高效、简单、易实现 | 多任务+注意力机制的学习(文末有福利)

“计算机视觉战队”在今天给大家带来干货的之前,先说一些最近我发现的一些事。(纯自己的见解)最近,CVPR2019让圈内有一次火热起来,出现了一大波新技术新思想新框架,对应的技术确实值得我们去学习!
但!今天要说的事,关于很多平台的问题,包括我们自己的平台。近期观察了较多的平添推送关于CVPR类的知识,如果有心的同学不知道发现啥问题没?
那就是很多平台会把一篇Paper的摘要、框架介绍及实验翻译一波就拿出来推送,是方便了很多同学阅读,但你真正学习的有多少?不觉得有些都是比较Low,也许那就是现在的趋势,但是我们平台保证绝不会为了一点点流量做一些没有高质量的分享,希望大家的监督,谢谢!

下周有一个雷锋日,“计算机视觉战队”平台秉着这种精神及我们的宗旨,在之后的日子,会更加努力为大家带来真正好的分享,欢迎更多的人加入“计算机视觉战队”,一起学习,一起监督,一起进步!
开始进入正题
抛砖引玉
深度学习也火了很多年了吧,在图像、语音等领域已经炉火纯青,然而很多出现的神经网络通常只为完成一项特定任务而设计,放到现实应用中,设计一个完整的视觉系统是不是要比单独任务的系统好很多、高效很多。
如果一个能同时执行多个任务的网络比建立一组独立的网络(每个任务都有一个)是不是要好得多,这不仅在内存和推理速度方面更有效,而且在数据方面也更有效,因为相关的任务可能共享带有信息的视觉特征。例如,有监督学习的深度估计任务可以通过学习对深度响应的特征来帮助语义分割任务,从而为分割提供依据。
但是!有两个关键技术需要关注。
1)网络结构(如何共享):
多任务学习体系结构应该同时表达任务共享特性和特定任务特征。因此,网络被鼓励学习一种新的表示(以避免过度拟合),同时也提供了学习为每个任务量身定做的特征能力(以避免不合适)。
2)损失函数(如何平衡任务):
一个多任务损失函数,它对每个任务的相对贡献进行加权,应该使所有任务的学习具有同等的重要性,而不允许学习被较容易的任务所支配。人工调整损失权重是一种不错的方法,但是谁有那么多时间,所以这只是次优方法。因此自动学习这些权重,或设计一个对这些权重具有鲁棒性的网络,是非常可取的。
以上这些考虑到的话,那接下来开始说说一些针对性的解决办法,总体而言,之后说讲的框架还是值得学习下,挺有意思但简单的系统。
框 架 设 计
说框架前先来一张例图,想让大家在脑中有一个框架,带着这样的框架继续接下来的学习。

看着这样的框架是不是比较简单,和我毕业论文中的一个章节有那么一丝丝相似,其实好的框架都是简单但是实用,因为我们还要最终将其应用到实际应用中。
看到上面的框架,让我想到“双流网络”,估计现在都有“三流网络”了吧,但是其确实提高了较高的性能,其中一种如下:

回到正题,看到最之前的框架,可以看出,其主要是由单个共享网络组成,该网络学习全局特征池其包括所有任务的特征。
然后能看到,该网络针对每个任务不是直接从共享特征池中学习,而是在共享网络中的每个块上应用注意机制的掩码,通过这种方式,每个注意力机制的掩码会自动确定每个任务的共享特征的重要性,从而允许以一种自我监督、端到端的方式学习任务共享和特定任务的特征。
这种灵活性使得可以为跨任务学习更有表现力的特征组合,同时允许为每个单独的任务量身定做相应的特征。此外,自动选择哪些特性要共享,哪些特定任务允许高效的体系结构,与具有明确的任务分离的多任务体系结构相比,具有更少的参数。
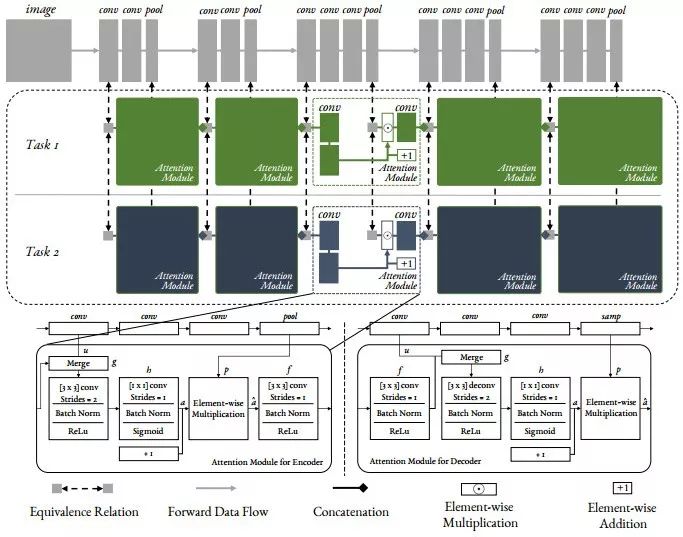
上面这个框架看起来是不是复杂很多了,哈哈!那我带着大家来详细的学习下,看看有没有别的思想,搞一个属于自己的创新点,发一篇顶会文章。
上图如果用心看的,应该能看出是基于VGG-16网络,而且更用心的可以看出这是Segnet编码的一部分,解码的一部分被对称到VGG-16。如上图所示,每个注意模块学习注意力机制掩码,其本身依赖于相应层的共享网络中的特征。因此,共享网络中的特征和注意力机制掩码可以被共同学习到跨多个任务的共享特征,同时也可以学习由注意力机制掩码而产生的特定于任务的性能。
下面主要讲特定任务的注意力模块。
注意力模块
注意力模块的设计是为了允许特定任务的网络学习特征,方法是对共享网络中的特征应用注意机制掩码,每个特征通道每个任务有一个注意机制掩码,将共享网络的第j块中的共享特征作为p(j),并将此层中学习的注意机制掩码作为a(j)i用于任务i。然后,该层中特定任务的特征ˆa(j)i通过注意机制掩码按元素的乘法计算,共享特征如下:
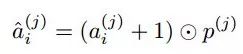
编码器中的第一注意力模块仅作为共享网络中的特征输入,但对于j层中的后续注意模块,输入是由共享特征u(j)和来自上一层ˆa(j−1)i中的特定任务特征组成的,如下:
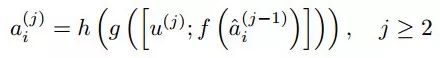
在这里需要解释下:f, g, h都是批标准化的卷积层或反卷积层,遵循f, g或h中的非线性激活,f和g都由[3×3]核组成,h使用[1×1]核来匹配特征和共享特征之间的通道。此外,在函数g中,应用了一个大小为2的函数来匹配池化/上采样操作中的压缩/上采样分辨率。有关编码器和解码器之间体系结构的等效性,还是看上图的框架。
注意机制掩码a(j)i∈[0,1]是以自我监督的方式通过反向传播来学习的。如果a(J)i→0,则所参加的特征映射等效于全局特征映射,并且任务共享所有特征。因此,期望性能不会比共享多任务网络的性能差,后者只在网络结束时进入单个任务,下面的实验也会展示。
实 验
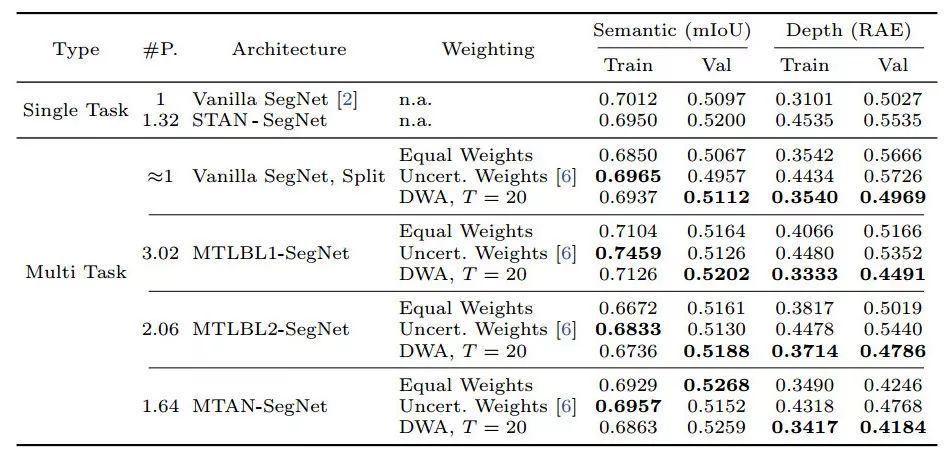
7类语义分割和深度估计结果对数据集进行训练和验证。将语义分割度量为平均IoU(越高越好)和深度估计作为相对绝对误差(越低越好)。#P比较网络参数的数量,并在表中以粗体突出显示多任务体系结构和加权的最佳组合。
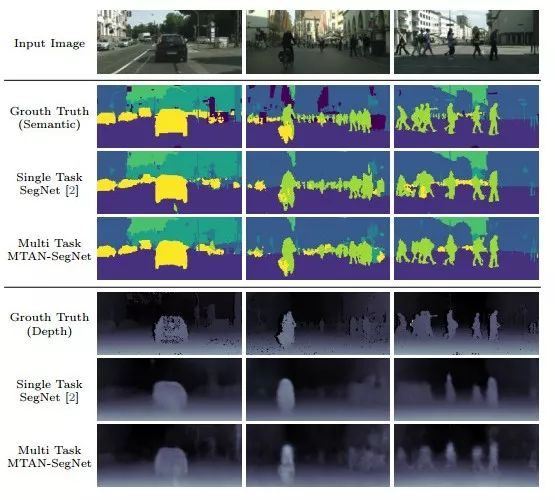
实验效果图


Edison_G的小总结
今天主要分享的是顶会中的一个新多任务学习方法,即多任务注意网络。这包括一个全局特征池,以及每个任务的特定注意力模块,网络允许对任务共享和特定任务的特性进行自动学习。
最终还在语义分割和深度估计等任务数据集上进行实验,也证明了比其他方法优异,同时对损失函数中使用的特定加权方案也具有一定的鲁棒性。(这一点呢,没有提及,有兴趣可以自己看下)
但是该方法具有通过注意机制掩码来分担权重的能力,因此该方法具有参数效率高、结构简单、易于实现和训练等优点。我还发现,随着任务复杂度的增加,多任务学习的性能比单任务学习的性能提高得更快。

如果想加入我们“计算机视觉战队”,请扫二维码加入学习群。计算机视觉战队主要涉及机器学习、深度学习等领域,由来自于各校的硕博研究生组成的团队,主要致力于人脸检测、人脸识别,多目标检测、目标跟踪、图像分割等研究方向。

加关注
公众号:




