R语言自然语言处理:关键词提取与文本摘要(TextRank)

作者:黄天元,复旦大学博士在读,目前研究涉及文本挖掘、社交网络分析和机器学习等。希望与大家分享学习经验,推广并加深R语言在业界的应用。
邮箱:huang.tian-yuan@qq.com
关于提取关键词的方法,除了TF-IDF算法,比较有名的还有TextRank算法。它是基于PageRank衍生出来的自然语言处理算法,是一种基于图论的排序算法,以文本的相似度作为边的权重,迭代计算每个文本的TextRank值,最后把排名高的文本抽取出来,作为这段文本的关键词或者文本摘要。之所以提到关键词和文本摘要,两者其实宗旨是一样的,就是自动化提取文本的重要表征文字。
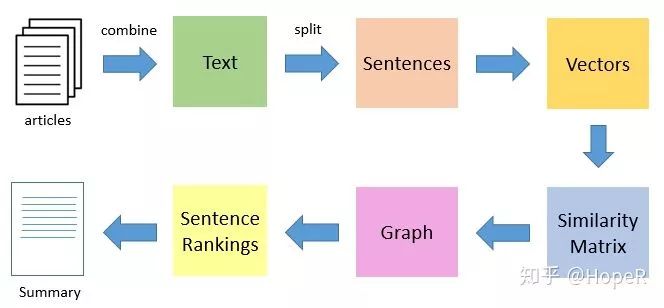
如果分词是以词组作为切分,那么得到的是关键词。以词作为切分的时候,构成词与词之间是否连接的,是词之间是否相邻。相邻关系可以分为n元,不过在中文中,我认为2元关系已经非常足够了(比如一句话是:“我/有/一只/小/毛驴/我/从来/也/不/骑”,那么设置二元会让“一只”和“毛驴”发生关联,这就足够了)。如果是以句子切分的,那么得到的称之为文本摘要(其实就是关键的句子,俗称关键句)。如果要得到文本的关键句子,还是要对每句话进行分词,得到每句话的基本词要素。根据句子之间是否包含相同的词语,我们可以得到句子的相似度矩阵,然后再根据相似度矩阵来得到最关键的句子(也就是与其他句子关联性最强的那个句子)。当句子比较多的时候,这个计算量是非常大的。 下面,我要用R语言的textrank包来实现关键词的提取和文本摘要。
安装必备的包。
1library(pacman)
2p_load(tidyverse,tidytext,textrank,rio,jiebaR)
然后,导入数据。数据可以在我的github中获得(github.com/hope-data-sc)。文件名称为hire_text.rda。
1import("./hire_text.rda") -> hire_text
2hire_text
这里面包含了互联网公司的一些招聘信息,一共有4102条记录,只有一列,列名称为hire_text,包含了企业对岗位要求的描述。
因为要做关键词和关键句的提取,因此我们要进行分词和分句。分词还是利用jiebaR,老套路。如果没有了解的话,请看专栏之前的文章(R语言自然语言处理系列)。不过这次,我们希望能够在得到词频的同时,得到每个词的词性,然后只把名词提取出来。 分词代码如下:
1hire_text %>%
2 mutate(id = 1:n()) -> hire_txt #给文档编号
3
4worker(type = "tag") -> wk #构造一个分词器,需要得到词性
5
6hire_txt %>%
7 mutate(words = map(hire_text,tagging,jieba = wk)) %>% #给文档进行逐个分词
8 mutate(word_tag = map(words,enframe,name = "tag",value = "word")) %>%
9 select(id,word_tag) -> hire_words
然后,我们分组进行关键词提取。
1#构造提取关键词的函数
2
3extract_keywords = function(dt){
4 textrank_keywords(dt$word,relevant = str_detect(dt$tag,"^n"),ngram_max = 2) %>%
5 .$keywords
6}
7
8hire_words %>%
9 mutate(textrank.key = map(word_tag,extract_keywords)) %>%
10 select(-word_tag) -> tr_keyword
现在我们的数据框中,包含了每个文档的关键词。每个关键词列表中,包含freq和ngram两列,freq代表词频,ngram代表多少个n元,2元就是“上海市-闵行区”这种形式,1元就是“上海市”、“闵行区”这种形式。 现在,我要从中挑选每篇文章最重要的3个关键词。挑选规则是:词频必须大于1,在此基础上,n元越高越好。
1tr_keyword %>%
2 unnest() %>%
3 group_by(id) %>%
4 filter(freq > 1) %>%
5 top_n(3,ngram) %>%
6 ungroup() -> top3_keywords
7
8top3_keywords
9## # A tibble: 3,496 x 4
10## id keyword ngram freq
11## <int> <chr> <int> <int>
12## 1 1 上海市-长宁区 2 2
13## 2 1 长宁区 1 2
14## 3 1 上海市-静安区 2 2
15## 4 4 客户 1 4
16## 5 5 招商银行 1 2
17## 6 6 事业部 1 3
18## 7 7 房地产 1 2
19## 8 9 技术 1 3
20## 9 10 电商 1 2
21## 10 10 协调 1 2
22## # ... with 3,486 more rows
仔细观察发现,有的文档就没有出现过,因为他们分词之后,每个词的词频都是1。现在让我们统计一下最火的十大高频词。
1top3_keywords %>%
2 count(keyword) %>%
3 arrange(desc(n)) %>%
4 slice(1:10)
5## # A tibble: 10 x 2
6## keyword n
7## <chr> <int>
8## 1 客户 298
9## 2 公司 173
10## 3 产品 110
11## 4 能力 97
12## 5 项目 89
13## 6 技术 51
14## 7 市场 48
15## 8 系统 48
16## 9 广告 41
17## 10 企业 41
这些词分别是:客户、公司、产品、能力、项目、技术、市场、系统、广告、企业。
文本摘要其实就是从文档中提出我们认为最关键的句子。我们会用textrank包的textrank_sentences函数,这要求我们有一个分句的数据框,还有一个分词的数据框(不过这次需要去重复,也就是说分词表中每个文档不能有重复的词)。非常重要的一点是,这次分词必须以句子为单位进行划分。 我们明确一下任务:对每一个招聘文档,我们要挑选出这个文档中最关键的一句话。要解决这个大问题,需要先解决一个小问题。就是对任意的一个长字符串,我们要能够切分成多个句子,然后按照句子分组,对其进行分词。然后我们会得到一个句子表格和单词表格。 其中,我们切分句子的标准是,切开任意长度的空格,这在正则表达式中表示为“[:space:]+”。
1get_sentence_table = function(string){
2 string %>%
3 str_split(pattern = "[:space:]+") %>%
4 unlist %>%
5 as_tibble() %>%
6 transmute(sentence_id = 1:n(),sentence = value)
7}
上面这个函数,对任意的一个字符串,能够返回一个含有两列的数据框,第一列是句子的编号sentence_id,另一列是句子内容sentence。我们姑且把这个数据框称之为sentence_table。 下面我们要构造另一个函数,对于任意的sentence_table,我们需要返回一个分词表格,包含两列,第一列是所属句子的编号,第二列是分词的单词内容。
1wk = worker() #在外部构造一个jieba分词器
2
3get_word_table = function(string){
4 string %>%
5 str_split(pattern = "[:space:]+") %>%
6 unlist %>%
7 as_tibble() %>%
8 transmute(sentence_id = 1:n(),sentence = value) %>%
9 mutate(words = map(sentence,segment,jieba = wk)) %>%
10 select(-sentence) %>%
11 unnest()
12}
如果分词器要在内部构造,每次运行函数都要构造一次,会非常消耗时间。 目前,对于任意一个字符串,我们有办法得到它的关键句了。我们举个例子:
1hire_text[[1]][1] -> test_text
2test_text %>% get_sentence_table -> st
3st %>% get_word_table -> wt
4## Warning in stri_split_regex(string, pattern, n = n, simplify = simplify, :
5## argument is not an atomic vector; coercing
有了这st和wt这两个表格,现在我们要愉快地提取关键句子。
1textrank_sentences(data = st,terminology = wt) %>%
2 summary(n = 1) #n代表要top多少的关键句子
3## [1] "1279弄6号国峰科技大厦"
我们给这个取最重要关键句子也编写一个函数。
1get_textrank_sentence = function(st,wt){
2 textrank_sentences(data = st,terminology = wt) %>%
3 summary(n = 1)
4}
因为数据量比较大,我们只求第10-20条记录进行求解。不过,如果句子只有一句话,那么是会报错的。因此我们要首先去除一个句子的记录。
1hire_txt %>%
2 slice(10:20) %>%
3 mutate(st = map(hire_text,get_sentence_table)) %>%
4 mutate(wt = map(hire_text,get_word_table)) %>%
5 mutate(sentence.no = unlist(map(st,nrow))) %>%
6 select(-hire_text) %>%
7 filter(sentence.no != 1) %>%
8 mutate(key_sentence = unlist(map2(st,wt,get_textrank_sentence))) %>%
9 select(id,sentence.no,key_sentence) -> hire_abstract
10
11hire_abstract
12## # A tibble: 10 x 3
13## id sentence.no key_sentence
14## <int> <int> <chr>
15## 1 10 9 开拓电商行业潜在客户
16## 2 11 5 EHS
17## 3 12 9 负责招聘渠道的维护和更新;
18## 4 13 6 荣获中国房地产经纪百强企业排名前六强;
19## 5 14 7 2、逻辑思维、分析能力强,工作谨慎、认真,具有良好的书面及语言表达能力;~
20## 6 15 5 2、能独立完成栏目包装、影视片头、广告片、宣传片的制作,包括创意图设计、动画制作、特效、剪辑合成等工作;~
21## 7 16 7 3、公司为员工提供带薪上岗培训和丰富的在职培训,有广阔的职业发展与晋升空间;~
22## 8 17 7 您与该职位的匹配度?
23## 9 18 13 接触并建立与行业内重点企业的良好关系,及时了解需求状态;~
24## 10 20 7 具有财务、金融、税务等领域专业知识;具有较强分析判断和解决问题的能力;~
如果对所有记录的摘要感兴趣,去掉slice(10:20) %>%这一行即可。等待时间可能会较长。
实践证明,TextRank算法是一个比较耗时的算法,因为它依赖于图计算,需要构成相似度矩阵。当数据量变大的时候,运行时间会呈“几何级”增长。但是对于中小型的文本来说,这个方法还是非常不错的。但是中小型的文本,还需要摘要么?尽管如此,这还是一个非常直观的算法,如果TF-IDF在一些时候不好用的话,这是一个非常好的候补选项。
textrank包基本教程
http://blog.itpub.net/31562039/viewspace-2286669/
手把手 | 基于TextRank算法的文本摘要(附Python代码)
http://blog.itpub.net/31562039/viewspace-2286669/

往期精彩:

公众号后台回复关键字即可学习
回复 爬虫 爬虫三大案例实战
回复 Python 1小时破冰入门
回复 数据挖掘 R语言入门及数据挖掘
回复 人工智能 三个月入门人工智能
回复 数据分析师 数据分析师成长之路
回复 机器学习 机器学习的商业应用
回复 数据科学 数据科学实战
回复 常用算法 常用数据挖掘算法
给我【好看】
你也越好看!



