CVPR 2019| ILC:用于自然场景多目标的计数模型
加入极市专业CV交流群,与6000+来自腾讯,华为,百度,北大,清华,中科院等名企名校视觉开发者互动交流!更有机会与李开复老师等大牛群内互动!
同时提供每月大咖直播分享、真实项目需求对接、干货资讯汇总,行业技术交流。点击文末“阅读原文”立刻申请入群~
作者 | XiaoSean(注:作者栏写错)
来源 | https://xiaosean.github.io/
论文:Object Counting and Instance Segmentation with Image-level Supervision
链接:https://arxiv.org/pdf/1903.02494.pdf

简介
本文提出用于自然场景的计数模型,以往常见的计数模型是人群数测量,但自然场景测量与人群数测量的困难点不一样,人群数测量的问题中,人的数量通常很多,并且会有人与人之间的遮挡问题,但自然场景的计数模型的困难点为要学习不同种类 intra-class,除此之外一张图片还会出现不同种类多个物体的情况。而本文提出基于 Image-level 的方式训练,相较于以往需要(Instance-level / point-level / bounding box level)等等的训练方式来说,此模型只要有出现的类别以及各自的数量即可进行训练!还能够输出 Density map (可看作热力图),藉由 Density map 能得知其物体是出现在图片的哪个位置。并且使用几篇心理学为依据(这部分没去探究),大概就是说当人类看到一张照片有 1 ~ 4 个物件时,可以即时算出数量,不需要一个一个数。基于这个想法提出了一个物件数量限缩的训练方式,称作 ILC - Image-level lower-count (ILC) supervision。
架构
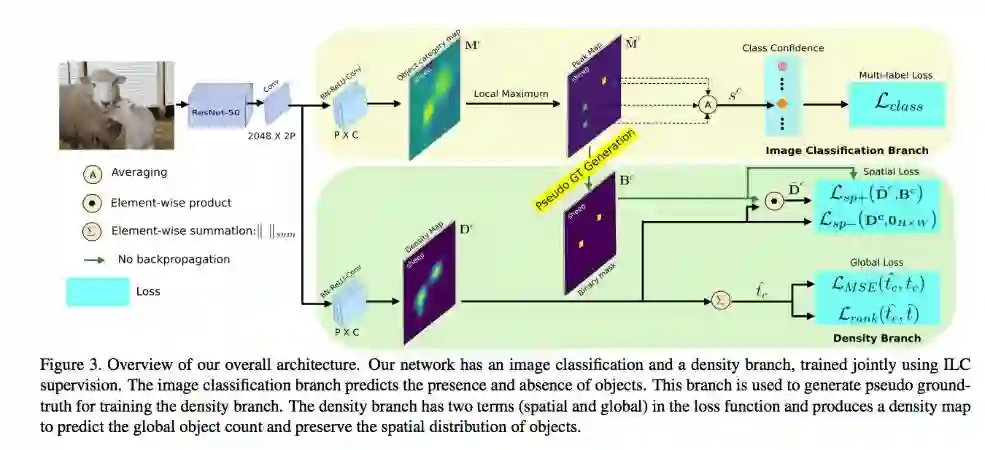
主要两个部分:
Image classification branch (上半部,用于分类)
Density map branch (下半部,用于计算数量)

Image classification branch
最基本的想法是透过 image classification branch 学习分类,而 CAM - Learning Deep Features for Discriminative Localization (https://arxiv.org/abs/1512.04150)以及 Grad-CAM: Visual Explanations from Deep Networks via Gradient-based Localization(https://arxiv.org/abs/1610.02391)两篇论文展示分类器会学到最能够辨别这个类别的区块,而上图的 Mc 就是分类器认为黄色的部分是较能够代表这个类别的区块。透过 CAM 的方法,我们其实没办法明确地将 Instances 分隔出来,单看黄色的部分,没办法很直觉的知道这张图片有几个羊。因此透过透过下面这个公式找出哪些位置可能高机率是一个物体.

举例来说辨认鸟的时候,CAM 的结果可能会集中(能量最强)在鸟嘴的部分,而上面就是用简单的方法找出哪个点是最强的点 - peak。透过这个方式我们可以将 Mc 转换成 M^c,使用 local maximum 的点,使用 multi-label soft-margin loss,就可以将每个物体的热力图分隔出来。(备注:local maxima (peaks) 细节请看CVPR2018论文Weakly Supervised Instance Segmentation using Class Peak Response)。
Density Branch
我们可以经由 Image classification branch 的分数得知哪些物件是有出现或是没出现,但是我们无法得知一张照片会出现多少数量的 instance,可能一张照片只有两只羊,但是看 Peak map 却有 10 几个点在上面的情况。
而我们的 Density map 就是希望能够画出图片中物件的位置,还要知道图片中出现几个物件。
定义 set
A: 此类别没有出现在这张图片
S: 此类别有出现 1 ~ 4 个物件
S+: 此类别有出现 5 个以上物件
因此提出 2 个 loss
Spatial loss
Lsp+ : 确保 peak map 的出现都是对应到一个物体 set {S}
Lsp- : 确保不会出现分类器没出现的类别数量 set {A}
而对于 set {S+} 我们就不会处理。( ILC 方法的特点)
Globle loss 确保整体物件数量一致
Lmse
Lrank
Spatial loss
确保物件能保留对应的空间信息。首先依照 GT 中该类别的数量 t 来提取出第 t 个高的 peak value 当作 hc,因此能确保产生出来的 Pseudo ground-truth 个数会等于实际出现的物件数量。
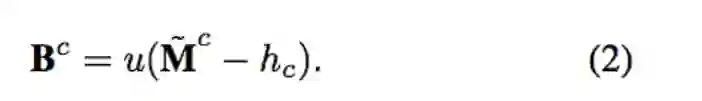
u(n) is the unit step function which is 1 only if n ≥ 0.
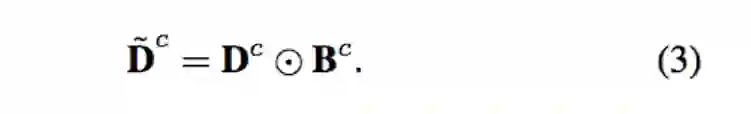
Lsp+ 使用 logistic BCE loss 让 Density map 可以相似 peak map,可使 Density map 的能量集中在该物件最能辨别的部分上。
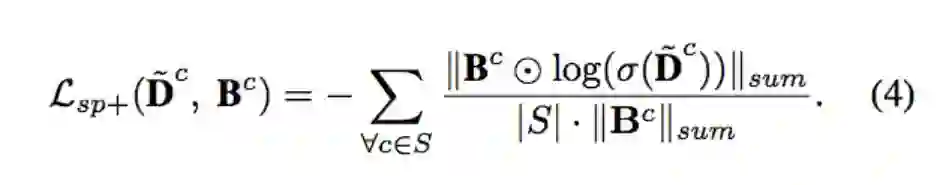
Lsp- 用 GT 提供的数量,针对没有出现的类别{A}将它所预测的 Density map 逼近于0,因此时所预测出的 Density map 都是误判的。
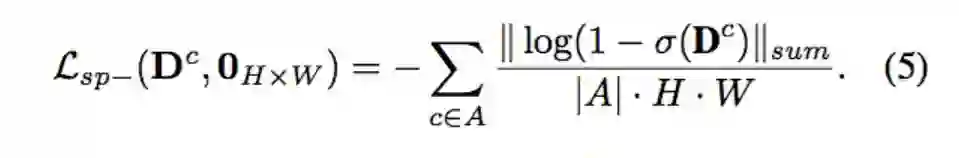
透过上述两个 Spatial loss 确保物件能保留对应的空间信息,主要是 Lsp+ 的部分。
Global Loss
确保预测出来的数量 t^c 是相当于 GT 的 tc。本文有趣的做法是将 Density map 的能量加总当作预测的数值。

Lmse: 让 Density map 的加总数量能趋近于 tc。
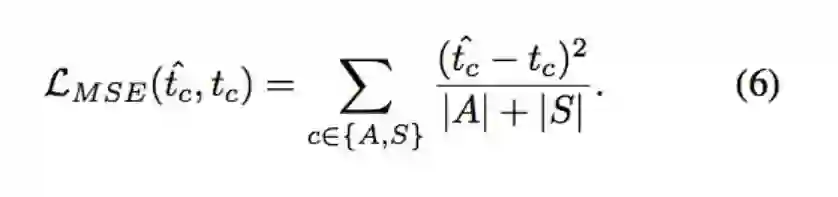
Lrank: 针对 {S+} 的类别,即为在图片中出现数量 5 以上的类别,我们希望我们所预测出的 t^c >= 5。
下方的 t^ = 5
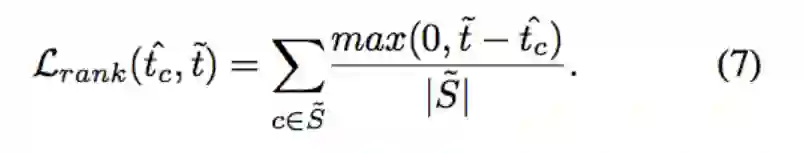
透过 Spatial loss 确定每个物件的空间信息,再透过 Global loss 的 MSE loss 确保其 density map 可以抓出物件的热力图,两个 loss 相互协调下就能达成定位 object instances 的功能。
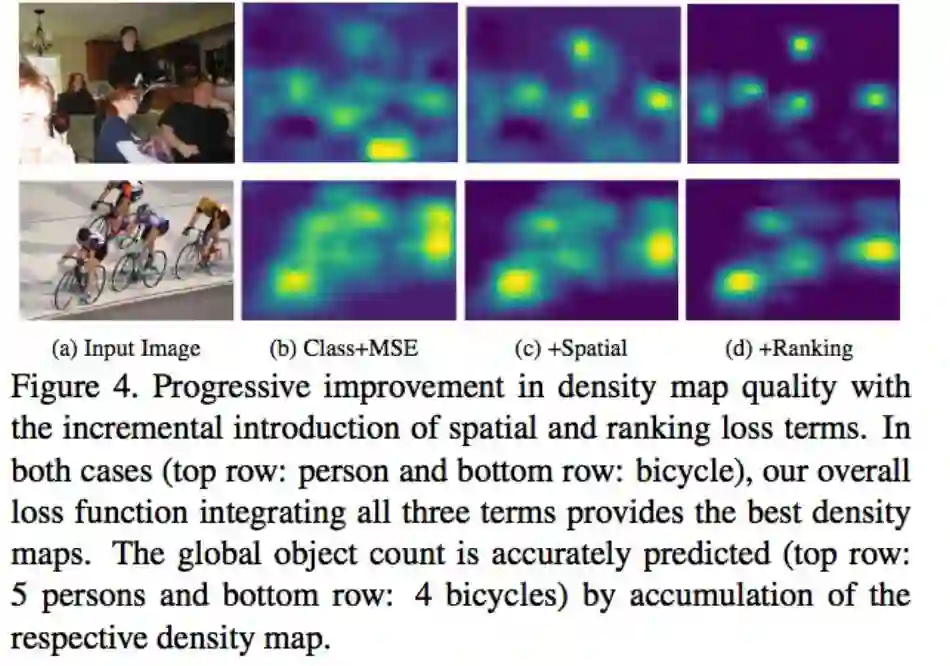
还有个特点是虽然我们的训练时只在 t <= 4 的时候做 mse loss,但最终在预测时,也能准确预测出超过 t(t=4) 个物件的类别。

备注:这张图应该是基于 PRM-Weakly Supervised Instance Segmentation using Class Peak Response 的方法,搭配 Spatial 以及 Global loss 去修改 PRM 的 Score matrix,才达到这个效果的。
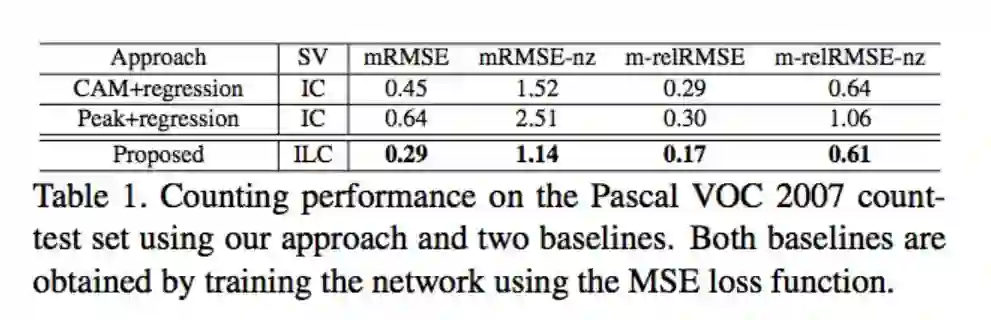
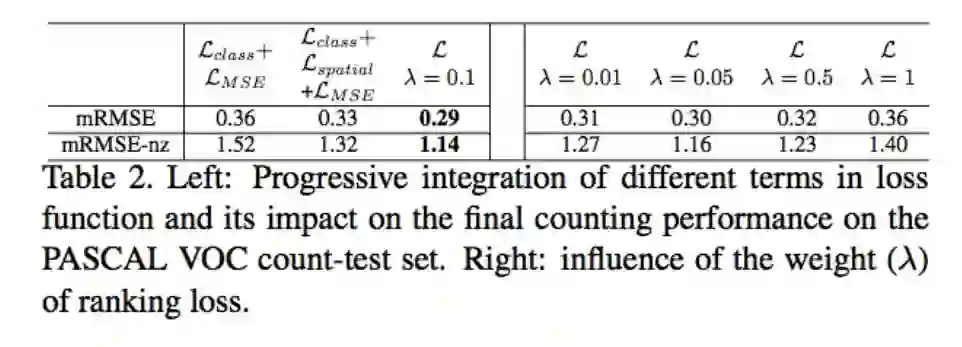
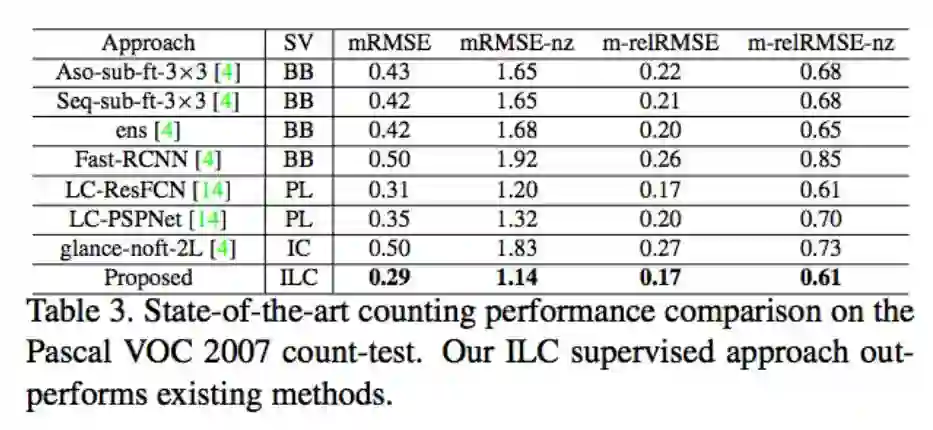
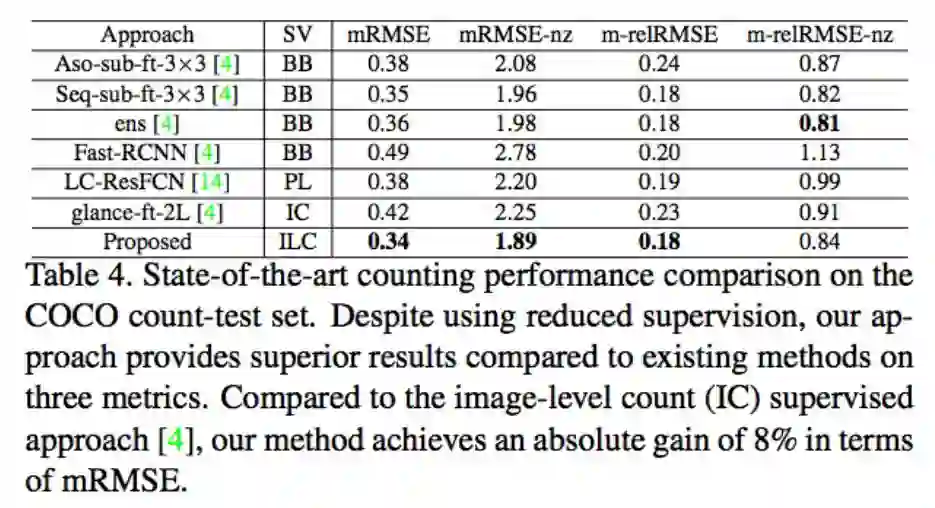
结果
ILC方法除了对于有遮挡到的还是没办法准确预测,其他结果看起来还不错。


参考论文
Object Counting and Instance Segmentation with Image-level Supervision
Weakly Supervised Instance Segmentation using Class Peak Response
Learning Deep Features for Discriminative Localization
Grad-CAM: Visual Explanations from Deep Networks via Gradient-based Localization
ps.CVPR2019 accepted list已经放出,极市已将目前收集到的公开论文总结到github上(目前已收集185篇),后续会不断更新,欢迎关注,也欢迎大家提交自己的论文:
https://github.com/extreme-assistant/cvpr2019
*延伸阅读
点击左下角“阅读原文”,即可申请加入极市目标跟踪、目标检测、工业检测、人脸方向、视觉竞赛等技术交流群,更有每月大咖直播分享、真实项目需求对接、干货资讯汇总,行业技术交流,一起来让思想之光照的更远吧~




