Google最新《高效Transformers》2022综述大全,39页pdf阐述九大类提升Transformers效率方式
Transformer模型是当下的研究焦点。最近 Google Yi Tay发布了关于Transformers最新论文,提供这类模型的最新进展的全面概述。

摘要
https://www.zhuanzhi.ai/paper/39a97bd373cc6f37c6b2e9026f3422e8
介绍
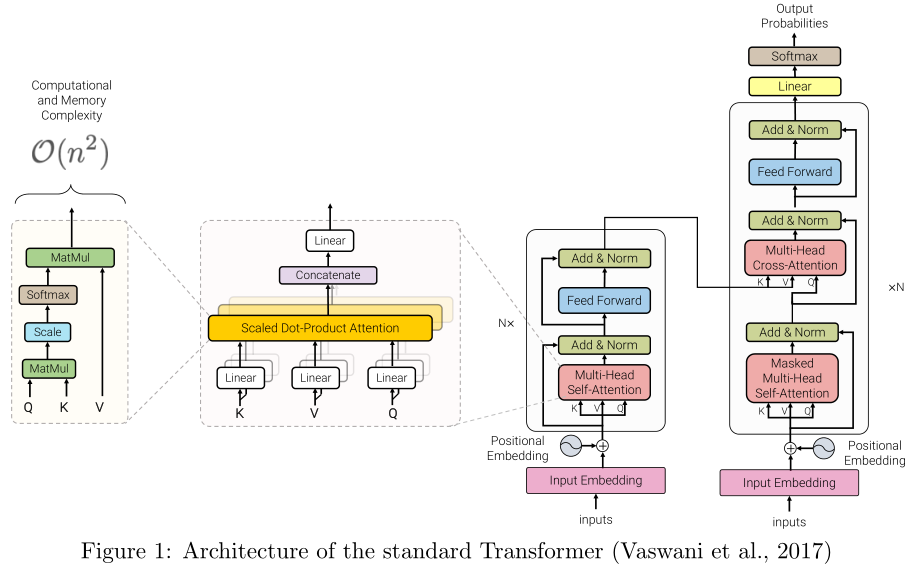
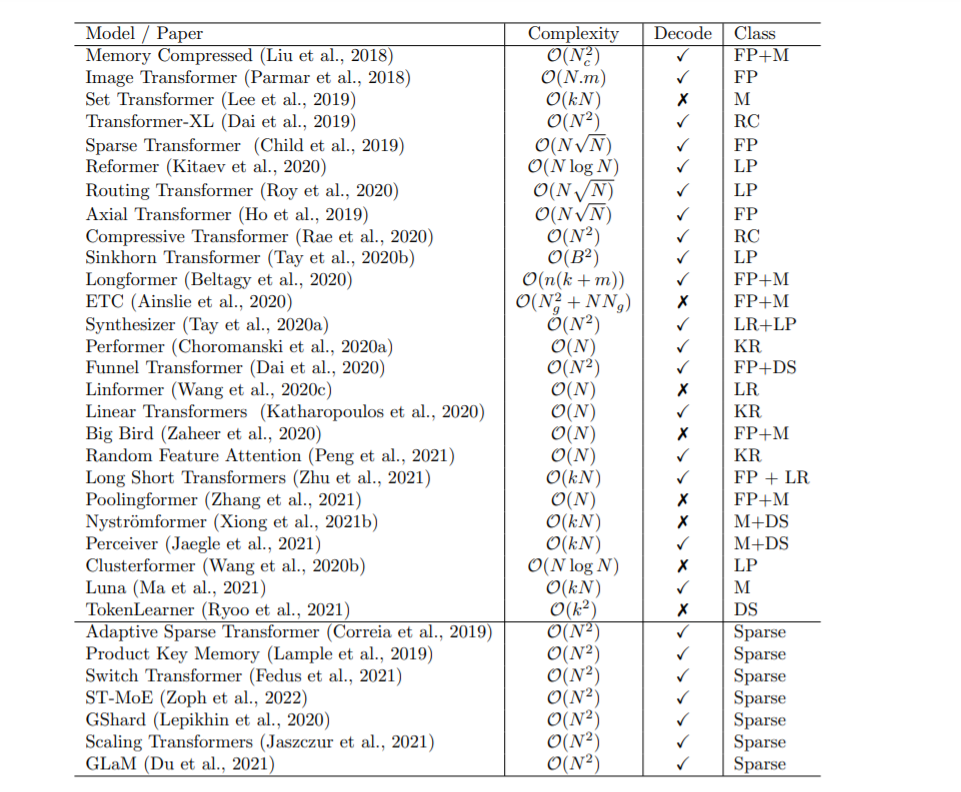
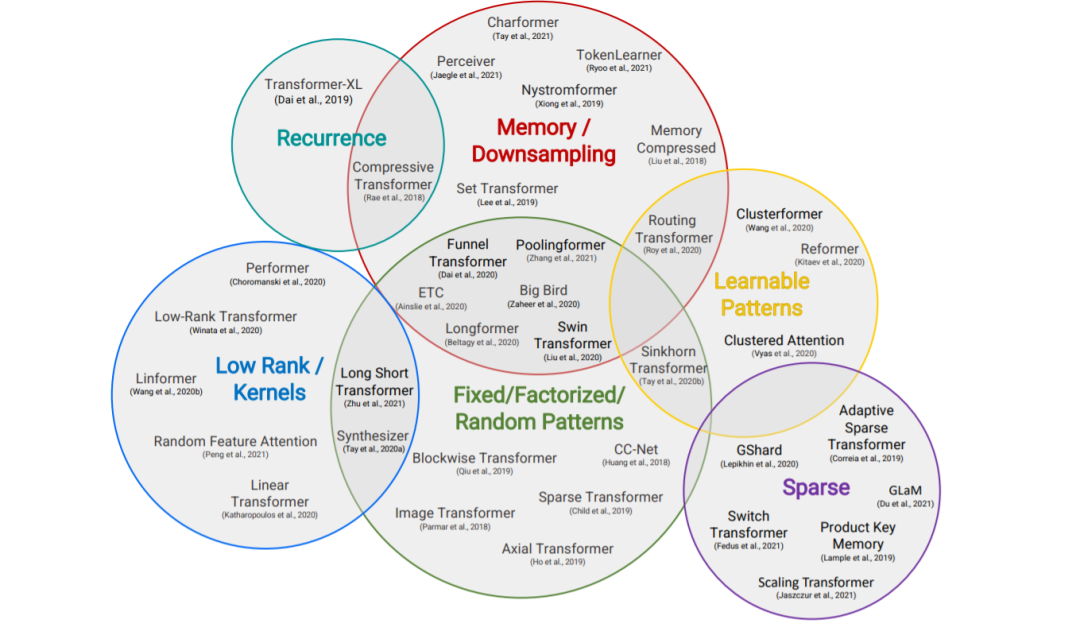
本节概述了高效Transformer模型的一般分类,以其核心技术和主要用例为特征。尽管这些模型的主要目标是提高自注意机制的内存复杂度,但我们还包括了提高Transformer体系结构的一般效率的方法。
固定模式(FP)——对自注意最早的修改是通过将视野限制在固定的、预定义的模式(如局部窗口和固定步距的块模式)来简化注意力矩阵。
组合模式(CP)——组合方法的关键思想是通过组合两个或多个不同的访问模式来提高覆盖率。例如,Sparse Transformer (Child et al., 2019)通过将一半的头部分配给每个模式,将跨步注意力和局部注意力结合起来。类似地,轴向Transformer (Ho et al., 2019)运用了一系列以高维张量作为输入的自注意计算,每个计算都沿着输入张量的单个轴。从本质上说,模式的组合以与固定模式相同的方式降低了内存复杂度。但是,不同之处在于,多个模式的聚合和组合提高了自注意机制的整体覆盖率。
可学习的模式(LP) -固定的,预先确定的模式的扩展是可学习的模式。不出所料,使用可学习模式的模型旨在以数据驱动的方式学习访问模式。学习模式的一个关键特征是确定令牌相关性的概念,然后将令牌分配到桶或集群(Vyas et al., 2020; Wang et al., 2020b)。值得注意的是,Reformer (Kitaev et al., 2020)引入了一种基于哈希的相似性度量,以有效地将令牌聚为块。类似地,路由Transformer (Roy et al., 2020)对令牌使用在线k-means聚类。同时,Sinkhorn排序网络(Tay et al., 2020b)通过学习对输入序列的块进行排序,暴露了注意权值的稀疏性。在所有这些模型中,相似函数与网络的其他部分一起端到端训练。可学习模式的关键思想仍然是利用固定模式(块状模式)。然而,这类方法学会了对输入标记进行排序/聚类——在保持固定模式方法的效率优势的同时,实现了序列的更优全局视图。
神经记忆——另一个突出的方法是利用可学习的侧记忆模块,它可以一次访问多个令牌。一种常见的形式是全局神经存储器,它能够访问整个序列。全局标记充当一种模型内存的形式,它学习从输入序列标记中收集数据。这是在Set transformer (Lee et al., 2019)中首次引入的诱导点方法。这些参数通常被解释为“内存”,用作将来处理的临时上下文的一种形式。这可以被认为是参数关注的一种形式(Sukhbaatar et al., 2019b)。ETC (Ainslie et al., 2020)和Longformer (Beltagy et al., 2020)也使用了全局记忆令牌。在有限的神经记忆(或诱导点)中,我们能够对输入序列执行一个初步的类似于池的操作来压缩输入序列——在设计高效的自注意模块时,这是一个可以随意使用的巧妙技巧。
低秩方法——另一种新兴的技术是通过利用自注意矩阵的低秩近似来提高效率。
内核——另一个最近流行的提高transformer效率的方法是通过内核化来查看注意力机制。
递归-块方法的一个自然扩展是通过递归连接这些块。
下采样-另一种降低计算成本的常用方法是降低序列的分辨率,从而以相应的系数降低计算成本。
稀疏模型和条件计算——虽然不是专门针对注意力模块,稀疏模型稀疏地激活一个参数子集,这通常提高了参数与FLOPs的比率。
专知便捷查看
便捷下载,请关注专知公众号(点击上方蓝色专知关注)
后台回复“ET39” 就可以获取《Google最新《高效Transformers》2022综述大全,39页pdf阐述九大类提升Transformers效率方式》专知下载链接

请扫码加入专知人工智能群(长按二维码),或者加专知小助手微信(zhuanzhi02),加入专知主题群(请备注主题类型:AI、NLP、CV、 KG、论文等)交流~







