资源 | 最入门级别的机器学习图书:Chris Bishop发布在线新书
选自MBML book
参与:蒋思源
PRML 大神、微软剑桥研究院院长 Chris Bishop 与 John Winn 的机器学习新书 Model Based Machine Learning(基于模型的机器学习)不久之前刚刚公布。本书从实际案例出发,每一章节都着重从头解决一个问题,本书从最基础的概念开始,一步步带领读者体会机器学习建模解决问题的思路。本书现有 5 个章节,其他章节将陆续推出。
项目地址:http://mbmlbook.com/toc.html

近年来,机器学习已经走到了科技世界的中心位置。今天,成百上千的科学家和工程师们正在将机器学习的各类方法应用到越来越多的领域里。然而,在实践中有效利用机器学习是一项艰巨的任务,特别是对于新领域而言,以下是使用机器学习解决现实世界问题面临的一些主要挑战:
「我正被机器学习方法和技术的海洋所淹没,有太多的方法了!」
「我不知道该用哪个方法,不知道为什么这个方法在我的问题中表现更好。」
「我的问题看起来不能用任何标准算法解决。」

机器学习对于入门者而言是令人畏惧的
在本书中,作者从一个新的视角审视机器学习,即基于模型的机器学习。从这个视角来看,我们会更系统、清晰地了解创建高效机器学习解决方案的过程。本教程适应于全方位了解机器学习技术和应用,并有助于大家构建成功的机器学习解决方案。
什么是基于模型的机器学习?
在基于模型的视角中,我们不需要转换我们的问题而去拟合一些标准算法,我们只需要精确地设计我们自己的机器学习算法而拟合我们的问题。
在基于模型的机器学习中,核心观点即所有问题域的假设都可以在特定形式的模型中表达。实际上,模型就是对问题作出一系列假设,并用十分精确的数学形式表达出来。例如在第一章中,我们尝试构建一个模型而解决简单的谋杀问题。在这个任务中,模型的假设就包括一组犯罪嫌疑人、可能行凶的武器、不同犯罪嫌疑人对不同武器的偏好等,然后我们再对这些不同的假设采用具体的机器学习算法完成模型。基于模型的机器学习是一种广义目的方法,因此我们不需要学习巨量的机器学习算法和技术。
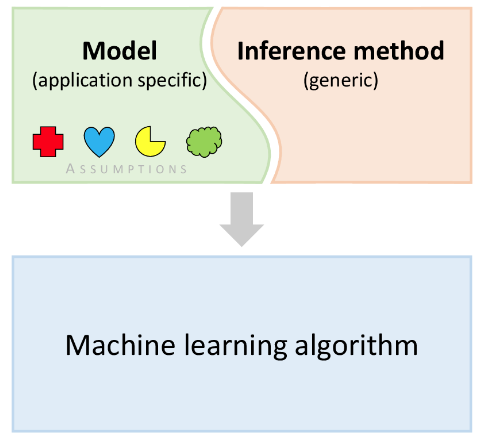
模型和算法
从基于模型的机器学习角度来看,模型是组合一系列假设以在问题域中寻找解决方案。为了从模型获得一组预测,我们需要收集数据并计算那些我们希望知道的变量值。而这一计算的过程就称之为推断。我们将在本教程中讨论几种常见的推断技术,而模型和推断过程的结合如下所示就可以定义成一个机器学习算法。
目标读者
本教程并不是寻常的机器学习教科书,因此我们也不会一一介绍不同的机器学习算法。我们会通过一系列现实案例介绍各种算法的关键概念。案例学习在本教程中起到了极其重要的作用,因为我们只有通过案例才能真正理解不同的建模方法和算法。因此每一章主要只讨论一个案例,并且将尝试使用基于模型的方法解决该案例所出现的问题。因此本教程非常适合机器学习入门者快速了解机器学习的核心思想和方法。
本教程每一个章节(或一个案例)将分为多个小节,因此初学者可以在阅读完每小节后消化该小节的内容再进入下一小节的内容。
当前章节内容
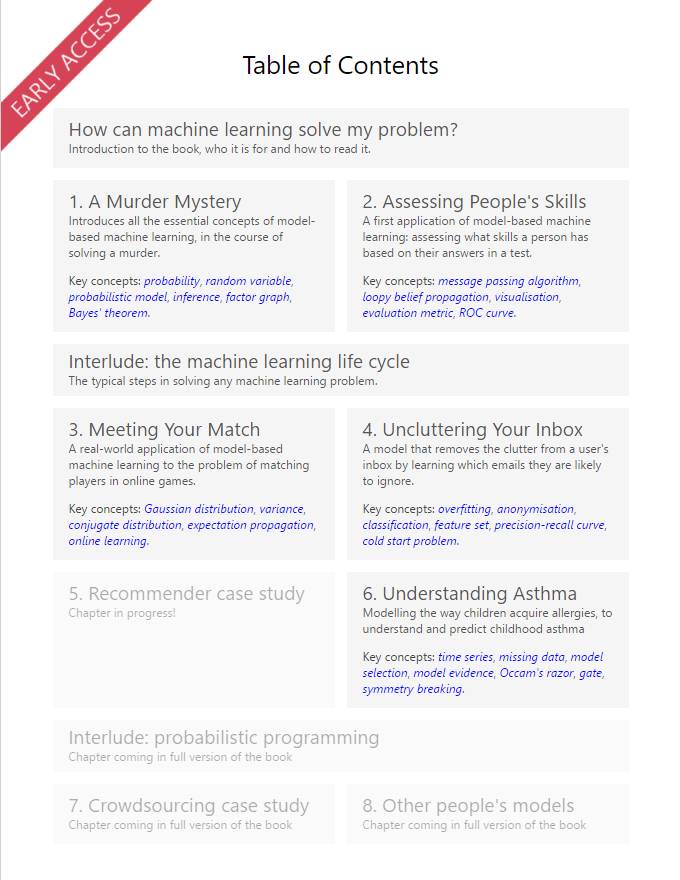
第一章:破密神秘谋杀任务
在破解谋杀秘密中,我们将使用各种常见的概率方法跟着作者一步步找出隐藏在幕后的凶手,本章节涉及到概率的意义、随机变量和概率分布等核心概念。
概率:即衡量随机事件不确定性程度的数值,其取值范围从 0 到 1。其中 0 代表不可能发生,1 代表必定发生。
随机变量:即数值存在不确定性的变量。
标准化约束:即对概率分布的限制,一个随机变量在所有情况下出现的概率和为 1.
概率分布:即一个函数,该函数给定了随机变量每一个可能的值和概率。
抽样:抽样是一种推论统计方法,它是指从目标总体中抽取一部分个体作为样本,通过观察样本的某一或某些属性,依据所获得的数据对总体的数量特征得出具有一定可靠性的估计判断,从而达到对总体的认识。
伯努利分布:伯努利分布又名两点分布或者 0-1 分布,是一个离散型概率分布。若伯努利试验成功,则伯努利随机变量取值为 1。若伯努利试验失败,则伯努利随机变量取值为 0。
均匀分布:均匀分布表示随机变量等可能出现。在实际问题中,当我们无法区分在区间 [a,b] 内取值的随机变量 X 取不同值的可能性有何不同时,我们就可以假定 X 服从 [a,b] 上的均匀分布。
第二章:评估人才技能
在这一章节中,我们将学会使用真实的数据构建模型。这一部分主要的概念如下:
概率密度函数:连续型随机变量的概率密度函数是一个描述这个随机变量的输出值,在某个确定的取值点附近的可能性的函数。
β 分布:Β分布也称贝塔分布,是指一组定义在 (0,1) 区间内的连续概率分布,有两个参数α和β。
对数概率(似然函数):似然函数是一种关于统计模型中的参数的函数,表示模型参数中的似然性,似然函数在统计推断中有重大作用。
真正类率(true positive rate):预测为正且实际为正的样本占所有正样本的比例。
假正类率(false positive rate):预测为正且实际为负的样本占所有正样本的比例。
后面第三章、第四章和第六章已经完成,而剩下的章节还没有更新。第三章主要是构建游戏玩家匹配系统,即使用 Xbox Live 数据构建一个可以匹配游戏玩家的系统,我们希望能使相匹配的玩家拥有相近的技能。第四章主要是构建邮件过滤系统,因为我们的邮件非常多,有些重要邮件会因为源源不断的新邮件而被覆盖掉,那么该章节就叫我们怎样利用机器学习方法减少这种信息负载。第六章则更深入到了医学场景中,因为儿童哮喘病近来比较严重,而我们更好地理解哮喘和过敏间的关系有助于帮助医生检测和诊断哮喘病,那么我们是不是可以利用机器学习解决该问题。

本文为机器之心原创,转载请联系本公众号获得授权。
✄------------------------------------------------
加入机器之心(全职记者/实习生):hr@jiqizhixin.com
投稿或寻求报道:editor@jiqizhixin.com
广告&商务合作:bd@jiqizhixin.com
点击阅读原文,查看机器之心官网↓↓↓


