华为美研所推出EnAET:首次用自监督学习方法加强半监督学习

新智元报道
【新智元导读】Futurewei近日提出了半监督学习的新思路,不同于以前的半监督工作,该方法第一次通过引入复杂的图像变换信息进一步加强了模型的学习能力同时有效避免了过拟合问题。相比于以前的半监督和全监督算法,本文在模型相对简单的基础上,不仅实现了所有半监督任务的SOTA结果,并且在不适用validation数据集的情况下实现了CIFAR-10,STL-10数据集上全监督的SOTA结果。来 新智元AI朋友圈 和AI大咖们一起讨论吧。
Futurewei近日提出了半监督学习的新思路,不同于以前的半监督工作,该方法第一次通过引入复杂的图像变换信息进一步加强了模型的学习能力同时有效避免了过拟合问题。相比于以前的半监督和全监督算法,本文在模型相对简单的基础上,不仅实现了所有半监督任务的SOTA结果,并且在不适用validation数据集的情况下实现了CIFAR-10,STL-10数据集上全监督的SOTA结果。

EnAET全称是Self-Trained Ensemble AutoEncoding Transformations for Semi-Supervised Learning,本文首次引入图像变换信息利用自监督的方法来推动半监督学习。
通常来说,半监督学习希望达到两个目标,一是能够在有限标注样本情况下借助无标注样本完成模型学习,二是探索出一种方法能够解决over-fitting问题。EnAET通过自监督学习的思路,成功实现了这两个目标。同时,不同于传统思路专注于预测一致性和预测自信度的研究,本文首次提出了一种通用的自监督学习方法来加强半监督学习并取得了SOTA效果。
同时,EnAET首次探索了数据集极限情况下的模型学习,在每类仅有10张图片的情况下,在CIFAR-10取得了90.65%的准确率,在SVHN取得了83.08%的准确率。
EnAET最主要的贡献是以多种复杂图像变换作为切入点引入了一种新的自监督架构,通过这个架构我们不仅利用变换信息加强了模型的表征能力,而且进一步利用变换图片加强了预测一致性。不同于以前的基于变换的自监督方法,本文首次提出了融合多种变换的思想来进一步加强模型的表征能力,本文提出了两种基本变换方案spatial transformation(图1)和non-spatial transformation (图2)。
对于spatial变换而言,本文引入了四种经典的变换:projective, affine, similarity 和euclidean变换,详见表1. 对于non-spatial变换,引入了color,contrast,brightness和sharpen四种变换,并且将四种结合形成CCBS变换作为一种代表性的non-spatial变换加入EnAET框架。

图1 spatial transformation
从左到右依次是原图,projective变换,affine变换,similarity变换和euclidean变换。
图2 Non-Spatial Transformation
图片依次是:原图,color变换,contrast变换,brightness变换,sharpen变换,color+contrast变换,color+contrast+brightness变换,color+contrast+brightness+sharpen变换。

基于这两种变换的基础上,文章中提出了如图3所示的EnAET架构:
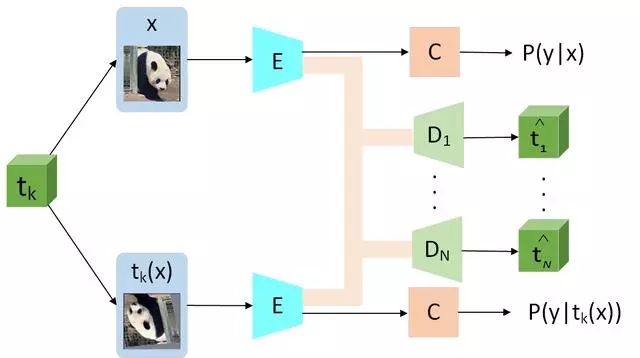
图3.EnAET算法示意图
简而言之,针对半监督中的分类网络,将其划分为两部分:编码器E和分类器C。同时针对不同变换tk提供不同的解码器Dk ,这里所有Dk的网络结构和C保持一致。对于不同变换后的图片和原图,E和C始终共享权重,这样做的原因是希望每种变换都能利用原图和变换后的图片经过E编码的特征预测,从而实现加强E表现性能同时避免过拟合的目标。
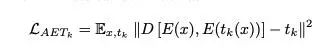
为实现这个目标,可以针对每种变换tk使用MSE损失函数来来计算AET损失从而达到增强编码器E的目的。
在AET损失函数的基础上,为了进一步增强模型的预测一致性,文章中进一步引入KL散度达到了模型的变换一致性。如下公式所示:
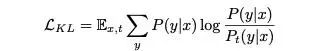
这里P(y|x)是模型对原图的预测,Pt(y|x)是模型对原图经过t变换后图像的预测。这里对原图的预测本文使用了average和sharpen等思路让原图预测更加可靠。
EnAET的具体训练思路如图4所示:

图4 EnAET算法
可以看出,因为EnAET是一种全新的基于图像变换的训练思路,所以针对任何以前的半监督算法,都可以将EnAET作为一种类似于正则化的方法引入训练,因此简而言之,针对任何半监督算法, EnAET可表述为:
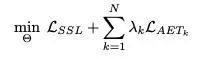
为同以往半监督方法对比,论文中使用了"Wide Resnet-28-2"的网络结构,以经典结构设计作为模型1,同时改换初始卷积核数量为135作为模型2. 最为重要的是,针对EnAET中的超参数,实验过程中针对所有数据集保持不变,极大地保证了方法的可迁移性。
3.1 半监督实验
在CIFAR10上,EnAET首次对仅有100张有标注图片的情况进行实验,取得了9.35%的错误率,同时在250张有标注图片分类任务下,相比于以前的SOTA,成功将错误率从11.08%下降到7.6%。具体对比如下:
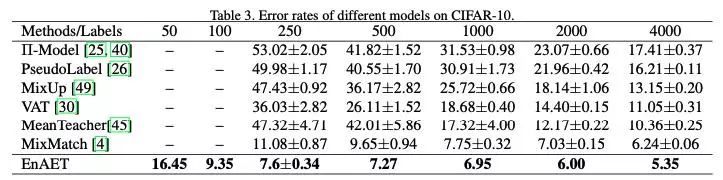
在CIFAR-100上,EnAET首次实验了每类仅有十张图片的情况,取得了58.73的错误率。在经典的10000张有标注图片分类任务下,成功将错误率从38.65%降到了26.93%。具体对比如下:
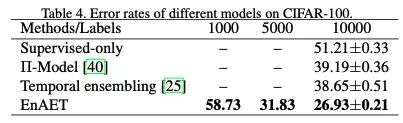
在STL10任务下,EnAET在1000标注样本下将错误率从10.18%下降到8.04%,在使用所有标注样本情况下将错误率从5.59%降到4.52%。
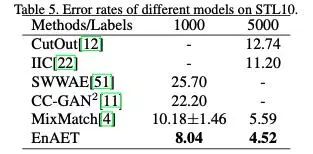
在SVHN任务下,EnAET在经典250有标注样本下将错误率从3.78%进一步降到3.21%,具体对比如下:
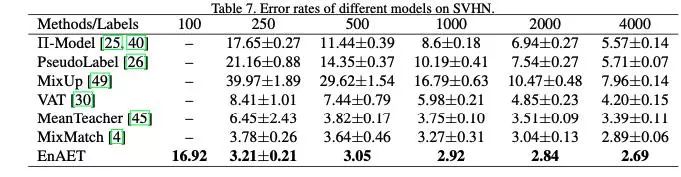
同时为对比以前基于复杂模型的方法,我们模型2与其他方法对比如下,所有任务均取得显著提升。
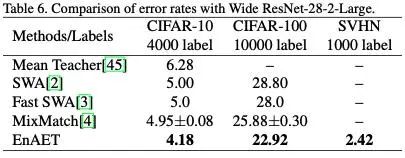
3.2 全监督实验
基于模型1,与所有基于该模型的全监督方法进行了对比,其中包括基于数据增强策略搜索的AutoAugment的方法,EnAET模型均取得显著提升,具体对比如图8所示。
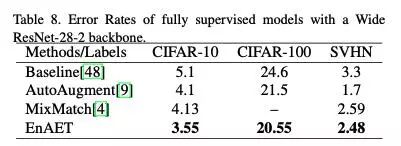
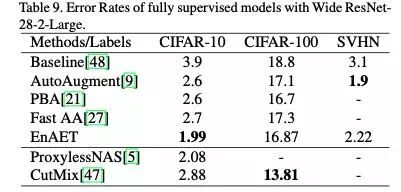
基于模型2,考虑到其他方法没有用过EnAET中的网络结构,因而采用Wide Resnet-28-10结构作为baseline。相比于我们的模型,该模型结构更加复杂并且拥有更多的参数,因此这种比较是公平的。同时对于不同数据集引入了全监督SOTA方法作为对比。
在这种对比下,相对于baseline,EnAET取得了巨大的提升,同时在Wide Resnet-28-10结构下相对其他方法取得显著提高。最值得一提的是,对于CIFAR-10,基于相对简单的架构,超越了基于PyramidNet和网络架构搜索(NAS)的方法,取得了该数据集的全监督SOTA。
本文通过引入EnAET,一种基于变换自监督的架构,成功地提升了半监督的性能。 通过实验,在半监督所有数据集上刷新了SOTA,同时在同等网络架构下达到了全监督的SOTA。考虑到超参数对所有数据集均是固定的,因此这种自监督的方法可以进一步迁移到无监督学习和全监督学习。
本文代码全开源:
https://github.com/wang3702/EnAET
论文链接:
https://arxiv.org/abs/1911.09265
-
与国内外一线大咖、行业翘楚面对面交流的机会 -
掌握深耕人工智能领域,成为行业专家 -
远高于同行业的底薪 -
五险一金+月度奖金+项目奖励+年底双薪 -
舒适的办公环境(北京融科资讯中心B座) -
一日三餐、水果零食
新智元邀你2020勇闯AI之巅,岗位信息详见海报:



