学界 | 谷歌全端到端语音合成系统Tacotron:直接从字符合成语音
选自arXiv
作者:王雨轩等
机器之心编译
参与:李泽南、吴攀
最近,谷歌科学家王雨轩等人提出了一种新的端到端语音合成系统 Tacotron,该模型可接收字符的输入,输出相应的原始频谱图,然后将其提供给 Griffin-Lim 重建算法直接生成语音。该论文作者认为这一新思路相比去年 DeepMind 的 WaveNet 以及百度刚刚提出的 DeepVoice 具有架构上的优势。点击阅读原文下载论文。
现代文本转语音(TTS)的流程十分复杂(Taylor, 2009)。比如,统计参数 TTS(statistical parametric TTS)通常具有提取各种语言特征的文本前端、持续时间模型(duration model)、声学特征预测模型和基于复杂信号处理的声码器(Zen et al., 2009; Agiomyrgiannakis, 2015)。这些部分的设计需要不同领域的知识,需要大量精力来设计。它们还需要分别训练,这意味着来自每个组件的错误可能会复合到一起。现代 TTS 设计的复杂性让我们在构建新系统时需要大量的工作。
此前,WaveNet(van den Oord et al., 2016)是一种用于生成音频的强大模型。它对 TTS 来说效果良好,但由于样本级自回归采样的本质(sample-level autoregressive nature),速度较慢。它还需要对来自现有 TTS 前端的语言特征进行调节,因此不是端到端的:它只取代了声码器和声学模型。另一个最近开发的神经模型是百度提出的 DeepVoice(Arik et al., 2017),它通过相应的神经网络代替经典 TTS 流程中的每一个组件。但其中的每个组件都是独立训练出来的,改变系统以端到端形式训练非常重要。
论文:Tacotron:一个完全端到端的文本转语音合成模型(Tacotron: A Fully End-to-End Text-To-Speech Synthesis Model)

摘要:
一个文本转语音的合成系统通常需要多个处理阶段,例如文本分析前端、声学模型和音频合成模块。构建这些组件经常需要多种领域的专业知识,而且设计选择也可能很脆弱。在本论文里,我们提出了 Tacotron——一种端到端的生成式文本转语音模型,可以直接从字符合成语音。通过<text, audio>配对数据集的训练,该模型可以完全从随机初始化从头开始训练。我们提出了几个可以使该序列到序列框架在这个高难度任务上表现良好的关键技术。Tacotron 在美式英语测试里的平均主观意见评分达到了 3.82 分(总分是 5 分),在自然感(naturalness)方面优于已在生产中应用的参数系统(parametric system)。此外,由于 Tacotron 是在帧(frame)层面上生成语音,所以它比样本级自回归(sample-level autoregressive)方式快得多。
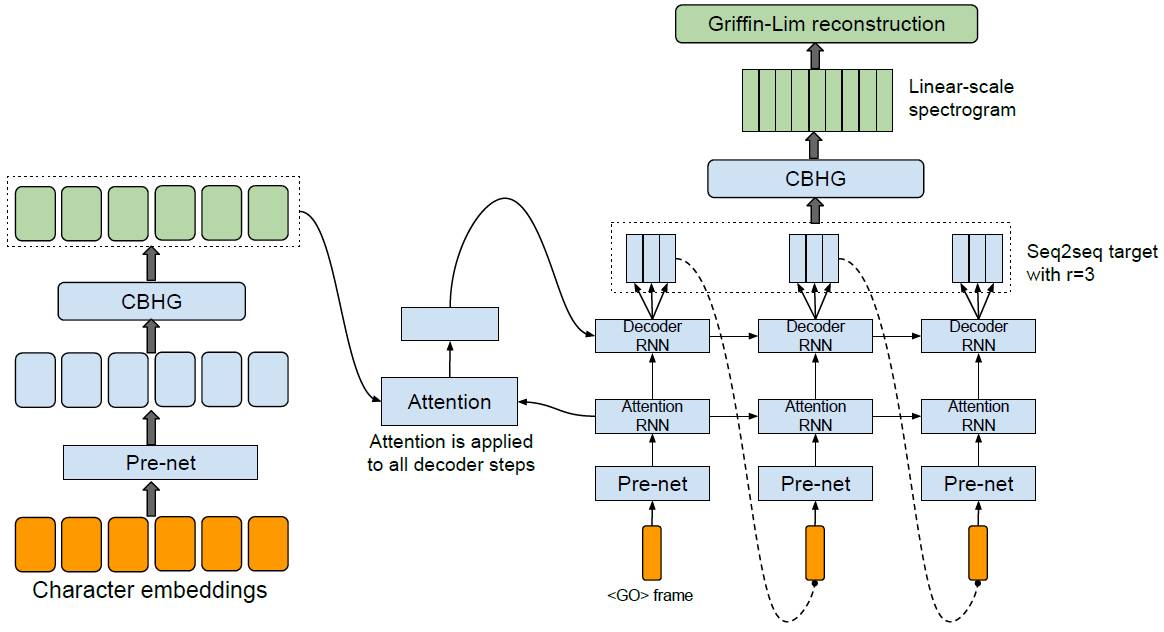
图 1:模型架构。该模型接收字符的输入,输出相应的原始频谱图,然后将其提供给 Griffin-Lim 重建算法以生成语音
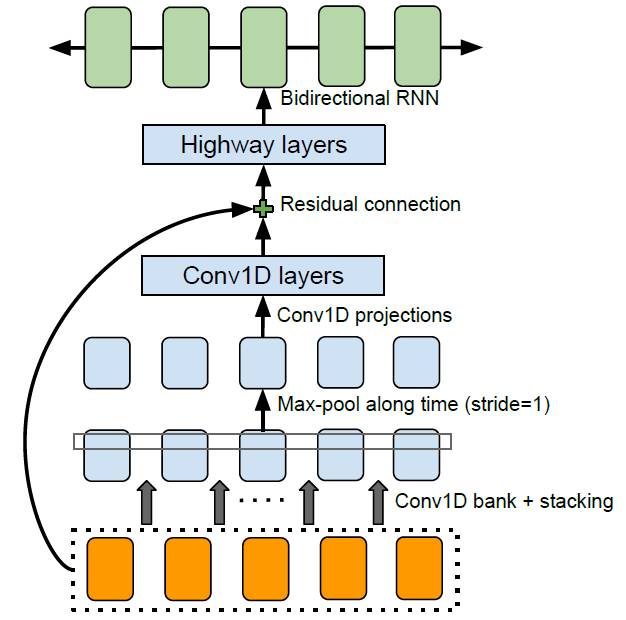
图 2:CBHG(一维卷积库+highway 网络+双向 GRU)模块,改编自 Lee et al. (2016)
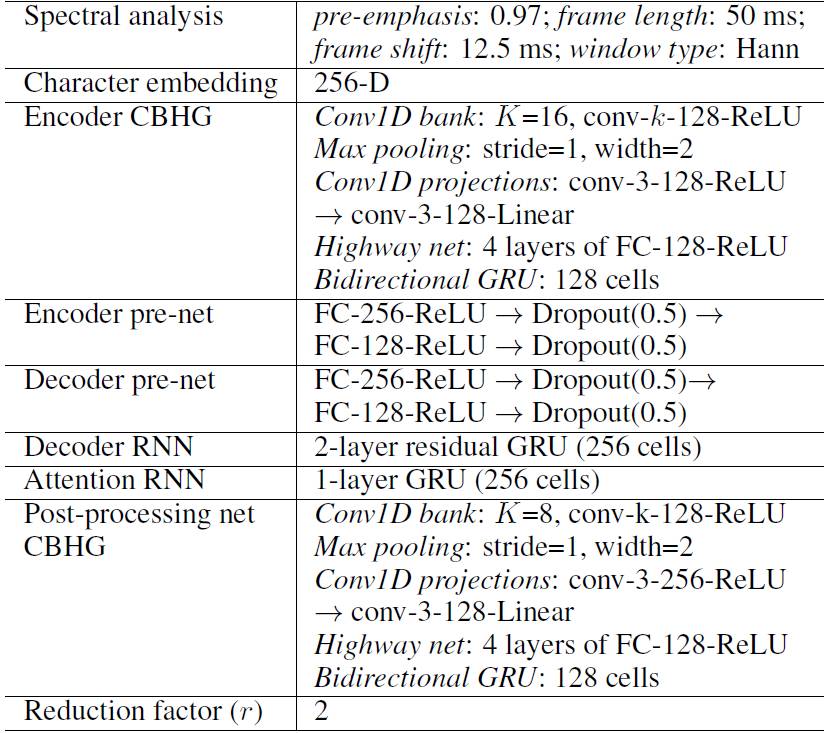
表 1:超参数和网络架构。「conv-k-c-ReLU」表示宽度为 k、有 c 个输出通道、带有 ReLU 激活的一维卷积。FC 代表全连接。
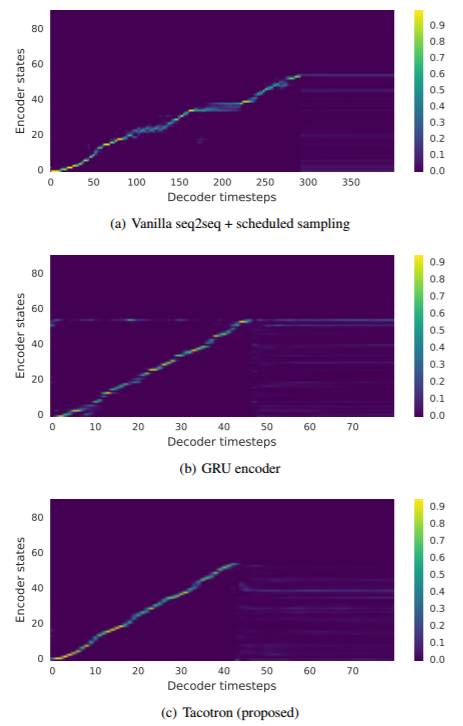
图 3:在测试短语上的注意对齐(attention alignment)。由于使用了 r=5 的输出规约(output reduction),Tacotron 的解码器的长度更短。
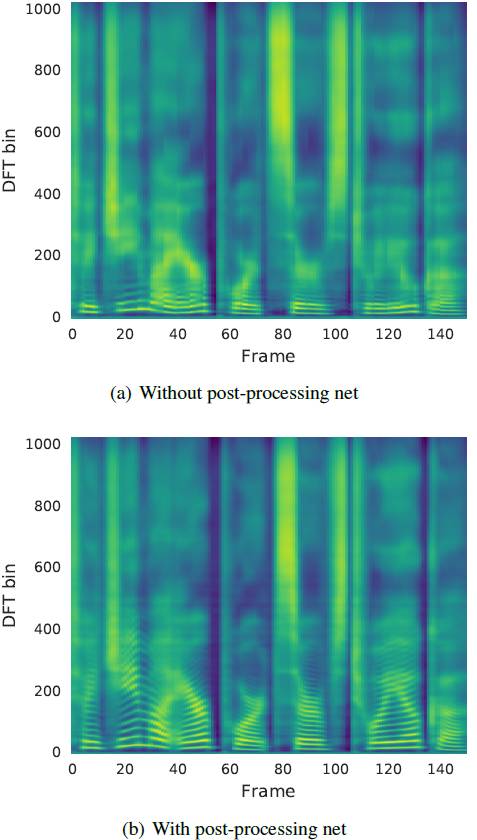
图 4:使用和不使用后处理网络的预测谱图对比
研究人员进行了平均意见得分测试(mean opinion score,MOS)——由测试者对合成语音的自然程度进行 5 分制的李克特量表法(Likert scale score)评分。MOS 的测试者均为母语人群,共使用 100 个事先未展示的短语,每个短语获得 8 次评分。当计算评分时,只有在测试者佩戴耳机时打出的评分被计算在内。作为对比,研究人员将 Tacotron 与参数式(parametric)系统(基于 LSTM(Zen et al., 2016))和拼接式(concatenative)系统(Gonzalvo et al., 2016)做了比较,后两者目前均已投入商业应用。测试结果如下表显示:Tacotron 的 MOS 分数为 3.82,优于参数系统。由于参照基准已经非常强大,以及 Griffin-Lim 合成的引入,这一新方法具有非常好的前景。

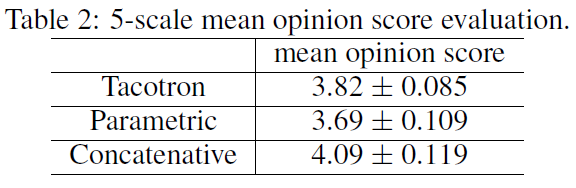
表2:意见得分测试结果
项目 GitHub:https://github.com/google/tacotron
语音合成音频试听:「Tacotron: A Fully End-to-End Text-To-Speech Synthesis Model」
https://google.github.io/tacotron/
原文链接:https://arxiv.org/abs/1703.10135
本文为机器之心编译,转载请联系本公众号获得授权。
✄------------------------------------------------
加入机器之心(全职记者/实习生):hr@jiqizhixin.com
投稿或寻求报道:editor@jiqizhixin.com
广告&商务合作:bd@jiqizhixin.com



