MIT:用无监督为世界上每个像素都打上标签!人类:再也不用为1小时视频花800个小时了
![]()
新智元报道

新智元报道
编辑:好困 snailnj
【新智元导读】MIT新算法无需标签,精细分割图像,不放过每个像素点!人类数据标注师瑟瑟发抖:我要毕业了?
趁着ICLR 2022颁奖之际,MIT、康奈尔、谷歌和微软「炫耀」了一篇全新的SOTA——
给世界上每一个像素都打上标签,而且无需人工!

论文地址:https://arxiv.org/abs/2203.08414
从对比图的效果来看,这个方法有时候甚至比人工还细致啊,甚至连阴影都做了标注。

不过遗憾是的是,虽然看着十分酷炫,但并没有入围获奖名单(包括提名)。
不放过任何一个像素!
不放过任何一个像素!
说回到CV领域,其实,给数据做标注这个问题已经困扰了学界很久。
对于人类来说,不管是牛油果还是土豆泥,甚至是「外星母舰」,只需要看一眼,就能认出来。
但是对于机器,就没这么简单了。
想制作一个用于训练的数据集,就需要在图像中把特定的内容框出来,而这件事目前来说基本只能靠人工手动进行。
比如,一只坐在草地上的狗,这时你就需要先把这只狗圈出来,并备注上——「狗」,然后再给后面那片地备注上「草」。
基于此,训练出的模型才能将「狗」和「草地」区分开。
而且,这件事情非常令人头疼。
你不去做吧,模型就很难识别出物体、人类或其他重要的图像特征。
做吧,又非常麻烦。
对人类标注者而言,分割图像比分类或目标检测要花费约100倍的精力。
仅仅是标注1个小时的数据就需要花费800个小时。
数据标注打工人:我也要毕业了?
数据标注打工人:我也要毕业了?
为了让人类不用再去忍受「标注」的折磨(当然主要还是为了推进技术的进步),刚才提到的这群科学家便提出了一种新的基于Transformer的方法「STEGO」,从而在无监督的情况下完成图像语义分割任务。
无监督语义分割的目的是在图像语料库中发现并定位具有语义意义的类别,而无需任何形式的标注。
为了解决这一问题,STEGO算法必须为每个像素生成具有重要意义且足够紧凑的特征,以形成不同的簇。
与以往的端到端的模型不同,STEGO提出了将特征学习与聚类分离的方法,会寻找出现在整个数据集中的相似图像,然后,它将这些相似的对象关联在一起,以做到像素级别的标签预测。
在CocoStuff数据集上,27种类别的无监督语义分割任务(包括地面、天空、建筑、草坪、机动车、人、动物等)。
基线方法对比Cho等人2021年提出的PiCIE方法,图片结果显示,STEGO的语义分割预测结果在没有忽略关键对象的同时,保留了局部细节特征。

STEGO是怎么做到在没有标记的情况下,为每个像素分配标签的呢?
STEGO原理和结构
STEGO使用2021年Caron等人提出的DINO模型作为特征提取器,图片显示了原图像(左图)中的标记的蓝色、红色和绿色点是如何进行像素特征关联学习的。

蓝色为天空,绿色表示草坪、红色表示骑摩托的人
STEGO的核心是一种新的损失函数,它鼓励特征形成紧凑的簇,同时保留它们在整个图像语料库中的关系。
使用下式中损失函数进行训练,以提取图像与自身、其K近邻(KNN)像素点和其他随机图像之间的特征关系,对应下图中的三个灰色部分。
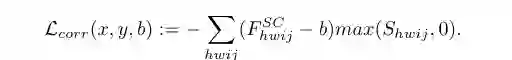
下图显示了STEGO结构。STEGO的训练网络由一个无需进行微调和预训练的网络构成,使用此结构通过全局平均池(GAP)提取全局图像特征。然后在特征空间构造每个图像的K近邻查找表。
这种Frozen Visual Backbone结构相比其他方法,训练耗时非常短,在一张NVIDIA V100 GPU卡上只需要不到2小时。
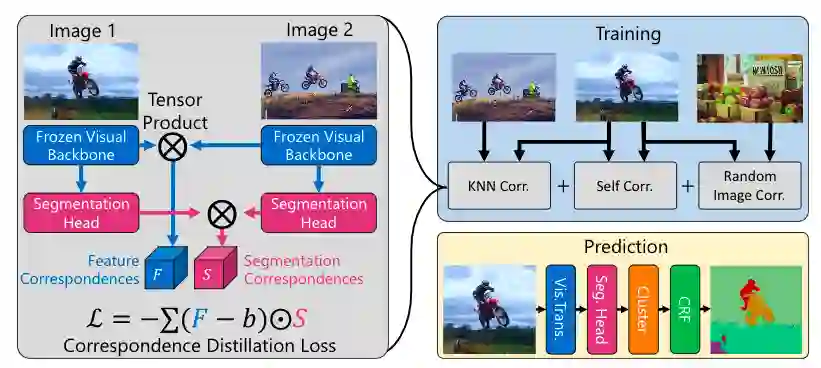
预测结构的最后一个组件是聚类和CRF细化步骤,STEGO的分割特征往往会形成清晰的聚类,使用MacQueen等人1967年提出的基于acosine距离的小批量K-均值算法来提取这些聚类簇,并根据STEGO的连续特征计算为形成的簇分配类别。聚类后,使用CRF对这些标签进行细化,以进一步提高其空间分辨率。
STEGO的整个损失函数如下:
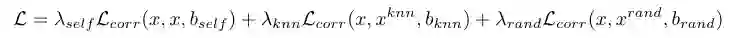
实验结果
每个验证图像的大小为320×320像素,使用均交并比「mIoU」作为评测指标。
左图表示在Cityscapes数据集上标签图片与STEGO语义分割结果对比,右图表示在CocoStuff 数据集上预测标签和真实标签的混淆矩阵。
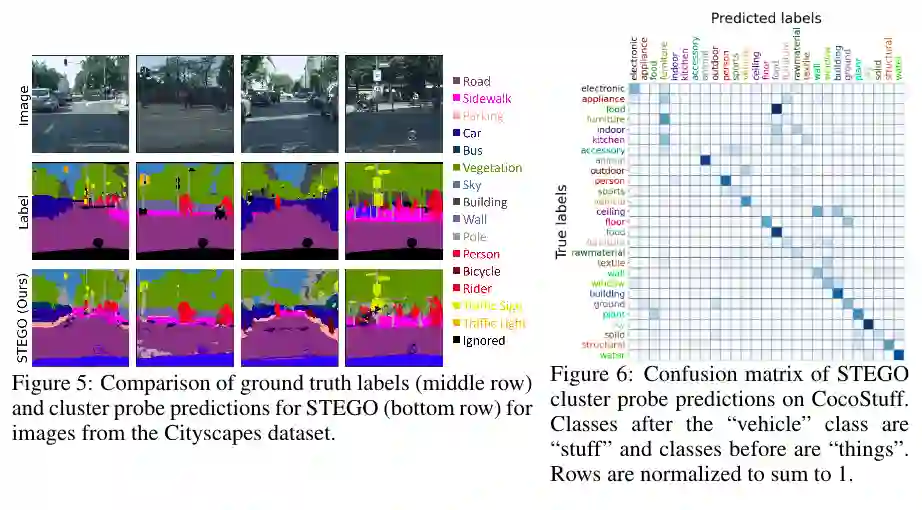
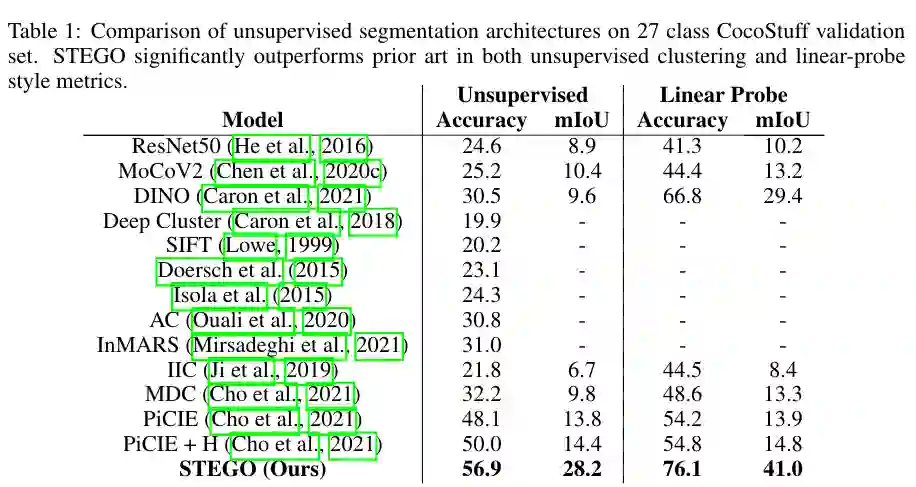
在CocoStuff数据集上,无监督语义分割任务对比结果显示,STEGO明显优于之前的方法。
在Cityscapes(27个类别)的预测结果显示。STEGO在accuracy和mIoU的所有基线上都有显著提高。
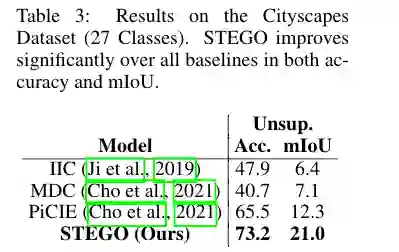
实验结果表明STEGO在CocoStuff(+14mIoU)和Cityscapes(+9mIoU)数据集上的精细语义分割任务上都取得了良好的表现。
尽管有了改进,STEGO仍然面临某些挑战:
比如,在CocoStuff数据集中,香蕉和鸡翅是「食品」,而玉米糁和意大利面是「食材」。但是这两样东西在STEGO眼里并没有什么区别。
甚至,如果你把一个香蕉放在了电话听筒上,这个听筒都可能会被标注为「食品」。
作者介绍
作者介绍
论文二作Zhoutong Zhang现在是MIT的在读博士生,本科就读于清华大学电子工程专业,师从刘烨斌教授。

此前,曾在2021年以一作身份在SIGGRAPH上发表论文「Consistent Depth of Moving Objects in Video」。

参考资料:
https://news.mit.edu/2022/new-unsupervised-computer-vision-algorithm-stego-0421




