【NeurIPS 2020】优化算法升迁深化学习效率
网易伏羲实验室的论文《学习行使犒赏塑形:犒赏塑形的新方式》(《Learning to Utilize Shaping Rewards: A New Approach of Reward Shaping》)入选,凸显了国际顶尖的科研实力。

网易伏羲在论文中重点钻研的“犒赏塑 形 ”( Reward Shaping )是一栽将先验知识转化为奖励函数,从而挑深邃化学习算法效率的有效技术手腕。 现在,网易伏羲的深化学习技术已成功在《潮人篮球》、《叛变寒》等游玩中落地,而行使先验知识来设计和组织有效的附添奖励函数往往是项现在能够取得挺进的关键之一。
不过,追求卓异的附添奖励函数必要比较专科的周围知识以及一再迭代的人力投入。同时,原由涉及到人的操作,现在的一些形式将规则性的知识转化为算法能够理解的数值奖励时,往往也会将人的认知误差引入其中,对深化学习算法带来负面的影响。举例来说,在设计《潮人篮球》游玩机器人的附添奖励函数时,倘若把握不益对传球行为的奖励值的大幼,比赛中将会展现球员之间一向进走相互传球而不袭击的为难场面。
为了避免上述题目,网易伏羲此次入选的论文始次挑出自适宜地行使给定的附添奖励函数的形式,让学习算法能判定分歧状态下对答附添奖励的益坏,并选择性地添以行使。
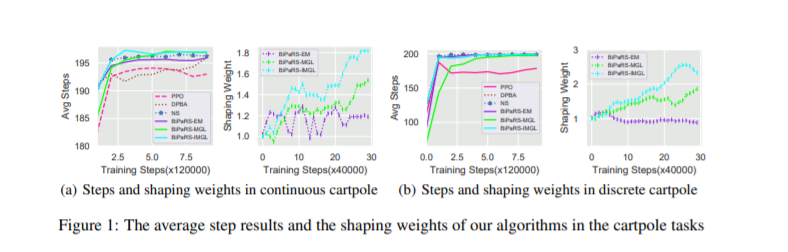
在幼车立杆和MuJoCo环境的一系列实验终局外明,网易伏羲所挑出的算法,不光能够分辨出附添奖励的益坏并选择性地行使,甚至还能够将有害的奖励值转化为对学习有协助的奖励值。
浅易来说,网易伏羲挑出的算法不光能让人造智能的深化学习效率变高,还能协助人造智能筛选出准确的知识,让人造智能 的 学习 更添 实在 。
https://arxiv.org/abs/2011.02669
专知便捷查看
便捷下载,请关注专知公众号(点击上方蓝色专知关注)
后台回复“RSL” 可以获取《【NeurIPS 2020】优化算法升迁深化学习效率》专知下载链接索引





