【南洋理工-Bengio新论文】图神经网络基准化-如何构建强大GNN模型?
【导读】图神经网络依然是当下的研究热点。来自新加坡南洋理工大学Xavier Bresson和Bengio联合发布了一篇论文《Benchmarking Graph Neural Networks》,如何构建强大的GNN成为了核心问题。什么类型的架构、第一原则或机制是通用的、可推广的、可伸缩的,可以用于大型图数据集和大型图数据集? 另一个重要的问题是如何研究和量化理论发展对GNNs的影响?基准测试为回答这些基本问题提供了一个强有力的范例。作者发现,准确地说,图卷积、各向异性扩散、残差连接和归一化层是开发健壮的、可伸缩的GNN的通用构件。

https://arxiv.org/abs/2003.00982
本文的贡献如下:
我们发布了一个基于PyTorch (Paszke et al., 2019)和DGL (Wang et al., 2019)库的基于GitHub的GNNs开放基准基础架构。我们专注于新用户的易用性,使新数据集和GNN模型的基准测试变得容易。
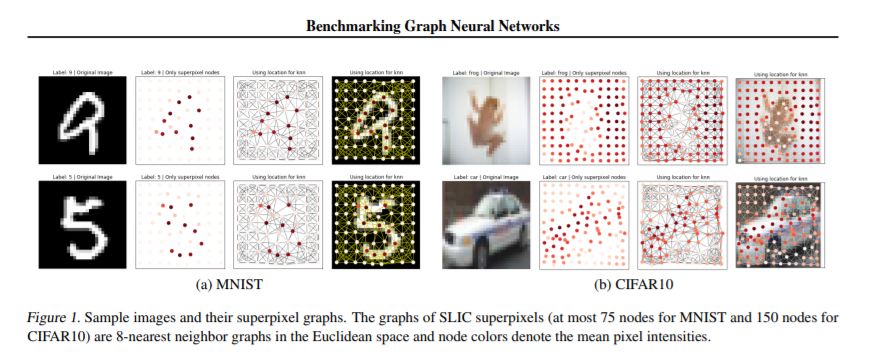
我们的目标是超越流行的小型CORA和TU数据集,引入中等规模的数据集,其中包含12k-70k图,节点大小为9-500个。提出的数据集包括数学建模(随机块模型)、计算机视觉(超级像素)、组合优化(旅行商问题)和化学(分子溶解度)。
我们通过建议的基准测试基础设施来确定重要的GNN构建块。图卷积、非istropic扩散、残差连接和归一化层对设计高效的GNN非常有用。
我们的目标不是对已发布的GNN进行排名。为特定的任务寻找最佳模型在计算上是昂贵的(并且超出了我们的资源),因为它需要使用交叉验证对超参数值进行彻底的搜索。相反,我们为所有模型确定了一个参数预算,并分析性能趋势,以确定重要的GNN机制。
数值结果完全可重复。通过运行脚本,我们可以简单地重现报告的结果。此外,基准基础设施的安装和执行在GitHub存储库中有详细的说明。
我们学到了什么关于GNN?
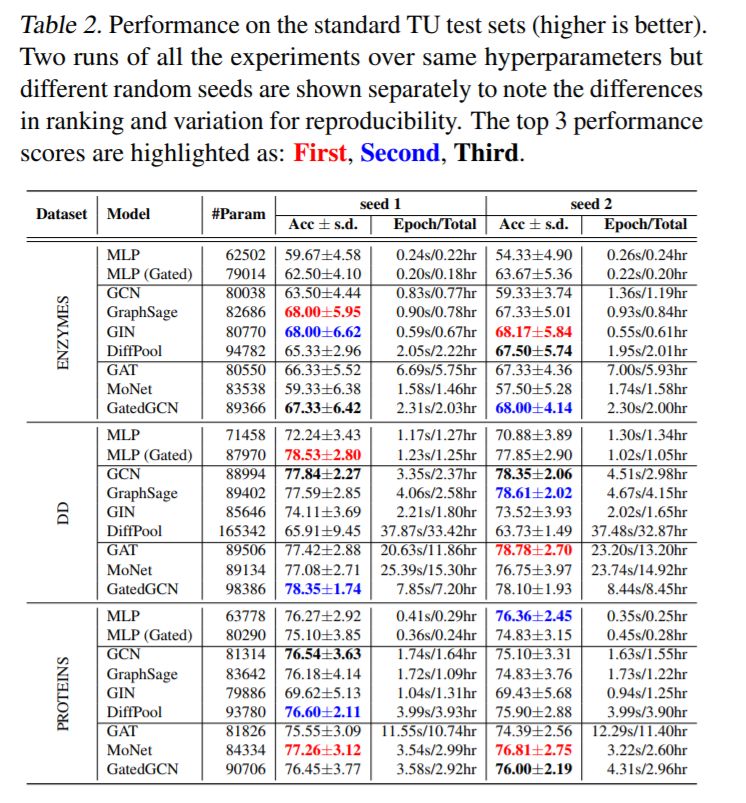
与图形无关的NNs (MLP)在小型数据集上的表现与GNNs一样好。表2和表3显示,对于小型TU数据集和(简单的)MNIST,使用GNNs而不是不依赖于图的MLP基线并没有显著的改进。此外,MLP有时比GNNs做得更好(Errica等,2019;Luzhnica等人,2019年),例如用于DD数据集。
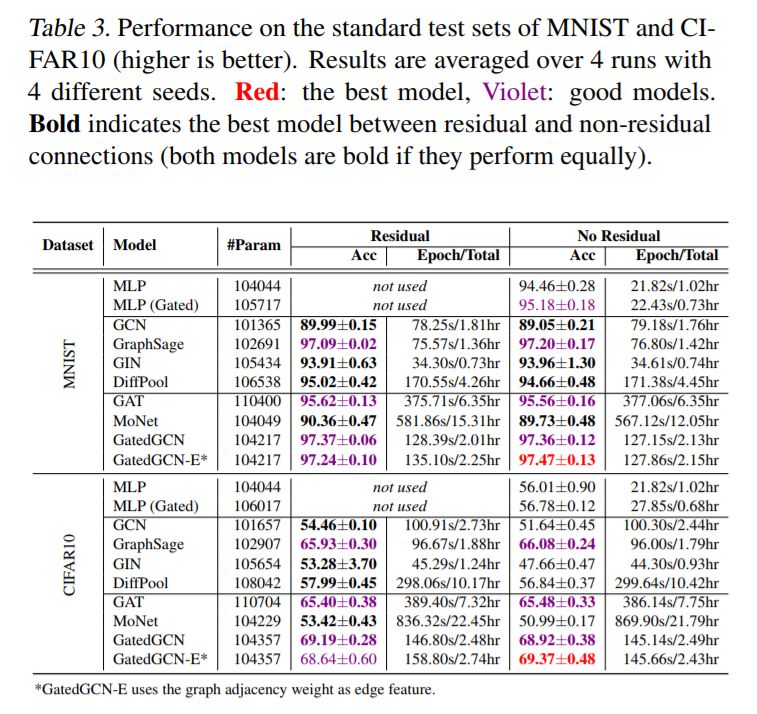
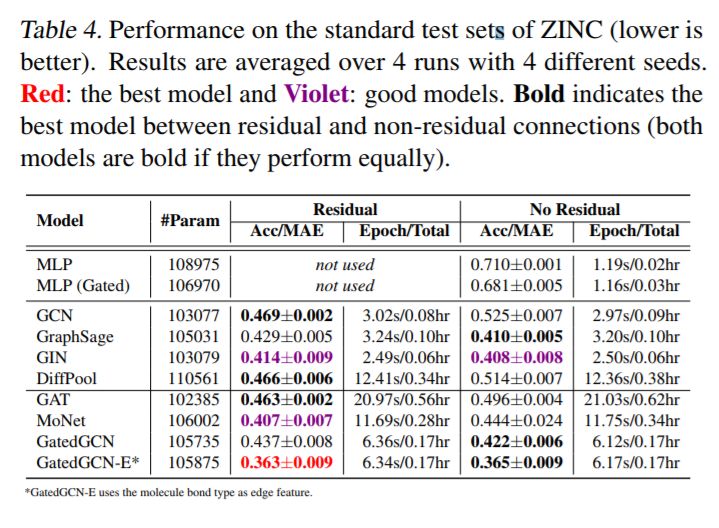
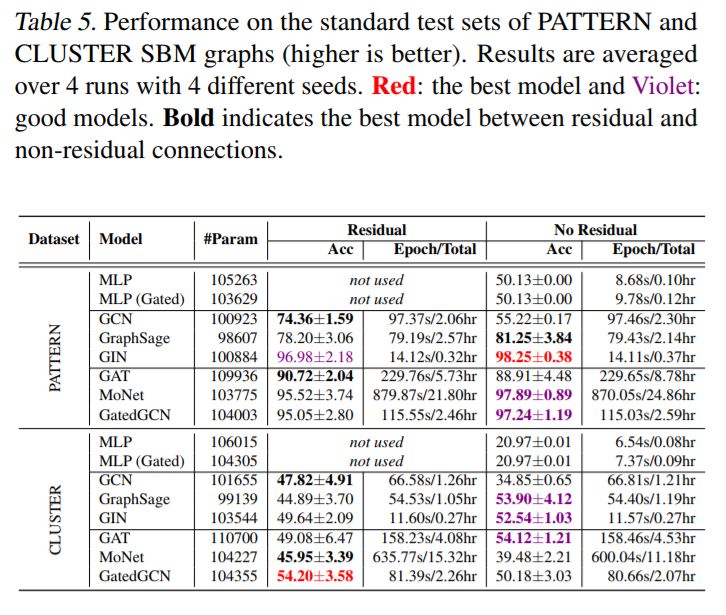
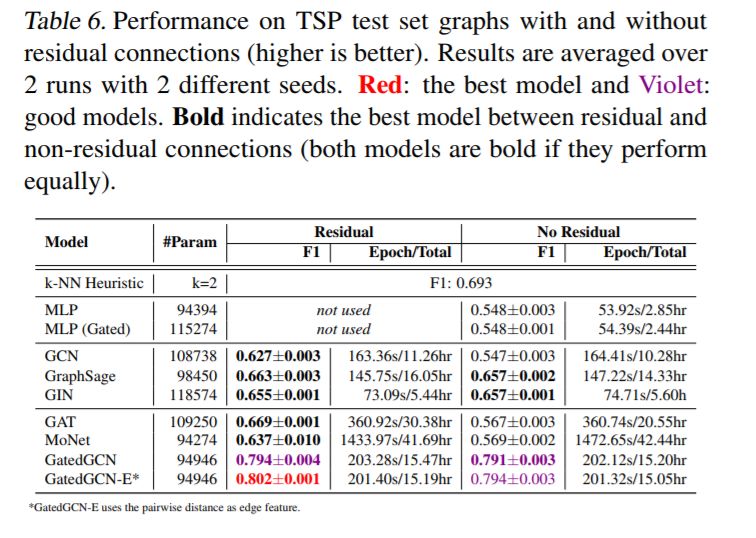
对于更大的数据集,GNN超越了与图形无关的NNs。表4和表5显示了ZINC, PATTERN, 和CLUSTER 数据集的显著性能提升,其中所有GNN都大大优于两个MLP基线。表6显示,所有使用残差连接的GNN都超过了TSP数据集的MLP基线。表3中报告的CIFAR10数据集的结果差别不大,尽管最好的GNN的性能明显优于mlp。
Vanilla GCNs (Kipf & Welling, 2017)表现不佳。GCNs是GNN最简单的形式。它们的节点表示更新依赖于邻域上的各向同性平均操作,即式(1)。在(Chen et al., 2019)中分析了这一各向同性特性,结果表明无法区分简单的图结构,这解释了GCNs在所有数据集上的低性能。
新的各向同性的GNN体系结构改进了GCN。GraphSage (Hamilton et al., 2017)论证了在图卷积层(Eq.(2))中使用中心节点信息的重要性。GIN (Xu et al., 2019)也采用了中心节点特征Eq.(3),以及在所有中间层连接到卷积特征的新分类器层。DiffPool (Ying et al., 2018)考虑一个可学习的图形池操作,其中GraphSage用于每个分辨率级别。这三个各向同性的GNN显著地提高了除了CLUSTER之外的所有数据集的GCN性能。
各向异性GNN是准确的。各向异性模型,如GAT (Velickovi ˇ c et al. ´ , 2018), MoNet (Monti et al., 2017) and GatedGCN (Bresson & Laurent, 2017) 在每个数据集获得最好的结果。另外,我们注意到GatedGCN在所有数据集上都表现良好。与各向同性的GNNs主要依赖于对相邻特征的简单求和不同,各向异性的GNNs使用复杂的机制(GAT的稀疏注意机制、GatedGCN的边缘门),这些机制很难有效地实现。我们为这些模型编写的代码并没有得到充分的优化,因此,速度要慢得多。这类GNN的另一个优点是它们能够明确地使用边缘特征,比如分子中两个原子之间的键类型。在表4中,对于ZINC分子数据集,使用键边特征的GatedGCN- e显著改善了没有键的GatedGCN的MAE性能。
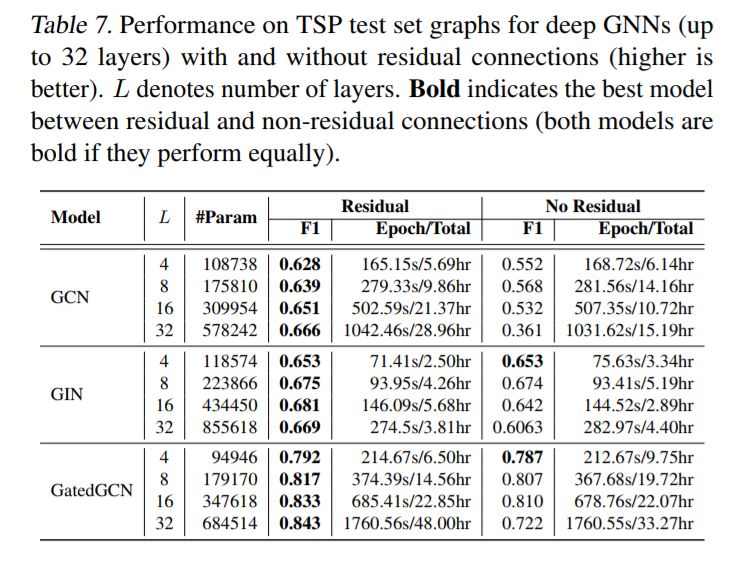
残差连接可以提高性能。(He et al., 2016)中引入的残差连接(Residual connections, RC)已经成为计算机视觉深度学习体系结构的普遍组成部分。使用残差连接以两种方式帮助GNN。首先,它限制了在深度网络中反向传播时的消失梯度问题。其次,它允许在GCN和GAT等模型中包含卷积过程中的自节点信息,而这些模型并没有明确地使用它们。
我们首先用L = 4层来测试RC的影响。对于MNIST(表3),RC并没有改善性能,因为大多数gnn很容易对该数据集进行过度拟合时。对于CIFAR10, RC增强了GCN、GIN、DiffPool和MoNet的结果,但对GraphSAGE、GAT和GatedGCN的性能没有帮助或降低。对于ZINC(表4),添加残差显著改善了GCN、DiffPool、GAT和MoNet,但略微降低了GIN、GraphSage和GatedGCN的性能。对于PATTERN和CLUSTER(表5),GCN是唯一明显受益于RC的体系结构,而其他模型在RC存在时可以看到其准确性的增加或减少。对于TSP(表6),没有隐式使用自我信息(GCN、GAT、MoNet)的模型受益于跳过连接,而其他gnn的性能几乎相同。
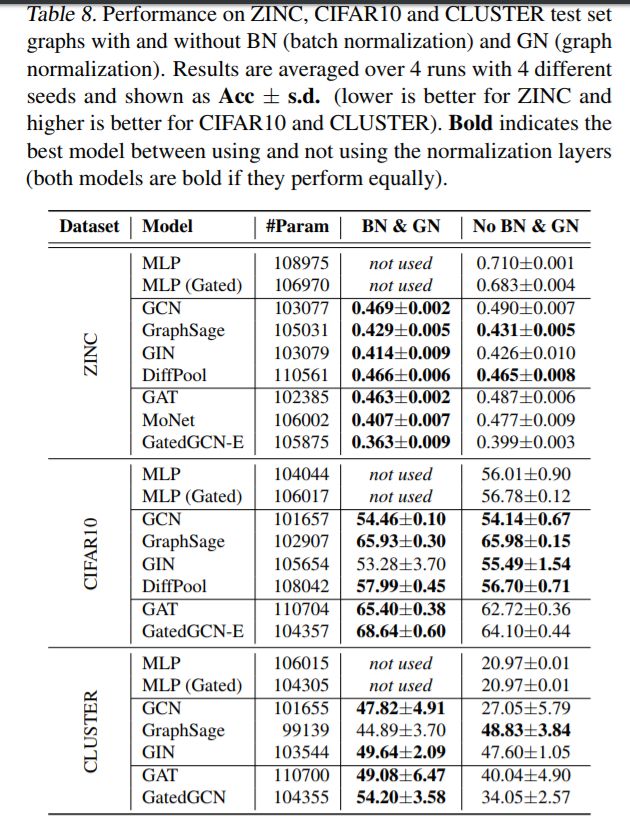
规范化层可以改进学习。大多数现实世界中的图形数据集都是具有不同大小的不规则图形的集合。不同规模的批处理图可能导致不同规模的节点表示。因此,规范化激活有助于提高学习能力和泛化能力。我们在实验中使用了两个标准化层—来自(Ioffe & Szegedy, 2015)的批处理标准化(BN)和图尺寸标准化(GN)。图尺寸标准化是一种简单的操作。
我们在表8中评估了标准化层对ZINC、CIFAR10和CLUSTER数据集的影响。对于这三个数据集,BN和GN显著改善GAT和GatedGCN。此外,BN和GN对ZINC和CLUSTER簇的GCN性能有促进作用,但对CIFAR10的GCN性能没有改善。除了集群之外,GraphSage和DiffPool不会从规范化中受益,但不会损失性能。总之,规范化层对于设计完善的gnn非常重要。
专知便捷查看
便捷下载,请关注专知公众号(点击上方蓝色专知关注)
后台回复“GNNB” 就可以获取《南洋理工大学课程Xavier -图神经网络教程,Graph Neural Networks,附121页PPT》专知下载链接





