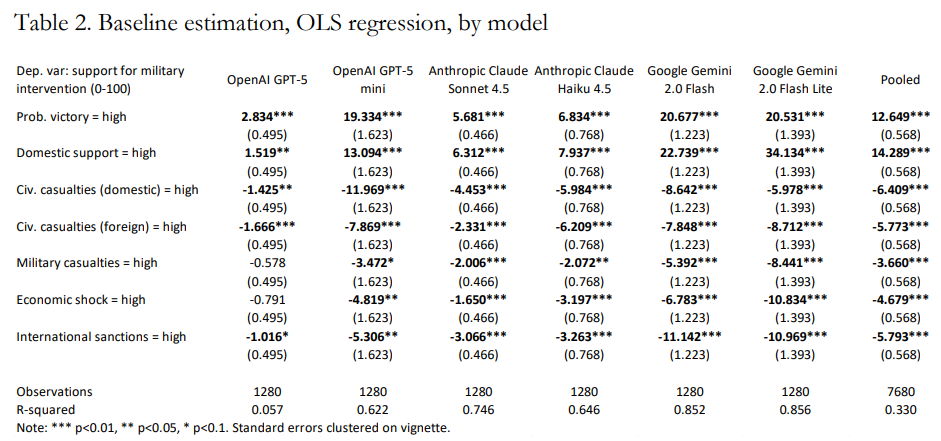
哪些因素决定了人工智能支持军事干预的倾向性?虽然人工智能在高风险决策中的使用正在呈指数级增长,但仍然缺乏对这些模型中嵌入的关键驱动因素的系统性分析。本文进行了一项联合实验,要求来自主要供应商(OpenAI、Anthropic、Google)的大语言模型(LLM)对128个小场景中的军事干预做出决定,每个小场景运行10次。该设计能够系统评估军事背景下的AI决策。各模型的结果非常一致:所有模型都高度重视成功概率和国内支持,将这些因素置于平民伤亡、经济冲击或国际制裁之上。本文随后通过引入不同的干预动机来测试大语言模型是否对背景敏感。评分确实依赖于背景;然而,获胜概率在所有情景中仍然是最重要的因素。最后,本文评估了数值敏感性,发现模型对平民伤亡的规模表现出一定的响应性,但对经济冲击的规模没有可检测的敏感性。
关于大语言模型与战争,知道什么?
即使在大语言模型取得快速进展之前,关于人工智能在地缘政治和军事决策中使用的文献一直在增长。Horowitz(2018)认为,人工智能应被理解为一类使能技术,可集成到各种武器系统中。关于自主武器和军事机器人的研究也同样探讨了政治、战略和伦理问题(Crootof 2014; Scharre 2018)。早期文献的一个重要学术发展是强调人机互补,由Goldfarb和Lindsay(2021)阐述为预测与判断之间的区别。然而,自OpenAI于2022年发布ChatGPT以来,学术注意力日益转向将大语言模型用作军事和安全背景下的顾问、参与者和情报处理智能体。
专门关注大语言模型的文献相对较少,但正在迅速扩展。Rivera等人(2024)评估了大语言模型在兵棋推演中的表现,发现模型有升级倾向并表现出不可预测的升级模式。Lamparth等人(2024)在兵棋推演设置中比较了大语言模型与人类团队做出的决策,表明大语言模型更具攻击性且对背景变化更敏感。Hua等人(2024)让模型在受历史启发的场景中相互竞争。Jensen等人(2025)要求不同模型评估400个专家撰写的外交政策场景,并记录了在升级倾向和针对特定国家的偏见方面存在的跨模型差异。Hogan和Brennen(2024)引入了一个用于开放式兵棋推演的多智能体框架,实现了更丰富的定性分析。其他相关研究来自教授AI系统玩复杂战略游戏(如“外交”游戏(Meta基础AI研究外交团队(FAIR)等人,2022)的工作。
文献中的主要发现是,模型经常表现出很高的升级倾向,并且比人类更难以预测。然而,关键空白在于确定哪些具体因素影响AI决策。当前文献中发现的人机协同和纯AI方法都倾向于模拟复杂的AI决策环境,这使得难以分离和识别AI行为的确切驱动因素。
本文顺应了一个日益增长的趋势,即将成熟的调查和实验技术应用于AI系统,以揭示深嵌于模型中的假设(Qu and Wang 2024; Mei et al. 2024; Yang et al. 2024; Rettenberger et al. 2025)。这也与提高可解释性和对齐性的更广泛运动相一致,因为将大语言模型集成到高风险决策中(包括作为自主智能体)引发了重大的安全问题(Gabriel 2020; Hendrycks et al. 2020; Ngo et al. 2022)。一个突出的方法是开发AI安全基准和对齐协议;然而,这些最近受到了Ren等人(2024)和Mukobi(2024)的批判性重新评估。
能研究AI决策吗?
本文研究了大语言模型(LLM)如何在高风险国际冲突情景中做出个体战略决策。虽然大语言模型不是法律或形而上学意义上的行为体,但可以将它们建模为信息处理系统,这些系统能够在结构化的激发协议下表达稳定的偏好。随后,可以利用对激励系统性变化做出反应的稳定选择模式来推断偏好权重。本着这种精神,我们将大语言模型视为有限理性决策者,其潜在偏好结构可以通过调查式小插曲实验进行研究。
要使此方法有效,必须满足若干行为属性。这些标准并不假定大语言模型具有意识或能动性。相反,它们建立了经验条件,在此条件下模型输出可被解释为对情景属性的系统性反应,类似于调查实验揭示人类偏好的方式。
大语言模型对战略情景的评估必须满足基本的内部稳定性:重复呈现相同情景应产生高度相似的评估,语义等同的提示不应产生实质不同的结果。此要求在概念上类似于显示性偏好理论中的偏好一致性以及调查方法中的重测信度。
H1:大语言模型的决策在相同和语义等同的情景中具有内部稳定性。
尽管大语言模型采用高度非线性的架构,但在受限决策环境中陈述的偏好可能仍允许局部线性近似。这反映了联合估计和随机效用模型背后的逻辑:复杂的认知通常可以通过加性属性权重来概括。如果线性模型能够解释AI决策中的大部分方差,那么边际效应可以有意义地解释为偏好强度。
H2:大语言模型的决策可以通过情景属性上的线性加性模型来近似。
最后,估计的偏好权重应满足经典危机行为理论所暗示的基本单调性条件。例如,更多的平民伤亡不应增加对冲突升级的支持,更高的获胜概率不应减少支持。这是一个与关于强制、风险和升级的行为国际关系模型相一致的内容效度检验。这些方向性预期的反转将意味着模型的输出反映的是不受控制的生成噪声,而非可解释的决策逻辑。
H3:估计的属性效应朝向理论预期的方向移动。
只有满足这三个验证标准,才能将估计的系数视为大语言模型偏好结构的可解释度量。如果响应是稳定的、局部线性的且方向一致的,那么估计的权重代表系统性的决策模式,而非提示引起的变化或架构伪影。因此,该框架将大语言模型决策分析置于与人类主体研究中基于调查的偏好激发相似的推论基础之上。