Dropout的那些事
点击上方“CVer”,选择加"星标"或“置顶”
重磅干货,第一时间送达

作者:no one
https://zhuanlan.zhihu.com/p/76636329
本文已由作者授权,未经允许,不得二次转载
前言
今天在整理卷积神经网络的一些常用结构如,Batch Normalization,Dropout时突然想到,好像Dropout在最近几年的卷积神经网络中并不常见,于是就产生了一个问题:什么时候用Dropout,什么时候不该用。
经过大半天的搜索、分析、归纳,现在我就来谈谈目前大家讨论的一些点和网上一些不正确的观点,最后再做个总结。
Dropout技术最早于2012年Hinton文章《ImageNet Classification with Deep Convolutional Neural Networks》中提出,在这篇文章中,Dropout技术确实提升了模型的性能,一般是添加到卷积神经网络模型的全连接层中,使用深度学习工具箱实现起来很容易。
Dropout通过使其他隐藏单元存在不可靠性来防止过拟合(Hinton称防止训练数据进行复杂的协同调整),首先我们需要清楚的一点是,Dropout其实在现代神经网络中,不管是CNN还是RNN中都是有用的,其中CNN层也会应用到Dropout。Dropout在也衍生出了很多变种,例如:Drop path, Variab Dropout等。所以很多网友看到现在许多新型的网络没有使用Dropout,特别是卷积神经网络中,就认为Dropout已经被弃用了,这完全就是偏见!当然,还有一些网友在卷积神经网络上的卷积层上加入Dropout和Batch Normalization的实验[1],发现加入Dropout的效果比不加的效果还要差,然后就认为Dropout在卷积层上甚至会损害网络性能,看了一下这位网友的实验,发现其实验有很多不合理的地方,最大的问题就是网络深度不够,仅仅只有5个卷积层,且在训练初期网络未稳定时就将Dropout加入,导致网络性能非常差。(还有一些博客直接翻译他,比如[2][3])。
下面我们就来扒一扒Dropout的一些事。
Dropout的提出
2012年在Alex出现之前,Hinton就同Alex等人提出了dropout[4],其在RBM网络,浅层卷积神经网络中均试验性的加入了Dropout,值得注意的是他们是在全连接层加入的. 这篇文章的网络基本架构,使用的一些技巧在Alex中都有继承。
2014年作者们又根据之前的经验和增加许多实验重新将Dropout进行可梳理,并发表在了JMLR上[5]。我们接下来根据这篇文章来先来看看Dropout。
Dropout提供了一种有效地近似组合指数级的不同经典网络架构的方法,下面的两张图截自原文。
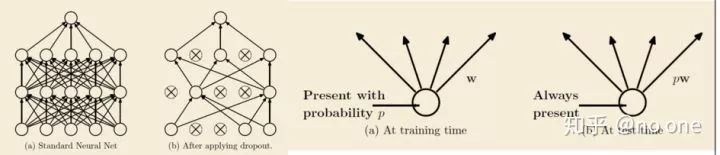
将Dropout应用到神经网络中,相当于从该网络中采样一些子网络。这些子网络由所有在Dropout操作后存活下来的单元节点组成。如果一个神经网络有n个节点,则能够产生
对Dropout思想来源,原文做了一个有趣的解释:
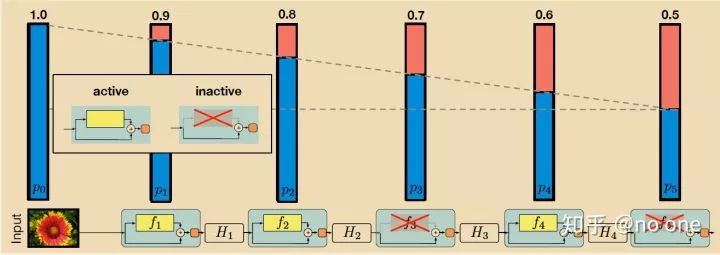
(有性生殖)从长远来看,自然选择的标准可能不是个体,而是基因的混合能力。一组基因能够与另一组随机基因良好协作的能力使它们更加健壮。由于基因不能依赖大量的伴侣在任何时候出现,它必须学会自己做一些有用的事情或与少数其他基因合作。根据这一理论,有性生殖的作用不仅仅是让有用的新基因在整个种群中传播,而且还通过减少复杂的共同适应来促进这一过程,从而减少新基因改善基因的机会。类似地,Dropout训练的神经网络中的每个隐藏单元必须学会使用随机选择的其他单元样本。这应该使每个隐藏单元更加健壮, 并推动它自己创建有用的功能,而不依赖于其他隐藏单元来纠正其错误。但是,图层中的隐藏单元仍然会学会彼此做不同的事情.

Dropout的理解
本节来自[6],我们先来看看在Dropout在全连接层上的行为
Dropout on fully-connected layers
一个n层的全连接网络(假设忽略bias),可以描述为如下:
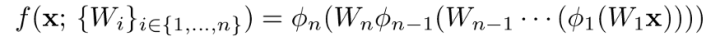
其中,ϕᵢ 为非线性激活函数,(e.g., ReLU),Wᵢ fori ∈{1, …,n} 为权重矩阵 andx 为输出. 考虑一个单隐藏层的全连接网络f(x): ℝ⁹ → ℝ⁹,其没有非线性激活函数和bias,则我们可以将网络描述为:

则下图可以代表我们的单隐藏层网络
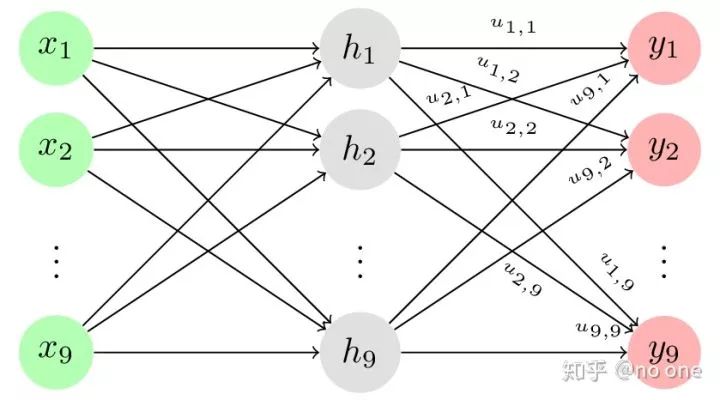
现在,我们加入dropout到该网络中,让 r ∈ {0,1}⁹为独立等概率伯努利分布 (iid)随机变量组成的向量 . 则加入dropout后的可以表示为:

其中, Vtx has been collapsed to 
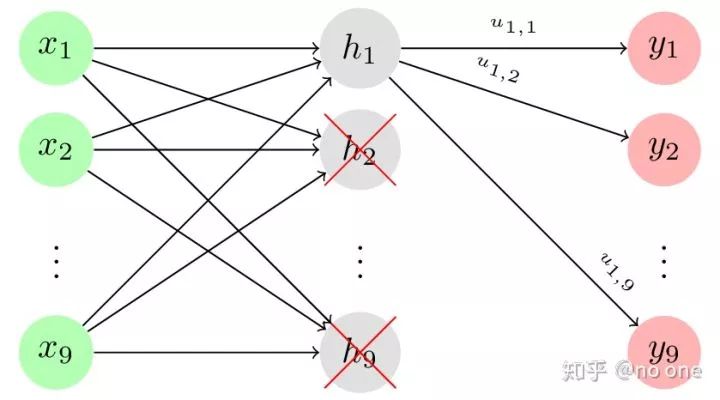
我们可以看出dropout在全连接神经网络中的作用相当于将权重矩阵中的某些列置为0,使得网络中的某些神经元被丢弃。
Dropout in convolutional neural networks
一个n层的卷积神经网络(忽略bias)可以表示为如下:
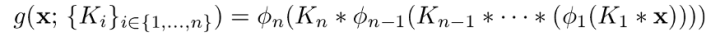
其中 ∗ 为卷积操作, ϕᵢ 为非线性激活函数, Kᵢ for i ∈{1, … , n} 为卷积核 , x 为输入.
为了简单起见,我们假设x ∈ ℝ³ ˣ ³ , K ∈ ℝ² ˣ ². 则K ∗ x 可以写为:
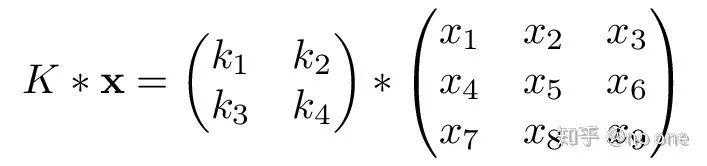
我们可以将卷积输入改写为列(img2col),并对卷积核做相应的改动

同全连接网络一样,假设g(x): ℝ³ ˣ ³ → ℝ³ ˣ ³ 为没有非线性激活层和bias的双卷积层, g 可以表示为:
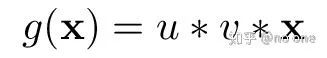
其中,u, v ∈ ℝ³ ˣ ³ 为卷积核, x ∈ ℝ³ ˣ ³ 为图像. 为了简单起见,且不影响分析,设 h = v ∗ x. 为了使g的尺寸同x的尺寸一致,我们需要对输入图进行zero-padding,使得h的尺寸同x保持一致,当然我也可以将权重矩阵改写如下(证明很简单):

现在我们加入dropout,让U 为上述的大矩阵 (i.e., the expanded convolutional kernel with zero-padding) 且r ∈ {0,1}⁹ iid伯努利随机变量向量:
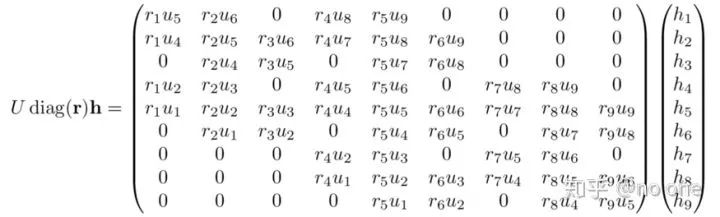
我们观察上述大矩阵的左上角:

可以发现,权重值u₄, u₅, u₆ 在分别都在不同列中出现,即每个列之间存在相关性, 因此如果 r₁ = 0, r₂=1 或者r₁ = 1, r₂=0, 我们依然可以更新权重值 u₅ 和 u₄ (r₃为值对其没有影响).
从上面看出,在卷积层中引入dropout似乎对网络没什么作用,如果硬要说作用的话,那无非就是在feature map中引入了Bernoulli noise,然而并没有理论证明引入这种噪声能够带来实质性的作用。在全连接层中引入Dropout是有理论支撑的(相当于引入了正则化)。
当然,其实很多人根据dropout做了很多工作,包括许多dropout的变体(DropPath, SpatialDropout, Variational dropout[7]),也有很多工作直接在卷积层中加入dropout,并取得了性能提升,因此dropout在卷积层中确实还是有用的[8][9]。
Dropout的各种变体版本
1. Dropout[10]: 随机drop一个 NCHW 的特征;
2. DropConnect [11]:只在连接处扔,神经元不扔:即在网络层与层之间的Weight中随机失活
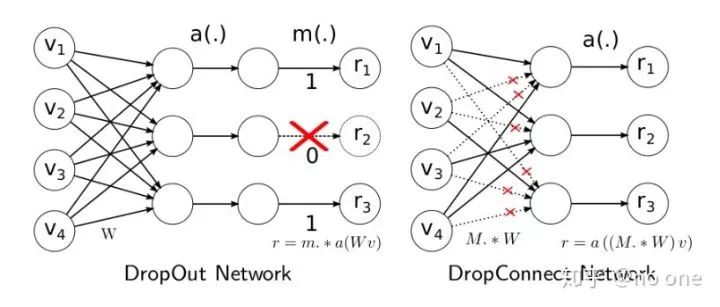
Training部分和Dropout的training部分很相似,不过在使用DropConnect时,需要对每个example, 每个epoch都随机sample一个M矩阵(元素值都是0或1, 俗称mask矩阵)。Training和Inference的算法流程如下:

注意:因为DropConnect只能用于全连接的网络层(和dropout一样),如果网络中用到了卷积,则用patch卷积时的隐层节点是不使用DropConnect的,因此上面的流程里有一个Extract feature步骤,该步骤就是网络前面那些非全连接层的传播过程,比如卷积+pooling. DropConnect的Inference部分和Dropout不同,在Dropout网络中进行Inference时,是将所有的权重W都scale一个系数p(作者证明这种近似在某些场合是有问题的,具体见其paper)。而在对DropConnect进行推理时,采用的是对每个输入(每个隐含层节点连接有多个输入)的权重进行高斯分布的采样。该高斯分布的均值与方差与前面的概率值p有关,即满足的高斯分布:
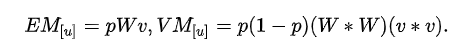
由上面的过程可知,在进行Inference时,需要对每个权重都进行Sample,所以DropConnect速度会慢些。根据作者的观点,Dropout和DropConnect都类似模型平均,Dropout是2|m|个模型的平均,而DropConnect是2|M|个模型的平均(m是向量,M是矩阵,取模表示矩阵或向量中对应元素的个数),从这点上来说,DropConnect模型平均能力更强(因为|M|>|m|))。但是reddit上有人提过DropConnect这种方式其实并没有对Dropout有所改进。
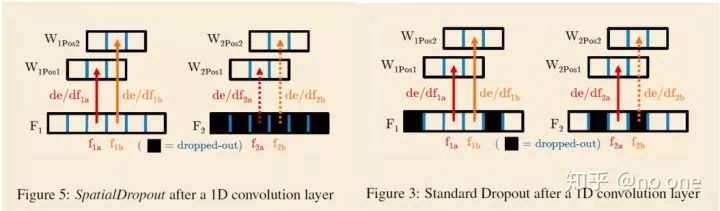
3. Spatial Dropout[12]: 随机drop一个 CHW 的特征;即:按channel随机扔
4. Stochastic Depth [13]:即按resnet block随机扔
5. Cutout [14]:在Input层按spatial块随机扔,也可以看成一种数据增强
6. DropBlock[15]: 随机Drop一个 C[HW]part 特征, [HW]part 是在HW上取一个region,跟group norm的group比较像;即每个Feature Map上按Spatial块随机扔,相当于弄了一个结构化的Dropout, 使得在Feature Map中的连续区域(相关性很强的区域)可以被同时丢弃。

其算法如下:

r 的计算依赖于keep_prob,其计算如下:
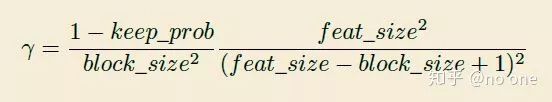
上面keep_prob可以解释为传统的dropout保留激活单元的概率, 则有效的 seed region 为 (feat_size - block_size + 1) 2 ,feat_size 为feature map的size. 实际上DropBlock中的dropblock可能存在重叠的区域, 因此上述的公式仅仅只是一个估计. 实验中keep_prob设置为(between 0:75 and 0:95), 并以此计算 r 的值。这里为了防止解释不清楚为什么 r 需要这么取值,我直接摘录原文如下:

总结
从上面的各种变体中,我们可以看出,Dropout从最开始的阶段全连接网络中的Co-Adaptation问题,到试图通过一定的手段解决由于卷积层中激活单元存在很强的空间相关性,Dropout应用到卷积网络中效果不佳的的问题。Spatial Dropout通过直接将某些channel的Feature Map抛弃(当然这样很暴力,相当于快刀斩乱麻!),Stochastic Depth则从Layer层面来操作,直接抛弃某些Layers(ResBlock),这更像是剪枝。目前来看,最合理的应该是DropBlock,因为其通过在一个Feature Map将某些关联的激活单元全部丢弃,使得模型可以有机会真正不依赖这些相关单元。因此,我单独开一个专题介绍DropBlock.
类型使用场景特点DropoutFC层随机失活激活单元ConnectDropoutFC层在权重矩阵中随机zero某些权值,且需要对每个example, 每个epoch都随机sample一个M矩Spatial Connect卷积层按channel随机失活某些Feature MapStochastic DepthResBlock随机失活某些ResBlock,但skip connect连接保留CutoutInput在Input层按spatial块随机扔,也可以看成一种数据增强DropBlock卷积层其通过在一个Feature Map将某些关联的激活单元全部丢弃,使得模型可以有机会真正不依赖这些相关单元
当然,什么时候该用,什么时候不该用,这个其实到目前为止还没有明确的说明,一般来说,当相对较大的模型用在较小的数据集时,通过Dropout的一些方法可以防止过拟合,并提高泛化性。
参考文献
详见原文:https://zhuanlan.zhihu.com/p/76636329
重磅!CVer学术交流群成立啦
扫码添加CVer助手,可申请加入CVer-目标检测、图像分割、目标跟踪、人脸检测&识别、OCR、姿态估计、超分辨率、SLAM、医疗影像、Re-ID、GAN、NAS、深度估计、自动驾驶、强化学习、车道线检测和模型剪枝&压缩等群。一定要备注:研究方向+地点+学校/公司+昵称(如目标检测+上海+上交+卡卡)

▲长按加群

▲长按关注我们
麻烦给我一个在看!


