手把手 | 基于TextRank算法的文本摘要(附Python代码)

大数据文摘授权转载自数据派THU
作者:Prateek Joshi
翻译:王威力
校对:丁楠雅
TextRank 算法是一种用于文本的基于图的排序算法,通过把文本分割成若干组成单元(句子),构建节点连接图,用句子之间的相似度作为边的权重,通过循环迭代计算句子的TextRank值,最后抽取排名高的句子组合成文本摘要。本文介绍了抽取型文本摘要算法TextRank,并使用Python实现TextRank算法在多篇单领域文本数据中抽取句子组成摘要的应用。
介绍
文本摘要是自然语言处理(NLP)的应用之一,一定会对我们的生活产生巨大影响。随着数字媒体的发展和出版业的不断增长,谁还会有时间完整地浏览整篇文章、文档、书籍来决定它们是否有用呢?值得高兴的是,这项技术已经在这里了。
你有没有用过inshorts这个手机app?它是一个创新的新闻app,可以将新闻文章转化成一篇60字的摘要,这正是我们将在本文中学习的内容——自动文本摘要。
自动文本摘要是自然语言处理(NLP)领域中最具挑战性和最有趣的问题之一。它是一个从多种文本资源(如书籍、新闻文章、博客帖子、研究类论文、电子邮件和微博)生成简洁而有意义的文本摘要的过程。
由于大量文本数据的可获得性,目前对自动文本摘要系统的需求激增。
通过本文,我们将探索文本摘要领域,将了解TextRank算法原理,并将在Python中实现该算法。上车,这将是一段有趣的旅程!
目录
一、文本摘要方法
二、TextRank算法介绍
三、问题背景介绍
四、TextRank算法实现
五、下一步是什么?
一、文本摘要方法
早在20世纪50年代,自动文本摘要已经吸引了人们的关注。在20世纪50年代后期,Hans Peter Luhn发表了一篇名为《The automatic creation of literature abstract》的研究论文,它利用词频和词组频率等特征从文本中提取重要句子,用于总结内容。
参考链接:
http://courses.ischool.berkeley.edu/i256/f06/papers/luhn58.pdf
另一个重要研究是由Harold P Edmundson在20世纪60年代后期完成,他使用线索词的出现(文本中出现的文章题目中的词语)和句子的位置等方法来提取重要句子用于文本摘要。此后,许多重要和令人兴奋的研究已经发表,以解决自动文本摘要的挑战。
参考链接:
http://courses.ischool.berkeley.edu/i256/f06/papers/luhn58.pdf
文本摘要可以大致分为两类——抽取型摘要和抽象型摘要:
抽取型摘要:这种方法依赖于从文本中提取几个部分,例如短语、句子,把它们堆叠起来创建摘要。因此,这种抽取型的方法最重要的是识别出适合总结文本的句子。
抽象型摘要:这种方法应用先进的NLP技术生成一篇全新的总结。可能总结中的文本甚至没有在原文中出现。
本文,我们将关注于抽取式摘要方法。
二、TextRank算法介绍
在开始使用TextRank算法之前,我们还应该熟悉另一种算法——PageRank算法。事实上它启发了TextRank!PageRank主要用于对在线搜索结果中的网页进行排序。让我们通过一个例子快速理解这个算法的基础。
PageRank算法简介:
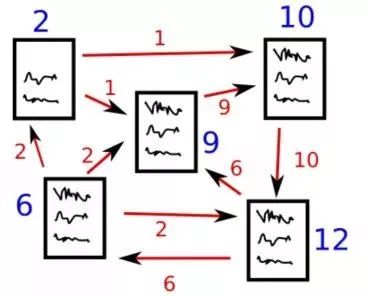
图 1 PageRank算法
假设我们有4个网页——w1,w2,w3,w4。这些页面包含指向彼此的链接。有些页面可能没有链接,这些页面被称为悬空页面。
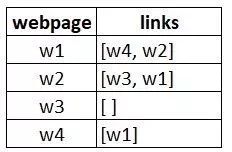
w1有指向w2、w4的链接
w2有指向w3和w1的链接
w4仅指向w1
w3没有指向的链接,因此为悬空页面
为了对这些页面进行排名,我们必须计算一个称为PageRank的分数。这个分数是用户访问该页面的概率。
为了获得用户从一个页面跳转到另一个页面的概率,我们将创建一个正方形矩阵M,它有n行和n列,其中n是网页的数量。
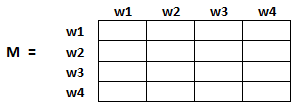
矩阵中得每个元素表示从一个页面链接进另一个页面的可能性。比如,如下高亮的方格包含的是从w1跳转到w2的概率。
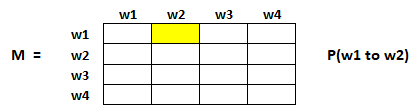
如下是概率初始化的步骤:
1. 从页面i连接到页面j的概率,也就是M[i][j],初始化为1/页面i的出链接总数wi
2. 如果页面i没有到页面j的链接,那么M[i][j]初始化为0
3. 如果一个页面是悬空页面,那么假设它链接到其他页面的概率为等可能的,因此M[i][j]初始化为1/页面总数
因此在本例中,矩阵M初始化后如下:
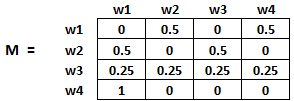
最后,这个矩阵中的值将以迭代的方式更新,以获得网页排名。
三、TextRank算法
现在我们已经掌握了PageRank,让我们理解TextRank算法。我列举了以下两种算法的相似之处:
用句子代替网页
任意两个句子的相似性等价于网页转换概率
相似性得分存储在一个方形矩阵中,类似于PageRank的矩阵M
TextRank算法是一种抽取式的无监督的文本摘要方法。让我们看一下我们将遵循的TextRank算法的流程:
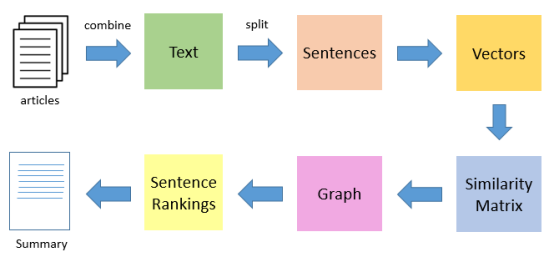
1. 第一步是把所有文章整合成文本数据
2. 接下来把文本分割成单个句子
3. 然后,我们将为每个句子找到向量表示(词向量)。
4. 计算句子向量间的相似性并存放在矩阵中
5. 然后将相似矩阵转换为以句子为节点、相似性得分为边的图结构,用于句子TextRank计算。
6. 最后,一定数量的排名最高的句子构成最后的摘要。
让我们启动Jupyter Notebook,开始coding!
备注:如果你想了解更多图论知识,我推荐你参考这篇文章
https://www.analyticsvidhya.com/blog/2018/09/introduction-graph-theory-applications-python/
三、问题背景介绍
作为一个网球爱好者,我一直试图通过对尽可能多的网球新闻的阅读浏览来使自己随时了解这项运动的最新情况。然而,事实证明这已经是一项相当困难的工作!花费太多的资源和时间是一种浪费。
因此,我决定设计一个系统,通过扫描多篇文章为我提供一个要点整合的摘要。如何着手做这件事?这就是我将在本教程中向大家展示的内容。我们将在一个爬取得到的文章集合的文本数据集上应用TextRank算法,以创建一个漂亮而简洁的文章摘要。
请注意:这是一个单领域多文本的摘要任务,也就是说,我们以多篇文章输入,生成的是一个单要点摘要。本文不讨论多域文本摘要,但您可以自己尝试一下。
数据集下载链接:
https://s3-ap-south-1.amazonaws.com/av-blog-media/wp-content/uploads/2018/10/tennis_articles_v4.csv
四、TextRank算法实现
所以,不用再费心了,打开你的Jupyter Notebook,让我们实现我们迄今为止所学到的东西吧!
1. 导入所需的库
首先导入解决本问题需要的库
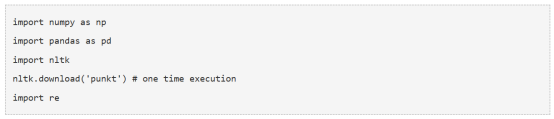
2. 读入数据
现在读取数据,在上文我已经提供了数据集的下载链接。

3. 检查数据
让我们快速了解以下数据。
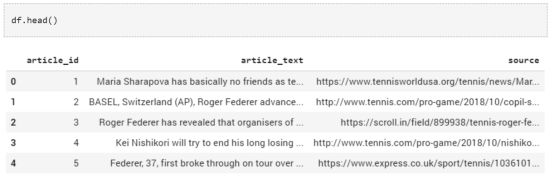
数据集有三列,分别是‘article_id’,‘article_text’,和‘source’。我们对‘article_text’列的内容最感兴趣,因为它包含了文章的文本内容。让我们打印一些这个列里的变量的值,具体看看它们是什么样。

输出:

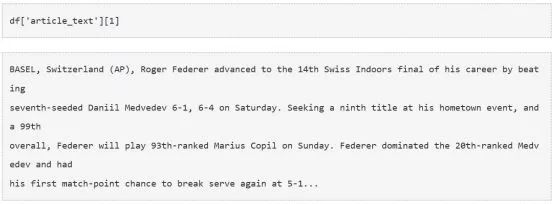
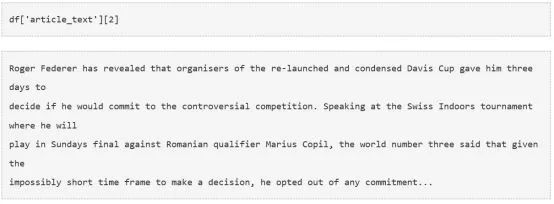
现在我们有两种选择,一个是总结单个文章,一个是对所有文章进行内容摘要。为了实现我们的目的,我们继续后者。
4. 把文本分割成句子
下一步就是把文章的文本内容分割成单个的句子。我们将使用nltk库中的sent_tokenize( )函数来实现。

打印出句子列表中的几个元素。

输出:

5. 下载GloVe词向量
GloVe词向量是单词的向量表示。这些词向量将用于生成表示句子的特征向量。我们也可以使用Bag-of-Words或TF-IDF方法来为句子生成特征,但这些方法忽略了单词的顺序,并且通常这些特征的数量非常大。
我们将使用预训练好的Wikipedia 2014 + Gigaword 5 (补充链接)GloVe向量,文件大小是822 MB。
GloVe词向量下载链接:
https://nlp.stanford.edu/data/glove.6B.zip

让我们提取词向量:
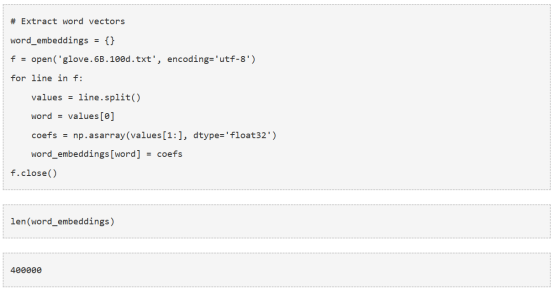
现在我们在字典中存储了400000个不同术语的词向量。
6. 文本预处理
尽可能减少文本数据的噪声是一个好习惯,所以我们做一些基本的文本清洗(包括移除标点符号、数字、特殊字符,统一成小写字母)。

去掉句子中出现的停用词(一种语言的常用词——is,am,of,in等)。如果尚未下载nltk-stop,则执行以下代码行:

现在我们可以导入停用词。

接下来定义移除我们的数据集中停用词的函数。
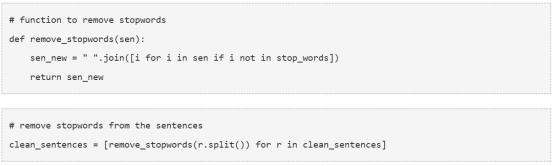
我们将在GloVe词向量的帮助下用clean_sentences(程序中用来保存句子的列表变量)来为我们的数据集生成特征向量。
7. 句子的特征向量
现在,来为我们的句子生成特征向量。我们首先获取每个句子的所有组成词的向量(从GloVe词向量文件中获取,每个向量大小为100个元素),然后取这些向量的平均值,得出这个句子的合并向量为这个句子的特征向量。
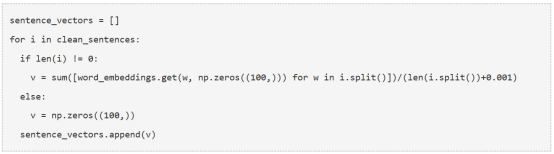
8. 相似矩阵准备
下一步是找出句子之间的相似性,我们将使用余弦相似性来解决这个问题。让我们为这个任务创建一个空的相似度矩阵,并用句子的余弦相似度填充它。
首先定义一个n乘n的零矩阵,然后用句子间的余弦相似度填充矩阵,这里n是句子的总数。

将用余弦相似度计算两个句子之间的相似度。

用余弦相似度初始化这个相似度矩阵。
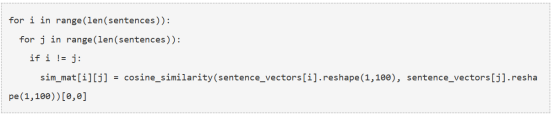
9. 应用PageRank算法
在进行下一步之前,我们先将相似性矩阵sim_mat转换为图结构。这个图的节点为句子,边用句子之间的相似性分数表示。在这个图上,我们将应用PageRank算法来得到句子排名。

10. 摘要提取
最后,根据排名提取前N个句子,就可以用于生成摘要了。
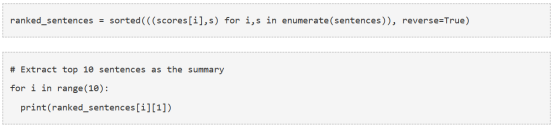

现在我们实现了一个棒极了、整齐的、简洁、有用的文章总结!
五、下一步是什么?
自动文本摘要是一个热门的研究课题,在本文中我们仅仅讨论了冰山一角。展望未来,我们将探索抽象文本摘要技术,其中深度学习扮演着重要的角色。此外,我们还可以研究下面的文本摘要任务:
1. 问题导向:
多领域文本摘要
单个文档的摘要
跨语言文本摘要
(文本来源是一种语言,文本总结用另一种语言)
2. 算法导向:
应用RNN和LSTM的文本摘要
应用加强学习的文本摘要
应用生成对抗神经网络(GAN)的文本摘要
后记
我希望这篇文章能帮助你理解自动文本摘要的概念。它有各种各样的应用案例,并且已经产生了非常成功的应用程序。无论是在您的业务中利用,还是仅仅为了您自己的知识,文本摘要是所有NLP爱好者都应该熟悉的方法。
我将在以后的文章中尝试使用高级技术介绍抽象文本摘要技术。同时,请随时使用下面的评论部分让我知道你对这篇文章的想法或任何问题。
数据集下载链接:
https://s3-ap-south-1.amazonaws.com/av-blog-media/wp-content/uploads/2018/10/tennis_articles_v4.csv
算法代码链接:
https://github.com/prateekjoshi565/textrank_text_summarization
相关报道:
https://www.analyticsvidhya.com/blog/2018/11/introduction-text-summarization-textrank-python/

365个机器学习概念
“耐撕”的AI日历
限量预售ing☟

【今日机器学习概念】
Have a Great Definition





