测量神经网络数据并行训练的局限性
在过去的十年中,神经网络已经在各种预测任务中实现了最先进的结果,包括图像分类,机器翻译和语音识别。这些成功至少部分是由显着加速神经网络训练的硬件和软件改进所驱动的。更快的培训直接导致模型质量的显着提高,既允许处理更多的培训数据,也允许研究人员更快地尝试新的想法和配置。今天,像云TPU Pod这样的硬件开发正在迅速增加可用于神经网络训练的计算量,这提高了利用额外计算的可能性,使神经网络训练更快,并促进模型质量的更大改进。但是我们究竟应该如何利用这种前所未有的计算量,我们是否应该总是期望更多的计算来促进更快的培训?
利用大量计算能力的最常用方法是在不同处理器之间分配计算并同时执行这些计算。在训练神经网络时,实现这一目标的主要方法是模型并行性,其涉及在不同处理器之间分布神经网络,以及数据并行性,其涉及跨不同处理器分发训练样例并且并行地计算神经网络的更新。虽然模型并行性使得训练大于单个处理器可支持的神经网络成为可能,但通常需要将模型架构定制为可用硬件。相比之下,数据并行性是模型不可知的并且适用于任何神经网络体系结构 - 它是用于并行化神经网络训练的最简单和最广泛使用的技术。对于最常见的神经网络训练算法(同步随机梯度下降及其变体),数据并行度的大小对应于批量大小,用于计算神经网络的每次更新的训练样本的数量。但是这种并行化的限制是什么,我们什么时候应该看到大的加速?
在“测量数据并行在神经网络训练中的作用”中,我们通过使用三种不同的优化算法(“优化器”)在七个不同数据集上运行六种不同类型的神经网络的实验来研究批量大小和训练时间之间的关系。总的来说,我们在约450个工作负载上培训了超过100K的单个模型,并观察到我们测试的所有工作负载之间的批量大小和培训时间之间看似普遍的关系。我们还研究了这种关系如何随数据集,神经网络架构和优化器而变化,并发现工作负载之间的差异非常大。此外,我们很高兴分享我们的原始数据,供研究界进一步分析。数据包括超过71M的模型评估,以构成我们训练的所有100K +个体模型的训练曲线,并可用于重现我们论文中的所有24个图。
批量大小与训练时间的普遍关系
在理想化的数据并行系统中,处理器之间的时间同步可以忽略不计,训练时间可以通过训练步骤的数量来测量(神经网络参数的更新)。在此假设下,我们在批量大小和培训时间之间的关系中观察到三种不同的缩放制度:“完美缩放”制度,其中批量大小加倍,达到目标样本外错误所需的训练步骤数减半,其次 通过“收益递减”制度,最后是“最大数据并行”制度,即使假定理想化的硬件,进一步增加批量大小也不会减少培训时间。
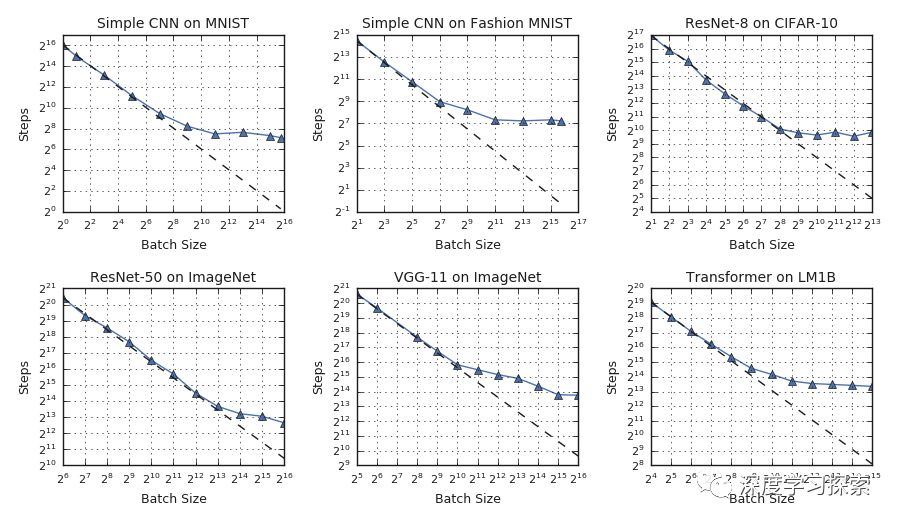
对于我们测试的所有工作负载,我们观察到批量大小和训练速度之间的普遍关系,具有三种不同的方案:完美缩放(沿着虚线),收益递减(从虚线偏离)和最大数据并行性(趋势平台))。 各制度之间的过渡点在不同的工作量之间变化很大。
虽然批量大小和训练时间之间的基本关系似乎是普遍的,但我们发现不同缩放机制之间的转换点在神经网络架构和数据集之间变化很大。这意味着虽然简单的数据并行可以在当今硬件(例如,云TPU Pod)的限制下为某些工作负载提供大的加速,并且可能超出,但是一些工作负载需要超越简单的数据并行,以便从存在的最大规模的硬件中受益今天,更不用说尚未建立的硬件。例如,在上图中,CIFAR-10上的ResNet-8无法从大于1,024的批量大小中受益,而ImageNet上的ResNet-50继续受益于将批量大小增加到至少65,536。
优化工作量
如果可以预测哪些工作负载从数据并行培训中受益最多,那么可以定制其工作负载以最大限度地利用可用硬件。但是,我们的结果表明这通常不是直截了当的,因为最大有用批量大小至少在某种程度上取决于工作负载的每个方面:神经网络体系结构,数据集和优化器。例如,某些神经网络架构可以从比其他架构更大的批量大小中受益,即使在使用相同优化器对相同数据集进行训练时也是如此。虽然这种影响有时取决于网络的宽度和深度,但它在不同类型的网络之间是不一致的,并且一些网络甚至没有明显的“宽度”和“深度”概念。虽然我们发现某些数据集可以从比其他数据集更大的批量大小中受益,但这些差异并不总是由数据集的大小来解释 - 有时较小的数据集从较大的批量大小中获益比较大的数据集更多。
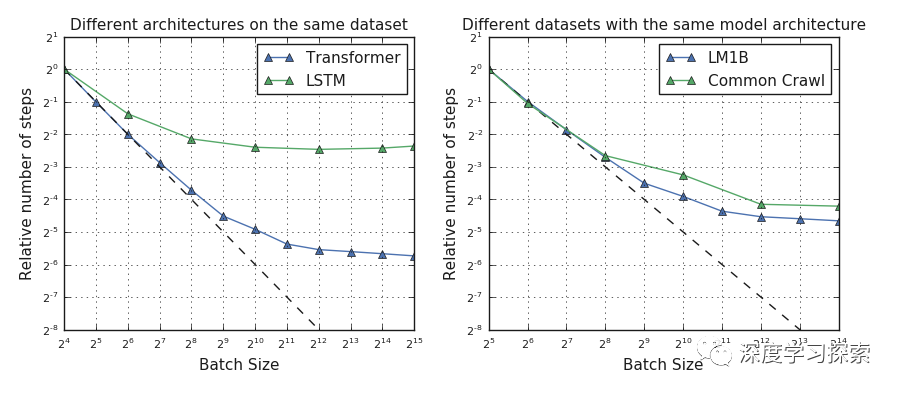
左图:变换器神经网络比LM1B数据集上的LSTM神经网络扩展到更大的批量大小。 右图:Common Scrawl数据集不会受益于比LM1B数据集更大的批量大小,即使它是大小的1,000倍。
也许我们最有希望的发现是,即使是优化算法的微小变化,例如允许随机梯度下降的动量,也可以显着改善训练随着批量增加而缩放的程度。这提高了设计新优化器或测试我们未考虑的优化器的缩放属性的可能性,以找到可以最大限度地利用增加的数据并行性的优化器。
未来的工作
通过增加批量大小来利用额外的数据并行性是在一系列工作负载中产生有价值的加速的简单方法,但是,对于我们尝试的所有工作负载,优势在最先进的硬件限制内减少。然而,我们的结果表明,一些优化算法可能能够在许多模型和数据集中一致地扩展完美的缩放机制。未来的工作可以与其他优化器一起执行相同的测量,除了我们尝试过的几个密切相关的优化器,看看是否有任何现有的优化器扩展了许多问题的完美扩展。
如果你是一个喜欢关注技术脉搏的人,请在我们的下面留言
微信公众号在我们消遣娱乐之余,它是一个非常好的学习手段与途径,利用好它,必将有所裨益,祝福每个小白都能在AI的这条光明大路上爱(AI)上Ta!


