军队为训练、规划和研究目的进行兵棋推演。人工智能(AI)可以通过降低成本、加快决策过程和提供新的见解来改善军事兵棋推演。以前的研究人员根据强化学习(RL)在其他人类竞技游戏中的成功应用,探讨了将强化学习(RL)用于兵棋推演。虽然以前的研究已经证明RL智能体可以产生战斗行为,但这些实验仅限于小规模的兵棋推演。本论文研究了扩展分层强化学习(HRL)的可行性和可接受性,以支持将人工智能融入大型军事兵棋推演。此外,本论文还通过探索智能体导致兵棋推演失败的方式,研究了用智能体取代敌对势力时可能出现的复杂情况。在越来越复杂的兵棋推演中,对训练封建多智能体层次结构(FMH)和标准RL智能体所需的资源以及它们的有效性进行了比较。虽然FMH未能证明大型兵棋推演所需的性能,但它为未来的HRL研究提供了启示。最后,美国防部提出了核查、验证和认证程序,作为一种方法来确保未来应用于兵棋推演的任何人工智能应用都是合适的。

引言
兵棋推演是成功军队的宝贵训练、规划和研究工具。自然,美国(U.S.)国防部(DOD)计划将人工智能(AI)纳入兵棋推演。将人工智能融入兵棋推演的一种方式是用智能体取代人类玩家;能够展示战斗行为的算法。本论文研究了用智能体取代人类兵棋推演操作员的可行性、可接受性和适宜性。为此,本章解释了为什么兵棋推演对成功的军队至关重要。
A. 军方为什么要进行兵棋推演
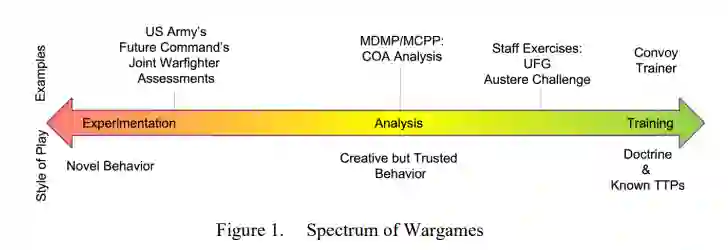
军队进行兵棋推演是为了回答关于战争的关键问题,这些问题必须在实际冲突发生之前被理解。兵棋推演是利用对立的力量模拟实际的战斗,并由人类的决策来决定[1]。虽然有广泛的不同类型的兵棋推演,但它们都有一个共同的目标:"获得有效和有用的知识" [2]。这种划分很重要,因为兵棋推演的不同目的会导致玩家和游戏控制者的行为不同。图1显示了兵棋推演从训练到分析到实验的广泛范围。
1.训练用的兵棋推演
最直接的兵棋推演类型是用于训练的兵棋推演。大型参谋部使用建设性的模拟(数字兵棋推演)来锻炼他们的参谋过程,并验证他们的军事准备。小型参谋部使用虚拟模拟器来训练他们的战斗演习和船员演习。军队进行这些兵棋推演是为了了解战争和锻炼决策能力[3]。所有队员的行动和决策一般都要符合已知的条令和战术、技术和程序(TTP)。对于大型的参谋部演习,对手可能会突破TTP的界限来挑战参谋部(例如,表现得更有侵略性,但仍然依赖相同的TTP)。
2.用于分析的兵棋推演
兵棋推演可用于分析,即 "确定在部队对抗中会发生什么"[3]。这些是大多数军事人员所熟悉的兵棋推演类型:作为行动方案(COA)分析的一部分而进行的兵棋推演。这些类型的兵棋推演允许对战争计划、部队结构或理论进行评估。在这些战役中,双方都要采用已知的理论和TTP,但 "在这些战役中,创新精神可以自由发挥"[4]。
3.实验性的兵棋推演
在谱的另一端是实验性兵棋推演。在这些战役中,双方都可以使用新的力量、武器和/或战术来探索潜在的未来战争[5]。归根结底,组织进行实验性兵棋推演是为了产生 "关于战争问题性质的知识"[2]。美国军方在演习中整合了这些类型的兵棋推演,如美国陆军未来司令部的聚合项目和联合作战人员评估。
4.兵棋推演的好处
尽管兵棋推演既不是预测性的,也不是对现实的完全复制,但它们确实提供了一些没有实战就无法获得的东西:对战争中决策的洞察力。当为训练而进行战争演习时,组织正在学习良好的决策是什么样子的(包括过程和最终结果)。当为分析而进行战争演习时,计划者正在评估他们在计划期间做出的决定,以及在执行期间需要做出的潜在决定。
这些好处足以让美国防部副部长罗伯特-沃克在2015年发布了一份备忘录,呼吁在整个美国防部重新努力开展兵棋推演[6]。沃克副部长认为,兵棋推演有利于创新、风险管理和专业军事教育。沃克认为,最终,兵棋推演将推动美国防部的规划、计划、预算和执行过程,这是告知国防部资源分配的方法。美国和它的西方盟友并不是唯一相信兵棋推演好处的军队。中国正在为兵棋推演投入大量资源,包括将人工智能融入兵棋推演[7]。
B.兵棋推演中的人工智能
人工智能提供了一个机会,通过降低成本、加快决策过程和提供新的见解来改善军事兵棋推演。为兵棋推演中的许多角色雇用人类操作员是昂贵的。组织必须给自己的人员分配任务(使他们脱离正常的职能)或支付外部支持。这种成本可以通过将人工智能整合到兵棋推演中而消除。兵棋推演分析的速度只能和人类操作者一样快。用智能体代替操作员可以加快兵棋推演的速度,并允许多个兵棋推演同时发生,从而实现更广泛的分析。最后,智能体因其在游戏中的创造性而受到关注[8]。创造性的智能体可以通过探索人类战争者可能没有考虑的可能性,使战争计划、部队编队或战术得到更好的分析。
美国国内的国家安全组织认识到将人工智能融入兵棋推演的潜力。人工智能国家安全委员会在其最终报告中主张立即将人工智能能力整合到兵棋推演中,以确保美国及其盟友保持与同行的竞争力[9]。美国陆军未来的模拟训练系统--合成训练环境(STE)设想整合人工智能来监测和调整训练场景的难度[10]。美国陆军研究实验室有许多项目在调查人工智能与军事指挥和控制系统的整合。具体来说,他们正在探索使用人工智能的一个子领域,即强化学习(RL)来进行连续规划,以开发 "蓝色部队的新计划"[11]。连续规划将需要一个能够评估其计划的智能体,可能通过兵棋推演。
基于其他RL智能体在人类竞技游戏中的成功,如《星际争霸II》[12]、《古人防御》(DotA)[13]和围棋[14],多名研究人员正在研究用于战争游戏的RL智能体。像《星际争霸II》和DotA这样的实时战略(RTS)游戏最能代表兵棋推演。与兵棋推演类似,RTS游戏需要在有限的信息环境中进行长期的目标规划和短期的战术决策。以前的研究表明,RL智能体可以在兵棋推演中复制理想的战斗行为[5], [11]。根据Kania和McCaslin的说法,谷歌的AlphaGo成功击败了世界上最好的围棋大师,证明了人工智能可以应用于兵棋推演[7]。
C. 问题陈述
虽然以前的研究已经证明RL智能体可以产生战斗行为,但实验仅限于小型交战。研究人员只要求RL智能体控制三到五个下属单位。强化学习智能体将需要成功扩展,以满足涉及几百个单位的大型兵棋推演的规模要求。
问题是,随着兵棋推演中单位数量和类型的增加,信息量和可能的动作数量变得难以解决。Newton等人提出可扩展性是一组目标:速度、收敛和性能,同时保持在一组约束条件下:随着项目规模的增加,成本、计算能力和时间[15] 。分层组织是扩展的一种方法。本论文将研究分层强化学习(HRL)的可扩展性。换句话说,任何可行的、可接受的人工智能集成到战争游戏中,随着战争游戏中单位数量的增加,必须仍然显示出理想的战斗行为。
除了将人工智能整合到军事兵棋推演中的可行性和可接受性之外,这种整合还需要是合适的。开发和执行一个失败的兵棋推演是有可能的,因为从中得出的知识是无效的或没有用的。Weuve等人[16]解释了可能导致兵棋推演失败的不同途径,他们称之为兵棋推演病症。以取代人类操作者为目的的智能体的设计和实施,需要防止兵棋推演的病态,从而确保有效的结果。
这导致了以下的研究问题。HRL是否允许智能体在不损失性能的情况下增加合作单位的数量和有效性?什么框架可以确保智能体的设计和应用正确,以满足兵棋推演的目的?
D. 研究范围
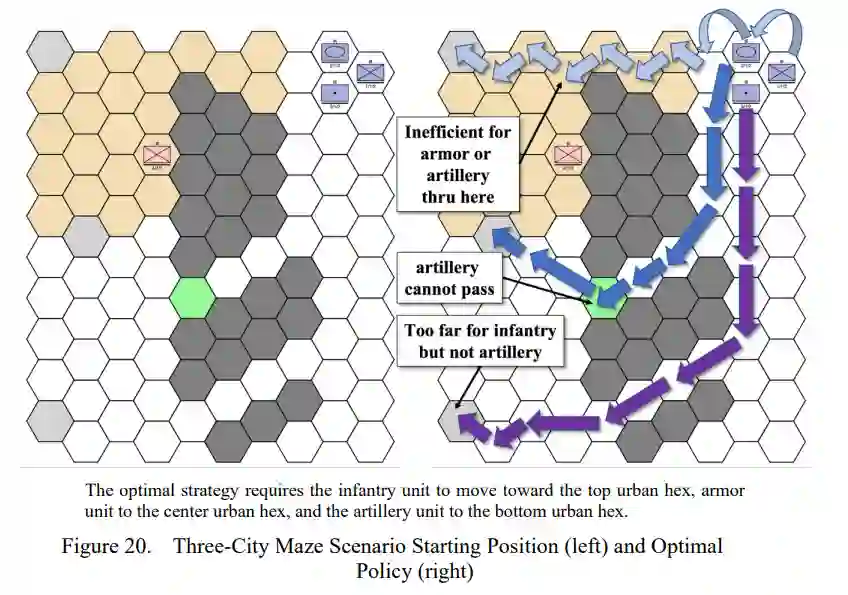
本论文延续了[17]和[18]对Atlatl战斗环境中RL的调查。Atlatl是一个离散的、基于六边形的兵棋推演,模拟陆地作战行动。最初的研究使用一个简单的多层感知器[17]成功地在RL智能体中产生了战斗行为。随后的研究使用卷积神经网络(CNN)架构在复杂的地形和动态的对手中研究RL智能体[18]。
虽然有广泛的HRL方法,但本研究的重点是封建多智能体层次结构(FMH)。在FMH中,一个单一的R智能体(即经理),将任务分配给一系列被称为工人的下级RL智能体[19]。本论文比较了在Atlatl中越来越大的场景中采用基于规则的智能体、单一RL智能体和FMH所需的资源和有效性。
兵棋推演是由玩家和裁判员组成的[1]。友军单位的玩家被称为蓝军,他们的对手被称为红军,任何一个玩家之外的平民或军事单位被称为绿军。虽然有可能通过使用所有玩家和裁判员的智能体来实现兵棋推演的完全自动化,但本论文只评估了对单个玩家的替换。
本论文还研究了用智能体替换对方部队(OPFOR)即红色部队时可能出现的复杂情况。讨论了具体的兵棋推演病症,并提出了缓解这些病症的方法。美国防部的验证、核实和认证(VV&A)框架被应用于通过RL对OPFOR的建模。
E. 研究结果
本论文发现,当FMH智能体以分布式方式进行训练时,FMH智能体未能比单一RL智能体表现得更好。当经理和工人在同一环境中训练时,FMH智能体的学习能力有所提高。然而,工人的不一致行动使经理无法制定最佳策略。此外,FMH的训练要求超过了单个RL智能体的要求,这抑制了FMH扩展到大型军事兵棋推演的能力。最后,本论文发现,将人工智能整合到军事兵棋推演中的方法适合于像美国防部的VV&A框架那样的过程。否则,基于模型的去太原的病症会使兵棋推演的目标失效,并对美军产生负面影响。
F. 论文对研究的贡献
本论文通过进一步研究在建设性模拟中采用完全自主的智能体,对美国政府有直接好处。完全自主的兵棋推演智能体,能够在多个层次上运作,需要支持兵棋推演的全部范围。这很容易延伸到军事规划期间的决策支持工具,协助规划者快速评估不同的COA。此外,探索在兵棋推演中使用智能体的适宜性将促进兵棋推演界采用人工智能。