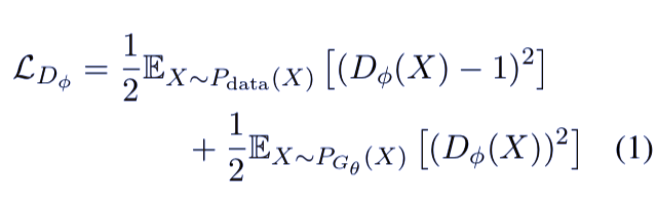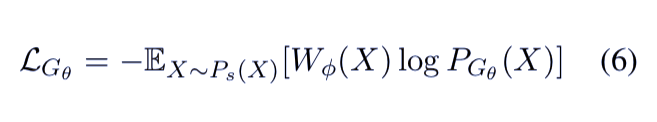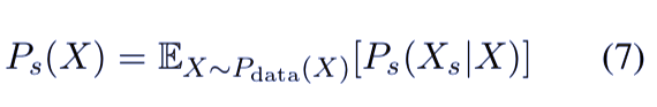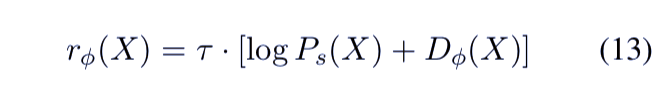选自arXiv
作者:Pei Ke、Fei Huang、黄民烈、朱小燕
机器之心编译
参与:魔王
如何解决 GAN 在文本生成任务中的训练不稳定问题?清华大学做出了尝试,研究者在判别器和生成器两个部分都进行了变革。
论文链接:https://arxiv.org/pdf/1908.07195v1.pdf
目前,大多数用于文本生成任务的生成对抗网络(GAN)会遇到强化学习训练算法(如策略梯度)的不稳定性问题,从而导致性能不稳定。为了解决该问题,来自北京信息科学与技术国家研究中心和清华大学的研究者提出一种新型框架——对抗奖励增强最大似然(Adversarial Reward Augmented Maximum Likelihood,ARAML)。
在对抗训练过程中,该框架的判别器将奖励分配给从数据附近平稳分布获得的样本,而不是从生成器的分布中获得的样本。生成器使用最大似然估计进行优化,该估计由判别器的奖励来增强,而不是策略梯度。实验证明,ARAML 模型性能优于当前最优的文本生成 GAN,且训练过程比后者更加稳定。
自然语言生成是 NLP 领域中的重要任务。由于神经模型的兴起,自然语言生成取得了巨大的进步。此类神经模型的标准训练范式是最大似然估计(MLE),即基于真实语境,最大化在文本中观察到每一个词的可能性。
MLE 被广泛使用,但它存在暴露偏置(exposure bias)问题:在测试阶段中,模型基于之前生成的单词顺序预测下一个词,而在训练阶段中,模型基于真值词汇进行预测。为解决这一问题,研究人员引入使用强化学习训练方法的 GAN 来解决文本生成任务,即训练判别器来分辨真实文本和模型生成的文本样本,为生成器提供奖励信号,生成器则通过策略梯度进行优化。
但是,近期研究发现,在离散数据上训练 GAN 存在的潜在问题比暴露偏置更加严重。其中一个基本问题是训练不稳定性。使用策略梯度更新生成器通常会导致训练过程不稳定,因为即使经过很好的预训练,生成器也很难从判别器中获取积极稳定的奖励信号。因此,生成器受到奖励信号高方差的负面影响,训练过程可能最终会崩溃。
在北京信息科学与技术国家研究中心和清华大学的研究者合著的这篇论文中,研究者提出了一种新型对抗训练框架——对抗奖励增强最大似然(ARAML),用来处理训练 GAN 解决文本生成任务时的不稳定问题。
在对抗训练的每一次迭代中,研究者首先训练判别器将更高的奖励分配给真实数据,而不是生成样本。然后,使用最大似然估计(MLE)在采样自平稳分布的样本上更新生成器,MLE 使用判别器奖励作为加权。(该想法受到奖励增强最大似然(RAML,Norouzi et al., 2016)的启发。)
平稳分布可以确保训练样本围绕着真实数据,从而使生成器的探索空间受到 MLE 训练目标的约束,进而使得训练过程更加稳定。与其他使用强化学习训练方法的文本 GAN 相比,ARAML 模型从平稳分布(而不是生成器分布)中获取样本,使用 RAML 训练范式(而不是策略梯度)优化生成器。
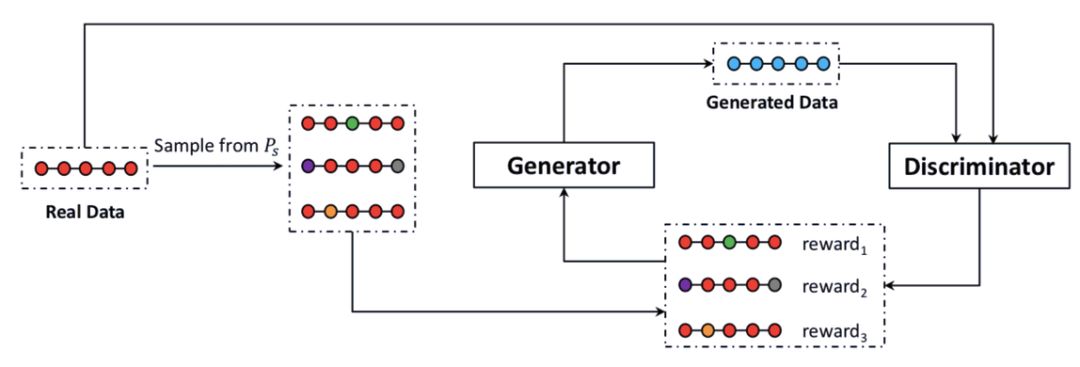
下图 1 展示了 ARAML 模型。该对抗训练框架包含两个阶段:1)训练判别器,使其向真实数据(而不是生成数据)分配更高的奖励;2)使用奖励增强的 MLE 训练目标,在来自平稳分布的样本上训练生成器。生成器的训练范式是:用 MLE 训练目标约束搜索空间,从而缓解训练不稳定的问题。
图 1:ARAML 模型概览。训练样本来自基于真实数据的平稳分布 P_s,生成器在判别器奖励增强的样本上训练。判别器的训练目标是判断真实数据和生成数据。
和其他 GAN 模型一样,ARAML 模型中判别器的目标是区分真实数据和生成数据。损失函数要求判别器将更高的奖励分配给真实数据而不是生成数据,从而使判别器在训练过程中学习提供更合适的奖励。
生成器的训练目标来源于使用强化学习训练方法的离散 GAN。如前所述,由于策略梯度,离散 GAN 存在不稳定问题,因而更难训练。该研究受 RAML 的启发,提出了一种指数回报分布(exponential payoff distribution)——将强化学习损失和 RAML 损失结合起来。最终的损失函数如下所示:
为了优化该损失函数,研究者首先构建固定分布以获得样本,然后构建恰当的奖励函数,从而以稳定高效的方式训练生成器。
研究者基于 P_data 构建了平稳分布 P_s:
P_s(X_s|X) 可以确保 P_s(X) 接近 P_data(X),从而使训练过程更加稳定。为了从真实数据样本 X 中获得新样本 X_s,研究者设计了三步:采样编辑距离 d、置换位置,以及填入对应位置的新单词。
研究者根据判别器的输出和平稳分布,设计了奖励函数:
直观来看,该奖励函数鼓励生成器生成具备大采样概率和高判别器奖励的句子。
目前,研究者通过公式 6 成功地优化了生成器的损失。这种新的训练范式使生成器避免策略梯度导致的方差,从判别器中获取更稳定的奖励信号,因为该生成器只能探索真实数据附近的训练样本。
研究者在三个数据集上评估了 ARAML 模型:COCO 图像描述数据集、EMNLP2017 WMT 数据集和 WeiboDial 单轮对话数据集。
研究者移除了包含低频词的 post-response 对,并随机选取子集作为训练集和测试集。三个数据集的具体数据情况见下表 2:
表 2:COCO、EMNLP2017 WMT 和 WeiboDial 数据集的统计概况。WeiboDial 数据集的平均长度 7.3/10.8 分别表示 post 和 response 的长度。
![]()
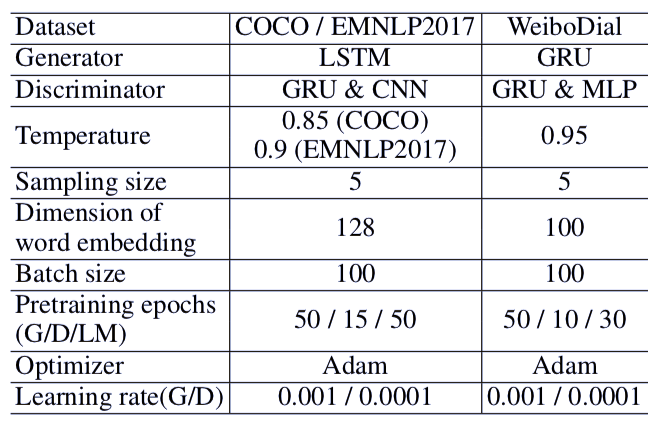
表 3:ARAML 模型的实现细节。G/D/LM 分别表示约束采样中使用的生成器/判别器/语言模型。
代码和数据集地址:https://github.com/kepei1106/ARAML
表 4:在 COCO 和 EMNLP2017 WMT 数据集上的自动评估结果。每个指标对应的数字是均值和标准差。
表 5:在 WeiboDial 数据集上的人工评估结果。Win、Lose 和 Tie 对应的百分比分数分别表示 ARAML 模型与基线模型对比时的胜率、负率和平率。
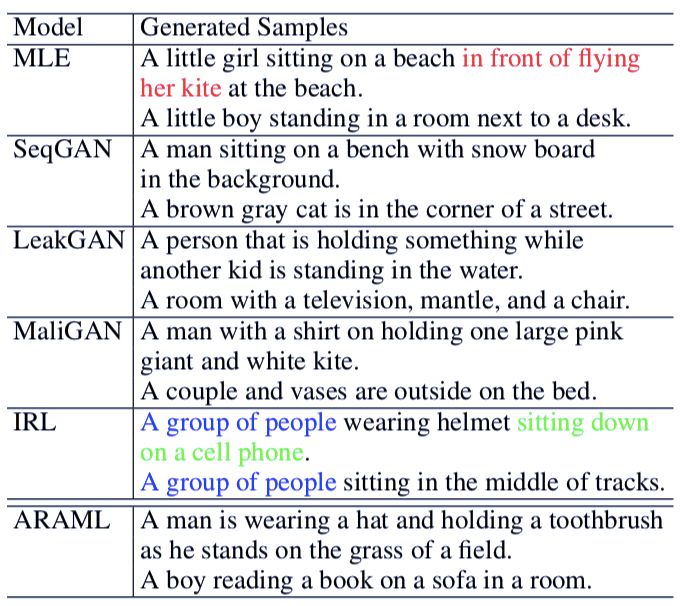
表 7 展示了模型在 COCO 数据集上生成的样本。我们可以发现,其他基线模型存在语法错误(如 MLE 模型生成样本中的「in front of flying her kite」)、重复表达(如 IRL 模型生成样本中的「A group of people」),以及不连贯表述(如 IRL 模型生成样本中的「A group of people sitting on a cell phone」)。而 ARAML 模型表现优异,它能够生成语法无误、表达连贯的句子。
![]()
表 7:在 COCO 数据集上的生成句子示例。红色字表示语法错误,蓝色文本表示重复表达,绿色文本表示不连贯表述。
表 8 展示了在 WeiboDial 数据集上的生成样本。很明显,其他基线模型没有捕捉到博文中的话题词「迟到」,从而生成了与微博正文无关的回复。而 ARAML 提供的回复无语法错误,且与微博正文的关联性强。
表 8:在 WeiboDial 数据集上的生成回复示例。
✄------------------------------------------------
加入机器之心(全职记者 / 实习生):hr@jiqizhixin.com
投稿或寻求报道:content@jiqizhixin.com
广告 & 商务合作:bd@jiqizhixin.com