【深度干货】专知主题链路知识推荐#9-机器学习中的变分推断方法(Variational Inference)简介02
【导读】主题链路知识是我们专知的核心功能之一,为用户提供AI领域系统性的知识学习服务,一站式学习人工智能的知识,包含人工智能( 机器学习、自然语言处理、计算机视觉等)、大数据、编程语言、系统架构。使用请访问专知 进行主题搜索查看 - 桌面电脑访问www.zhuanzhi.ai, 手机端访问www.zhuanzhi.ai 或关注微信公众号后台回复" 专知"进入专知,搜索主题查看。今天给大家继续介绍我们独家整理的机器学习——机器学习中的变分推断方法(Variational Inference)简介。
今天的变分推断专题邀请到中科院自动化研究所博士生ylfzr同学来分享他关于机器学习中变分推断方法的简介教程,这一部分理论由于图模型和变分自编码器等等也变得越来越重要,计划推出一系列关于变分推断方法的教程,敬请期待!
在变分推断方法简介01 中,昨天有读者指出公式3的一处错误,我们在这部分进行一个详细的修改:
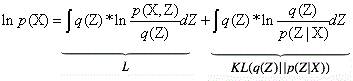
公式后边第一项和第二项大家可以进行尝试一下(有很多教程用Jensen 不等式以及KL散度的公式来得到这两个式子,其实只需要把公式右边两个式子进行变换一下就可以得到这个等式,具体如下),
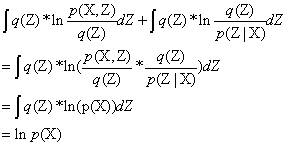
接着前面的变分推断方法简介01,今天02这部分细致地讲述常见的基于均值场方法的变分推断思路,并且举两个例子 一元高斯分布 和 LDA来具体说明如何求解。
2.3 基于均值场的变分推断(Mean Field)
在传统的变分推理方法中,均值场是最为常用的一种。基于均值场的变分推理对隐含变量做了独立性假设。这样可以使得推理计算的过程变得简单高效。假设我们将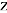
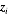
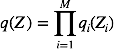
在所有具有上式形式的概率分布q(Z)中,我们寻找使变分下界下界L(q)最大的概率分布。我们可以得到对每个变量组的最优解的形式:
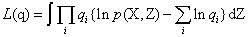
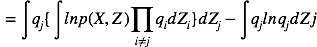
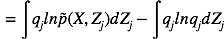
其中,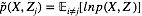
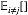
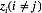
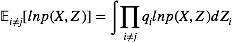
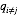
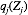

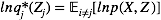
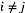
由该式给定的方程的集合(其中j = 1, . . . , M)表示在均值场假设下,变分下界达到极值时,最优的近似后验分布因子满足的一组条件。然而,这并不是一个显式的解,因为最优化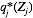
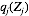
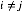
因此,我们初始化每个因子后交替迭代更新。该算法保证收敛,因为ELBO关于每个因子
上述结果有时也写为:
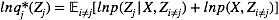
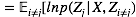
这个表达形式的好处在于我们可以略去很多可以被吸收到常数中的项不去计算,而只计算我们需要的,与变量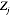
2.4一元高斯分布(传统共轭模型)
例子:一元高斯分布(传统共轭模型)
现在我们使用一元高斯变量x 来说明均值场变分估计的方法:我们的目标是在给定x的观测值的数据集D = {x1,…,xN}的情况下,推断其均值(mean)μ和精度(precision)τ的后验概率分布。我们假设数据是独立地从高斯分布中抽取的。
似然函数为:
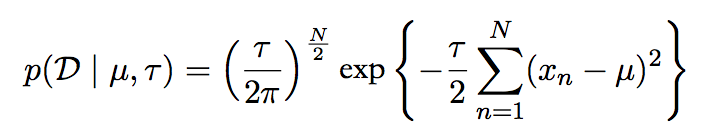
而参数的先验分布为:
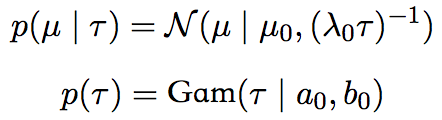
我们采用了共轭的先验分布。事实上对于这个简单的问题,我们可以精确地求出该模型的后验,其形式任然是高斯-Gamma分布。这里我们仍然采用变分推理来求解。 使用均值场条件,我们将近似的后验概率写为:
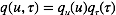
现在我们利用均值场近似的更新准则, 由式 (4)
对于
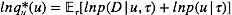
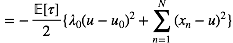
对于u 配平方, 我们可以得到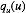
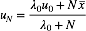
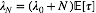
其中,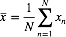
类似地, 对于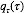
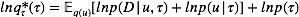
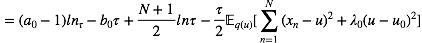
观察该形式我们发现该分布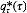
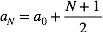
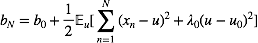
循环这(6)(7)两个因子的更新近似后验的分布我们可以达到收敛。 结果就是一个ELBOL的局部最优值。
注意该模型是一个传统的共轭模型,共轭结构可以帮助我们获得ELBO中期望的解析表达,进而得到在均值场条件下近似后验概率的具体形式。类似这样的共轭模型可以帮助我们解决大量的问题,比如线性高斯模型(Linear Guassian Models),混合高斯模型(Guassian Mixture), 线性动力系统(Linear Dynamical Systems),LDA(Latent Dirchilet Allocation) 等。
2.5 基于变分推断的LDA模型求解
前面的介绍中, 我们已经了解了LDA模型,并且使用了吉布斯(Gibbs Sampling)采样来对模型进行求解,具体可以参考主题模型系列教程。然而,在Blei等初始提出LDA时,采用的是我们现在所讲的均值场变分推理。Gibbs0 Sampling虽然简单且效果不错(无限计算资源的情况下可以保证收敛到真实后验分布),但是它花费的计算资源太过巨大而且实践中我们常常无法判断何时采样收敛。变分方法不依赖于采样技术,直接求解近似后验的参数,比Gibbs Sampling更加适用于大规模数据的应用场景。
现在我们就来介绍利用上面所讲的方法来对LDA进行求解。(模型参数以及定义参见前文)
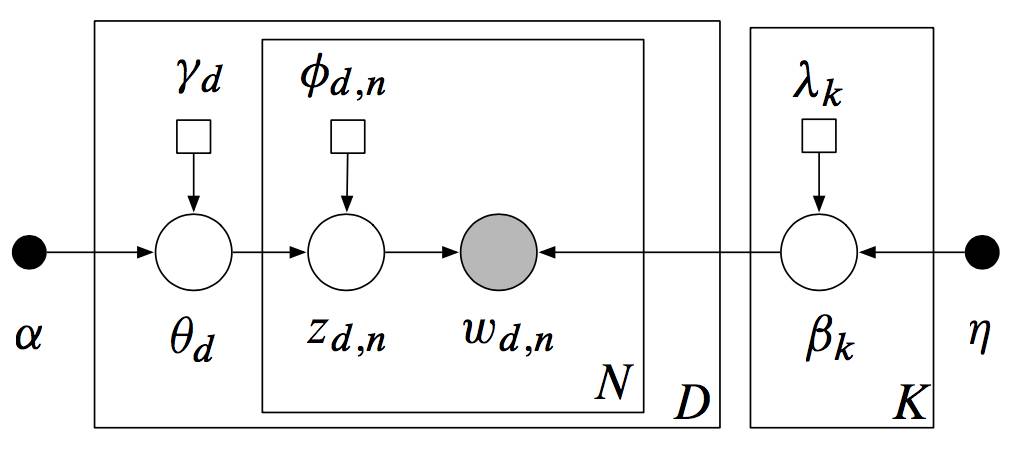
首先我们回顾一下LDA的模型结构及其产生式过程(Generative Process):
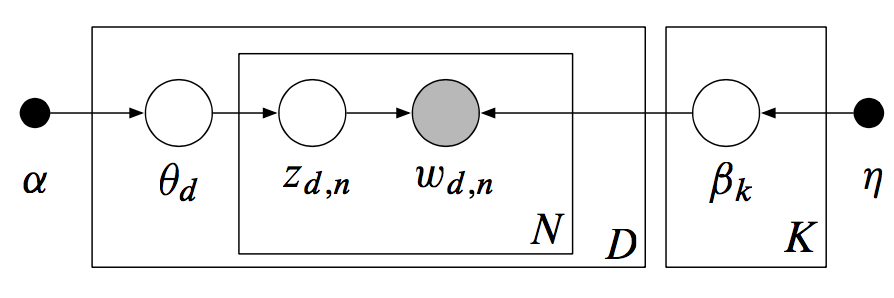
图: LDA模型
如上图所示, 用LDA模型模拟文档产生的过程为:
从狄里克雷分布先验
中采样生成文档d的主题分布
;
从主题的多项式分布中采样生成文档d的第j个词的主题
;(实际是 Categorical分布)
从狄里克雷分布中采样生成主题
对应的词语分布
;
从词语的多项式分布中采样最终生成的词语
。
其联合概率为:(8)
其中, 即为以
为参数的狄里克雷分布,
为以
为参数的狄里克雷分布,
为以
为参数的多项式分布。

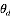
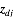
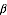
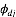
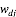
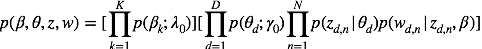
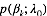
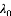
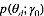

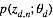
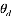
求解LDA的过程与此相反, 即利用我们已有的语料训练获取各个隐含变量的后验概率分布:
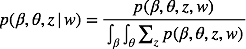
明显分母上的大量积分求和使我们不能承受的,我们采用均值场变分推理,用来近似后验的概率分布为:
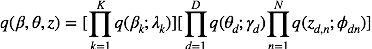
注意我们对近似后验的每个变量都进行了独立性假设(mean field),这会为我们的求解带来很大的便利。同时,我们在设计模型时候采用的共轭结构已经隐含地帮我们确定了各个部分最佳的近似形式:
即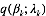
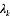

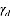
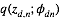
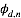
首先我们确定我们所要推理的隐含变量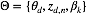
现在我们对要进行近似的各个部分分别进行处理,正如我们在之前的例子里所做的。
对于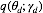
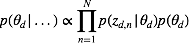
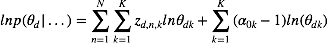
将上述结果带入式(5)我们得到:
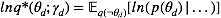
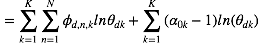
其中,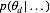
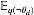
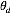
观察上式我们发现该分布仍然是一个多项分布,其新的参数为:
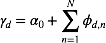
对于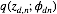
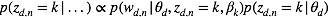
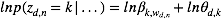
将上述结果带入式(5)我们得到:
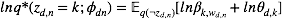
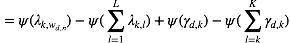
这仍然是关于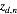
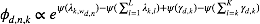
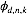
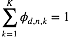
时,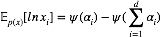
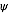
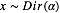
对于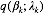
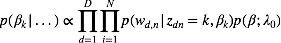
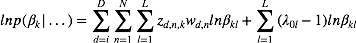
将上述结果带入式(5)我们得到:
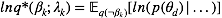
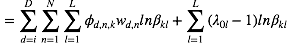
观察上式我们发现该分布仍然是一个多项分布,其新的参数为:
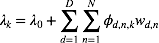
对于LDA的推理, 我们采用的步骤与[2]中略为不同。
[2]中在确定均值场近似后验形式(9)后, 直接将其带入ELBO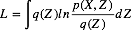
大家可以将我们推导的结果与LDA原文中的对比。 二者的结果是相同的,我们的方法利用了均值场的通解形式(4),整个求解过程变得更为简单。徐亦达老师也在自己的讲义[4]中给出了变分LDA的详细推导过程。这种方法利用了指数族(Exponential Family)的性质。可以直接求解近似后验的最优参数。
利用类似的方法我们可以求解很多问题。但是在实际应用中我们仍然会遇到很多问题:如果我们的数据集很大,求解所需时间太长怎么办? 如果我们的数据是逐渐流入的,我们如何搭建一个在线(online)的推理方法? 如果我们的模型不具有共轭的性质(实际上,现在我们常常会遇到非共轭的模型, 如贝叶斯神经网(Bayesian Neural Networks),深度非线性高斯模型(Deep Latent Guassian Models), 非线性时序模型(None Linear Time Series Models)等), 我们无法计算ELBO(无法解析地计算关于近似后验的期望)时,我们又该怎么怎么办呢? 请关注我们的后续内容。
参考资料
[1] C.Bishop “Pattern Recognition and Machine Learning” 2006
[2] D.Blei A.Ng M. Jordan Latent Dirichlet Allocation[M]. JMLR.org, 2003.
[3] Y.Gal Uncertainty in Deep Learning 2016
[4] 徐亦达 Statistical Notes
http://www-staff.it.uts.edu.au/~ydxu/statistics.htm
[5] NIPS 2016 tutorial: Variational Inference: Foundations and Morden Methods
上面就是关于机器学习中变分推断方法的一个简介,更详细完整请登录www.zhuanzhi.ai 搜索访问。后续会不断推出它的一系列应用教程,原创不易,请多多支持,有什么问题可以在我们的专知公众号平台上交流或者加我们的专知-人工智能交流群 426491390
欢迎使用专知!点击阅读原文即可访问,获取更多AI知识资源。同时请关注我们的公众号,获取最新关于专知以及人工智能的资讯、技术、算法等内容。





