【摘要】抽取式摘要:TextRank和BertSum。
一:内容预告
本文介绍抽取式文本摘要。
文本摘要,按摘要输出的类型,可以分为抽取式摘要(Extractive)和生成式摘要(Abstractive)。
抽取式好比老实人,温顺服从,循规蹈矩,不敢越雷池半步。
抽取式摘要直接从原文中摘取完整的句子,作为文章的摘要,保证摘要在语法和事实上的正确性,但无法做到概括文章内容和结合外部知识,缺乏惊艳之感,意外之喜。
生成式好比游侠儿,白马饰金羁,连翩西北驰,金鳞岂是池中物。
生成式摘要可以产生原文中没有的单词和短语,给人耳目一新之感,但是容易野马脱缰,返回不符合语法和事实的结果。
抽取式摘要的方法,包括传统的聚类法和图方法,以及基于深度学习的序列标注法或句子排序法。
本文主要关注以下三个问题:
如何用聚类法做抽取式摘要?
如何用图方法做抽取式摘要?
如何用深度学习的方法做抽取式摘要?
二:聚类法做抽取式摘要
基于聚类法的抽取式摘要,是无监督的文本摘要方法。
一种做法是把整篇文章看做聚类中心,首先计算聚类中心的向量表示。
再把文章拆分成多条完整的句子,计算所有句子与聚类中心的距离或相似度,进行排序,取相似度得分最高的topk个句子,作为摘要。
下面是之前做的新闻自动摘要系统,输入新闻标题和正文,就可以输出新闻摘要。

这种做法有两点比较关键:
一是如何得到更好的句向量。
普林斯顿大学出品的SIF句向量是一种简单有效的方法,比较适合长文本的向量化。
二是如何恰当地切分句子。
如包含书名号和双引号的句子,如何拆分。
这种做法的缺点也比较明显。
一是部分作为摘要的句子太长了,没有进行信息提炼,有违摘要的本质。
二是更长的句子,蕴含的语义信息更丰富,与聚类中心的距离更近,更容易被选取为摘要,显得不够精炼。
当然,也可以使用 K-means 进行句子聚类,将句子分为N个类别。
然后从每个类别中,选择距离聚类中心最近的一个句子,一共得到N个句子,作为最终的摘要。
三:图方法做抽取式摘要
基于图方法的抽取式摘要,是无监督的文本摘要,使用的是TextRank算法。
TextRank源自于PageRank。
PageRank是互联网网页排序的方法,经过轻微的修改,成为TextRank,可用于关键词提取和文本摘要。
PageRank的思想是,对于每个网页都给出一个正实数,也就是PageRank值,表示网页的重要程度。
PageRank值越高,表示网页越重要,在互联网搜索的排序中越可能被排在前面。
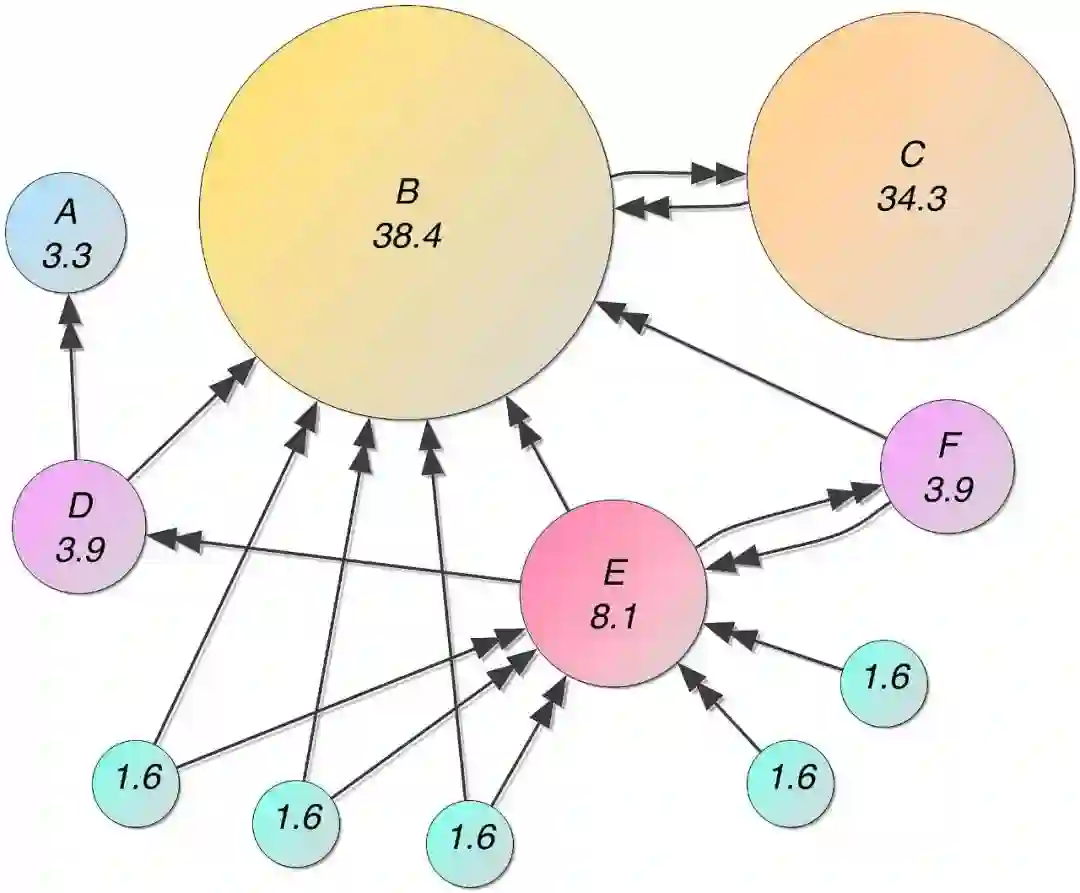
假设互联网是一个有向图,节点是网页,每条边附有转移概率。
网页浏览者在每个页面上依照超链接,以等概率跳转到下一个网页,并且在网页上持续不断地进行这样的随机跳转。
整个过程形成了一阶马尔科夫链。
在不断地跳转之后,这个马尔科夫链会形成一个平稳分布,而PageRank就是这个平稳分布,每个网页的PageRank值就是平稳概率。
修改为TexrRank后,公式如下:
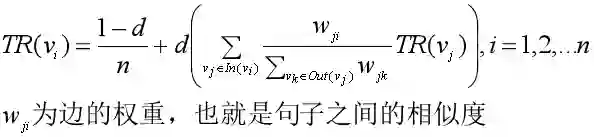
在抽取式文本摘要中,TextRank和PageRank的相似之处在于:
用句子类比于网页
任意两个句子的相似度类比于网页转换概率
相似度得分存储在一个方形矩阵中,类比于PageRank的转移概率矩阵
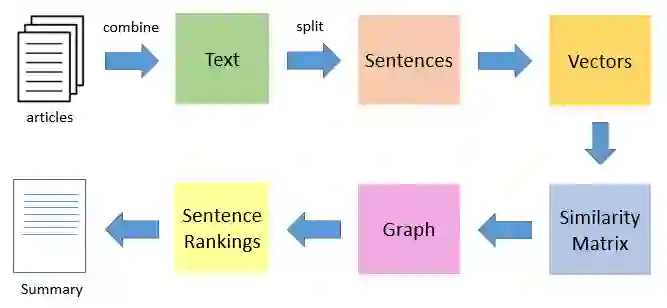
用TextRank做单领域多文本的自动摘要,过程如下:
把所有文章分割成完整的单句,并整合在一起
计算所有句子的向量表示
计算所有句子的相似度,存放在矩阵中,作为转移概率矩阵
将转移概率矩阵转换为以句子为节点、相似度得分为边的图结构,用于计算句子的TextRank值
按TextRank值对句子进行排序,取topk句子作为摘要。
咦,上面的内容怎么和博客园的一篇文章差不多啊?
是的,因为那篇文章是我写的。
具体的实现,用networkx这个库,可参考我之前在博客园写的文章:
https://www.cnblogs.com/Luv-GEM/p/10884493.html
四:深度学习做抽取式摘要
基于深度学习的抽取式摘要,是有监督的文本摘要,可以建模为序列标注任务或句子排序任务。
建模为序列标注任务,就是为原文中的每一个句子打一个二分类标签(0 或 1),0 代表该句不属于摘要,1 代表该句属于摘要,训练一个标注模型。
所有标注为1的句子,可以作为最终的摘要。
建模为句子排序任务,则是输出每个句子作为摘要的概率,选择概率最大的topk个句子,作为最终的摘要。
《Fine-tune BERT for Extractive Summarization》这篇论文,就是把抽取式摘要,建模为序列标注任务和句子排序任务。
论文对BERT的输入层和Fine-Tuning层进行了修改,使其适用于抽取式文本摘要任务。
论文中的BertSum模型,在CNN/Dailymail和NYT数据集上都表现优异,是当前用深度学习做抽取式摘要的SOTA模型。
论文地址:https://arxiv.org/pdf/1903.10318.pdf
源码地址:https://github.com/nlpyang/BertSum
BERT是用MLM和NSP两大任务来进行预训练的,因此输入是token序列,输出则是token序列的向量表示,而不是句子级别的向量表示。
另外,尽管对于句对任务(如文本匹配),BERT使用了 Segment Embedding 来区分两条不同的句子(EA, EB),但是抽取式摘要,输入的是两条以上的句子。
因此,论文对输入层进行了修改,以便于对多条句子进行编码。

(一)Encoding Multiple Sentences
在每个句子开头加一个[CLS]标记,在末尾加一个[SEP]标记。
(二)Interval Segment Embeddings
对于句子senti,如果i是奇数,那么Segment Embedding为EA,i为偶数,则为EB,以此来区分不同的句子。
如果输入5个句子,那么对应的Segment Embeddings为:
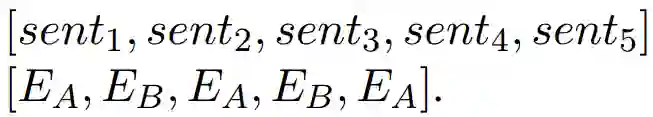
相对位置编码(Position Embeddings)就和原生BERT一致了。
经过BERT的预训练层,得到每个[CLS]标记的向量Ti,作为每个句子的特征向量。
论文定义了三种摘要层,叠加在BERT的预训练层上,进行联合训练,做Fine-Tuning。
(一)加线性层
在预训练层加一个简单的线性层,做Sigmoid,得到每个句子作为摘要的概率。
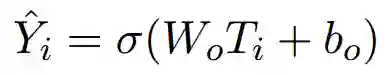
(二)加Transformer层
在预训练层加1个或多个Transformer层,用于提取文档级别的特征,再做Sigmoid。
首先用一个PosEmb函数,把每个句子的位置编码,和每个句子的向量表示Ti结合。
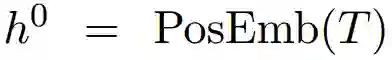
然后送入Transformer层,用多头注意力机制(Multi-Head Attention)和层归一化(Layer Normalization),提取文档级特征。
L表示Transformer的层数,作者分别取1、2、3进行实验,发现L=2时效果最好。
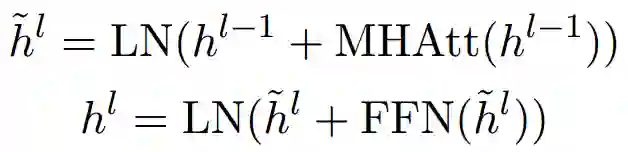
经过L层Transformer做信息提取,得到最终的向量表示hiL,进而对每个句子进行标注(或者说二分类)。

(三)加LSTM层
在预训练层加LSTM层,最终的向量表示hi不是LSTM最后一步的隐状态,而是每一步向上输出的向量,最后再做Sigmoid。

得到每个句子作为摘要的概率后,计算二元交叉熵损失,来更新模型参数。
(一)减少摘要冗余
作者选取在验证集上表现最好的前3个模型,在测试集上进行评估,评估结果取三个模型的平均。
在测试阶段,输入一篇文档,输出所有句子作为摘要的概率,取概率最高的三个句子,作为最终的摘要。
同时,作者采用 Trigram Blocking 的方法,去掉可能造成冗余的摘要句。
具体的做法是,给定已经抽取出来的部分摘要S(多个句子组成),和一个候选句子c,如果S和c之间存在一个重合的语块(由三个单词构成),那么就略过句子c。
(二)实验结果
BertSum模型在两大数据集上进行测试:CNN/DailyMail和NYT,用ROUGE F1 (R-1、R-2 和R-L)作为评估指标,并与多个模型进行对比。
其中,在CNN/DailyMail上的测试结果如下。
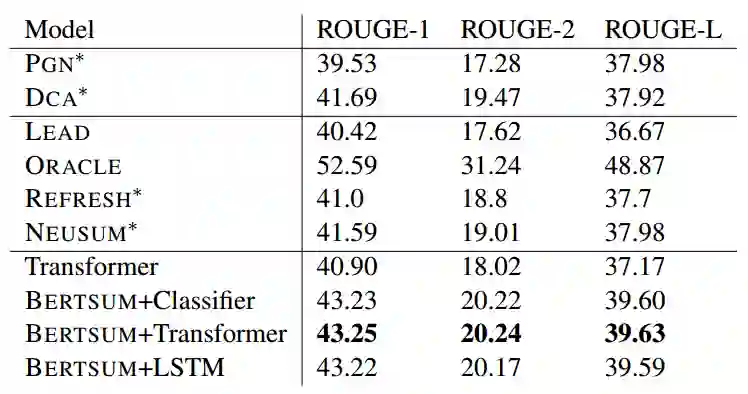
从不同模型的对比来看,BertSum模型以较大的优势摘得桂冠,成为新的SOTA。
从自定义的摘要层来看,加Transformer层的BertSum模型,在三个分指标上,都优于加线性层和LSTM层的模型。
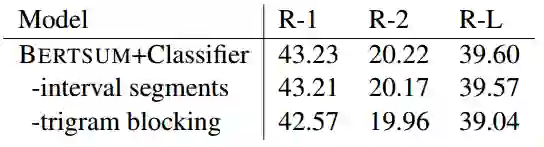
此外,进一步的实验表明,Interval Segment Embeddings和Trigram Blocking的引入,都有利于提升模型的效果。
参考资料:
1:《统计学习方法》(第二版)
2:《Fine-tune BERT for Extractive Summarization》