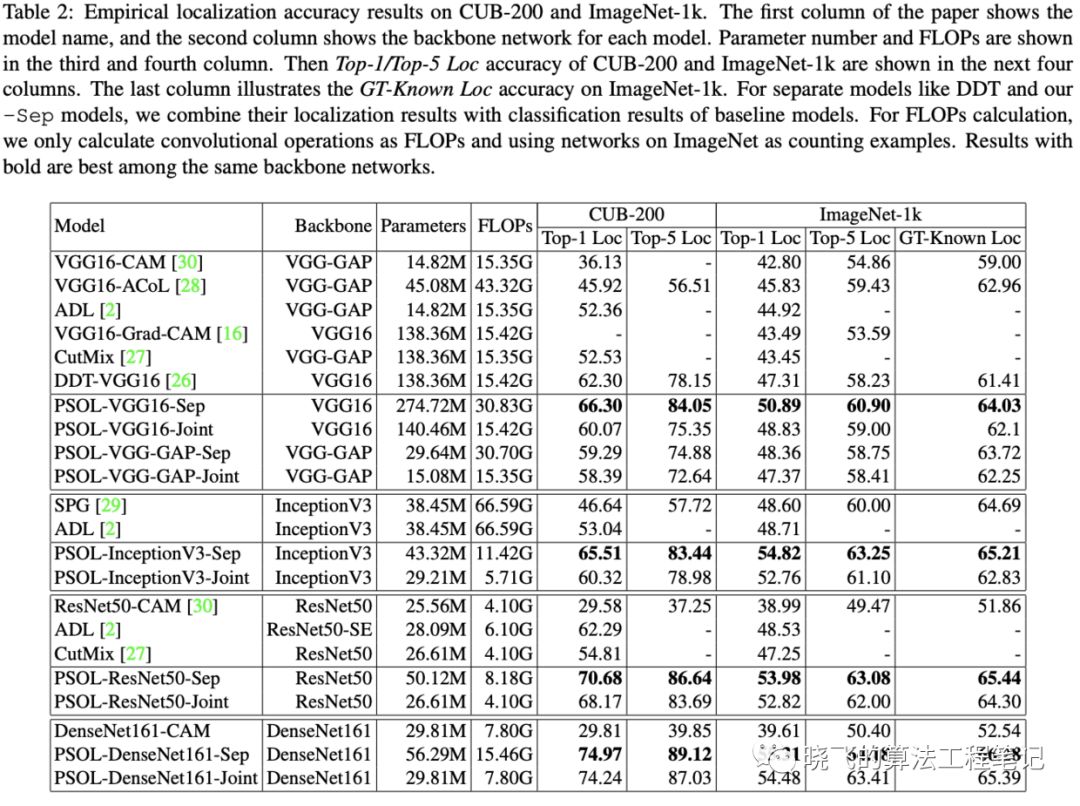

-
DDT本身就已经比WSOL方法要好,说明类不可知是有用的,WSOL应该分为两个独立的模型 -
所有PSOL方法分开训练都比联合训练要好,说明定位和分类学习到的内容不一样 -
POSL在CUB-200上都具有较大的优势,由于类别相似度较大,类别标签不一定能帮助定位,反而协同定位的DDT更占优 -
CNN有能力去处理有噪声的数据并且得到更高的准确率,PSOL模型的GT-Known Loc基本都比DDT-VGG16高 -
WSOL里的一些约束没有带到PSOL中,例如只允许单层全连接层以及更大的输出特征图,去掉常见的三层全连接层会影响准确率,VGG-Full比VGG-GAP要好。还有WSOL方法在复杂的网络上效果不好,如DenseNet,主要由于DenseNet使用多层进行分类,不仅仅是最后一层,最后一层的语义不如VGG等明确,而PSOL-DenseNet则避免了这个问题,达到最高准确率
Transfer Ability on Localization
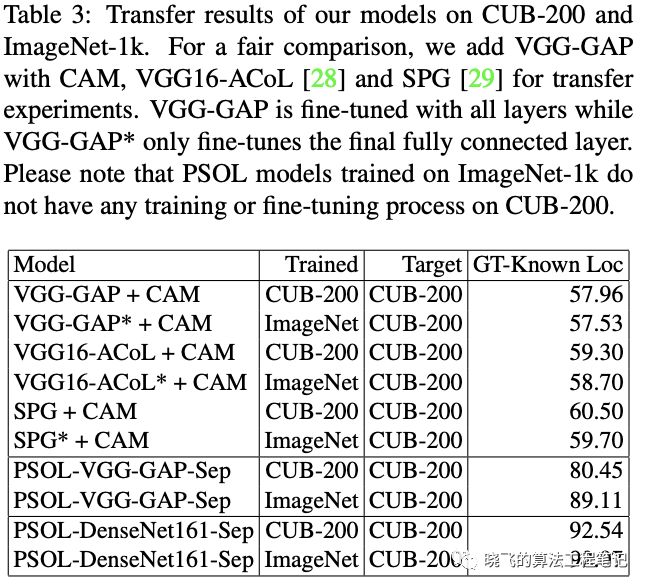
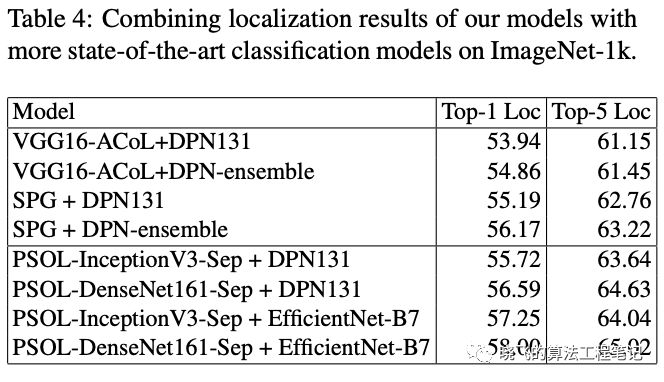
Combining with State-of-the-art Classification
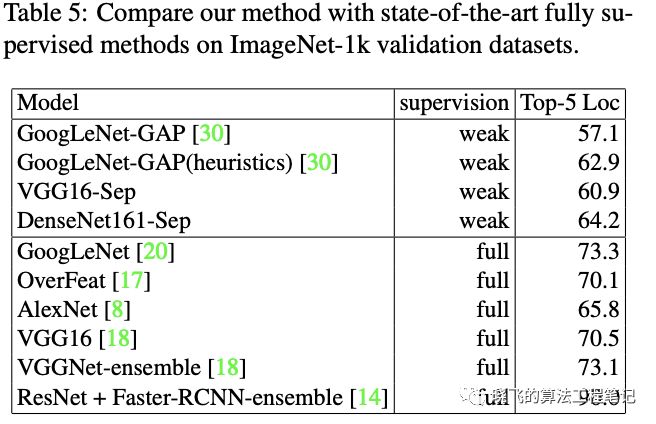
Comparison with fully supervised methods
CONCLUSION
-END-
*延伸阅读

△长按添加极市小助手

△长按关注极市平台,获取最新CV干货
觉得有用麻烦给个在看啦~

登录查看更多
相关内容
专知会员服务
87+阅读 · 2020年3月1日
专知会员服务
32+阅读 · 2020年2月26日
Arxiv
6+阅读 · 2018年3月27日
Arxiv
6+阅读 · 2018年1月28日



相关VIP内容
专知会员服务
87+阅读 · 2020年3月1日
专知会员服务
32+阅读 · 2020年2月26日
相关资讯
相关论文
Arxiv
6+阅读 · 2018年3月27日
Arxiv
6+阅读 · 2018年1月28日