CVPR 2020 | ACGPN: 基于图像的虚拟换装新思路

文 | 杨涵

论文地址:https://arxiv.org/abs/2003.05863
开源代码:https://github.com/switchablenorms/DeepFashion_Try_On
我们主要着眼于同一个人物模特的2d虚拟换装,示意图如下。multi-pose的就不在我们的讨论范围之内了。

ACGPN利用一种layout aware的方法,自适应的判断哪部分图像是应该保留的,解决了现有方法中,无法对人物肢体与衣服有遮挡的情况的建模,极大程度地降低了生成结果中的伪影以及模糊细节;并通过引入仿射变换的共线性等性质,对变形inshop-clothes中的TPS变换起到约束,使得Logo和花纹不易扭曲变形。
这个领域比较经典的工作有: VITON (CVPR18), CP-VTON (ECCV2018), VTNFP (ICCV2019) 以及在CVPR20截稿后挂出来的paper: SieveNet (WACV2020), GarmentGAN (2020 3月)
因为都是在VITON的数据集上做的,所以大家可以直接对比paper中图的质量。
回顾Image Based Virtual Try-on

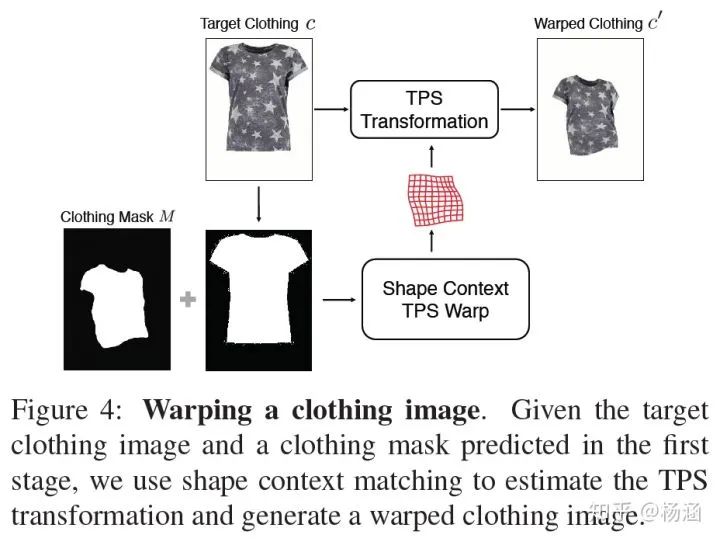
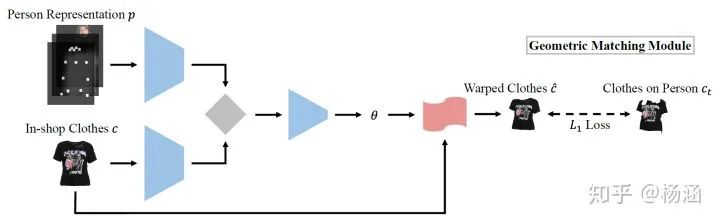
现有方法存在的问题



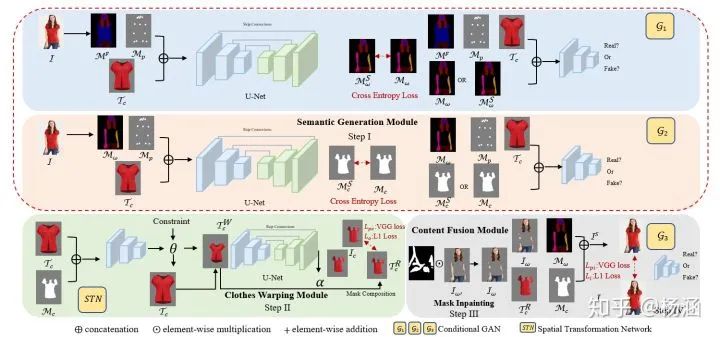
我们的解决方案
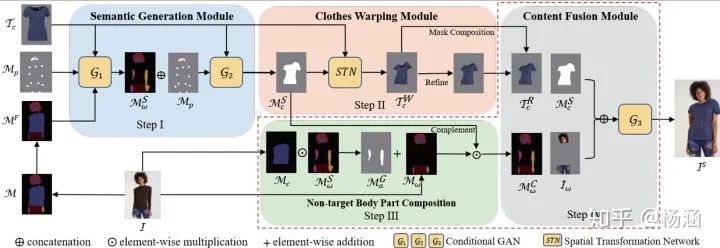
 ,人体姿势关键点
,人体姿势关键点
 , 以及融合后的人体语义模板
, 以及融合后的人体语义模板
 作为输入去预测
作为输入去预测
 和目标衣服模板
和目标衣服模板
 ;
;
 根据预测出来的语义划分,并且我们提出一种二阶差分约束去稳定变形过程;
根据预测出来的语义划分,并且我们提出一种二阶差分约束去稳定变形过程;
 ,然后使用融合网络去生成换装后的图片
,然后使用融合网络去生成换装后的图片
 ,并且联合
,
,并且联合
,
 ,
去补全图片
。
生成最后的换装图片。如图中的Non-target Body Part Composition 模块,组成公式如下:
,
去补全图片
。
生成最后的换装图片。如图中的Non-target Body Part Composition 模块,组成公式如下:



 表示逐元素乘积。
表示逐元素乘积。
 是
是
 除去衣服区域。通过这种组成,就能保证保存的
和对应区域的语义模板的一致性,并且通过训练过程的遮挡再生成的过程,学习补全的泛化能力,以解决现有方法对于复杂姿势以及肢体生成较差的问题。
除去衣服区域。通过这种组成,就能保证保存的
和对应区域的语义模板的一致性,并且通过训练过程的遮挡再生成的过程,学习补全的泛化能力,以解决现有方法对于复杂姿势以及肢体生成较差的问题。
二阶差分约束
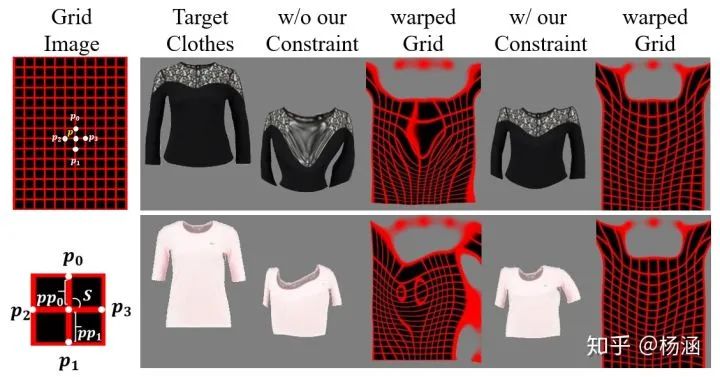

 和
和
 是权重超参数。
是权重超参数。
 表示一个特定的采样控制格点,
表示一个特定的采样控制格点,
 分别表示
周围的上下左右四个点。
分别表示
周围的上下左右四个点。


 表示,它是形变后的衣服与其ground-truth之间的1-范数距离
表示,它是形变后的衣服与其ground-truth之间的1-范数距离

 是形变后的衣服,
是形变后的衣服,
 是其ground-truth。
是其ground-truth。

 表示总的形变Loss。
表示总的形变Loss。
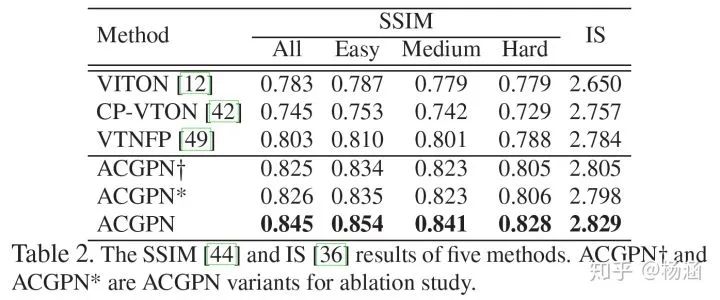
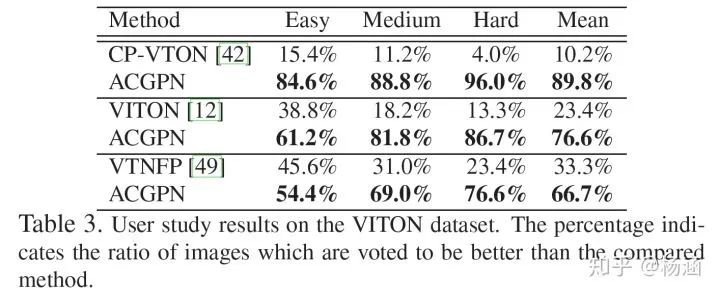
实验
Easy: 手放两侧,身体向前;
Medium: 身体会发生扭曲,肢体与身体轻微遮挡;
Hard: 肢体与身体有严重遮挡。


登录查看更多
相关内容

这是第25届年度会议,讨论有约束计算的所有方面,包括理论、算法、环境、语言、模型、系统和应用,如决策、资源分配、调度、配置和规划。为了纪念25周年,吉恩·弗洛伊德创作了一本“虚拟卷”来庆祝这个系列会议。信息可以在这里找到。约束编程协会有本系列中以前的会议列表。CP 2019计划将包括展示关于约束技术的高质量科学论文。除了通常的技术轨道外,CP 2019年会议还将有主题轨道。每个赛道都有一个专门的小组委员会,以确保有能力的评审员将审查这些领域的人提交的论文。
官网链接:https://cp2019.a4cp.org/index.html
Arxiv
5+阅读 · 2018年4月25日




相关VIP内容
相关资讯
相关论文
Arxiv
5+阅读 · 2018年4月25日