无监督计算机视觉的最新技术——麻省理工学院 CSAIL 科学家创建了一种算法来解决计算机视觉中最困难的任务之一:为世界上的每个像素分配一个标签,无需人工监督。

标记数据可能是一件麻烦事。它是计算机视觉模型的主要来源;没有它,他们就很难识别物体、人以及其他重要的图像特征。然而,仅仅制作一个小时的标记数据就可能需要人类800小时的时间。随着机器能够更好地感知周围环境并与之互动,我们对世界的高保真理解也在不断发展。但是他们需要更多的帮助。
麻省理工学院计算机科学与人工智能实验室(CSAIL)、微软(Microsoft)和康奈尔大学(Cornell University)的科学家们试图通过创建“STEGO”来解决这个困扰视觉模型的问题。“STEGO”是一种算法,可以在没有任何人类标签的情况下,联合发现和分割物体,直到像素。
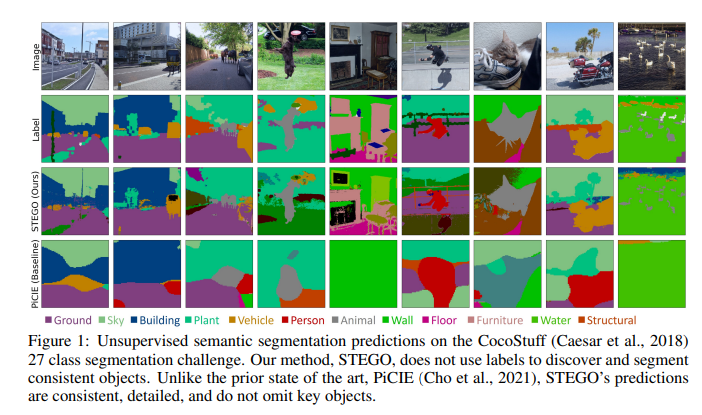
STEGO 学习了一种叫做“语义分割”的技术——为图像中的每个像素分配标签。语义分割是当今计算机视觉系统的一项重要技能,因为图像可能会被物体弄得杂乱无章。更具挑战性的是这些对象并不总是适合文字框。相对于植被、天空和土豆泥等“东西”,算法往往更适用于人和汽车等离散的“事物”。以前的系统可能只是将狗在公园里玩耍的微妙场景仅仅视为一只狗,但通过为图像的每个像素分配一个标签,STEGO 可以将图像分解为:狗、天空、草和它的主人。
为世界上的每一个像素分配一个标签是令人振奋的——尤其是在没有任何人类反馈的情况下。今天的大多数算法都从大量标记数据中获取知识,而这些数据可能需要花费大量的人力来获取。想象一下标记 100,000 张图像的每个像素的兴奋!为了在没有人类帮助的情况下发现这些对象,STEGO 会寻找出现在整个数据集中的相似对象。然后,它将这些相似的对象关联在一起,以在它学习的所有图像中构建一致的世界视图。
“看世界”
机器能够“看见”对于自动驾驶汽车和医学诊断的预测建模等一系列新兴技术至关重要。由于STEGO可以在没有标签的情况下学习,它可以检测到许多不同领域的物体,甚至是那些人类尚未完全理解的领域。
“如果你在看肿瘤扫描、行星表面或高分辨率的生物图像,没有专业知识,很难知道要寻找什么对象。在新兴领域,有时甚至人类专家也不知道正确的对象应该是什么,”麻省理工学院电子工程和计算机科学博士生、麻省理工学院CSAIL研究附属机构、微软软件工程师、关于STEGO的新论文主要作者Mark Hamilton说。“在这种情况下,你想设计一种在科学边界操作的方法,你不能依靠人类在机器之前解决问题。”
STEGO 在一系列视觉领域进行了测试,包括一般图像、驾驶图像和高空航拍照片。在每个领域,STEGO 都能够识别和分割与人类判断密切相关的相关对象。STEGO 最多样化的基准是 COCO-Stuff 数据集,它由来自世界各地的不同图像组成,从室内场景到运动的人,再到树木和奶牛。在大多数情况下,以前最先进的系统可以捕捉场景的低分辨率要点,但在精细细节上却很困难:一个人是一个斑点,一辆摩托车被捕捉到是一个人,它不能识别任何鹅。在同样的场景中,STEGO将之前系统的性能提高了一倍,并发现了动物、建筑、人、家具等概念。
STEGO 不仅在 COCO-Stuff 基准测试中将先前系统的性能提高了一倍,而且在其他视觉领域也取得了类似的飞跃。当应用于无人驾驶汽车数据集时,STEGO 以比以前的系统更高的分辨率和粒度成功地分割出道路、人和路牌。在来自太空的图像上,该系统将地球表面的每一平方英尺分解为道路、植被和建筑物。
连接像素
STEGO是“基于能量的图优化的自我监督Transformer”的缩写,它建立在DINO算法之上,该算法通过ImageNet数据库中的1400万张图像理解世界。STEGO 通过一个学习过程来完善 DINO 骨干,该过程模仿我们自己将世界的各个部分拼接在一起的方式。
例如,您可能会考虑两张狗在公园里散步的图像。尽管它们是不同的狗,拥有不同的主人,在不同的公园,STEGO 可以(没有人类)分辨出每个场景的对象是如何相互关联的。作者甚至探究了 STEGO 的思维,看图像中每个棕色毛茸茸的小东西有什么相似之处,以及与草和人等其他共享对象的相似之处。通过跨图像连接对象,STEGO 构建了一致的单词视图。
“我们的想法是,这些类型的算法可以在很大程度上以自动化的方式找到一致的分组,因此我们不必自己这样做,”Mark Hamilton说。“理解复杂的视觉数据集(如生物图像)可能需要数年时间,但如果我们能够避免花费 1,000 小时梳理数据并对其进行标记,我们就可以找到并发现我们可能错过的新信息。我们希望这将帮助我们以更具有经验基础的方式理解视觉词。”
展望未来
尽管进行了改进,STEGO 仍然面临着一定的挑战。一是标签可以是任意的。例如,COCO-Stuff 数据集的标签区分香蕉和鸡翅等“食物”,粗粒和意大利面等“食物”。STEGO 并没有看到太大的区别。在其他情况下,STEGO 被奇怪的图像弄糊涂了——比如一个香蕉坐在电话接收器上——接收器被标记为“食品”,而不是“原材料”。
对于未来的工作,他们计划探索为 STEGO 提供更多的灵活性,而不仅仅是将像素标记为固定数量的类别,因为现实世界中的事物有时可能同时是多个事物(例如“食物”、“植物”和“水果”)。作者希望这将为算法提供不确定性、权衡和更抽象思维的空间。
“在制作用于理解潜在复杂数据集的通用工具时,我们希望这种算法能够自动化从图像中发现对象的科学过程。在许多不同的领域中,人工标记的成本非常高,或者人类根本不知道具体的结构,例如在某些生物和天体物理学领域。我们希望未来的工作能够应用于非常广泛的数据集。由于您不需要任何人工标签,我们现在可以开始更广泛地应用 ML 工具,”Hamilton 说。
“STEGO 简单、优雅且非常有效。我认为无监督分割是图像理解进步的基准,也是一个非常困难的问题。通过采用Transformer架构,研究界在无监督图像理解方面取得了巨大进展,”计算机视觉和机器学习教授、牛津大学工程科学系视觉几何小组的联合负责人 Andrea Vedaldi 说。 “这项研究提供了无监督分割这一进展的最直接和最有效的证明。”
Hamilton与麻省理工学院 CSAIL 博士生Zhoutong Zhang、康奈尔大学助理教授 Bharath Hariharan、康奈尔理工学院副教授 Noah Snavely 和麻省理工学院教授 William T. Freeman 共同撰写了这篇论文。他们将在 2022 年国际学习表征会议 (ICLR) 上展示该论文。
论文一览
通过提取特征对应的无监督语义分割(Unsupervised semantic segmentation by distilling feature correspondences)