ICLR 2022 | 从几何视角来看无监督强化学习

©作者 | 我是谁啊

文章主旨
本文主要针对一种无监督(不依赖 reward)的强化学习预训练方法——无监督技巧发现(unsupservised skill discovery)的算法最优性质进行了讨论。作者证明了通过最大化互信息(mutual information)方式的 skill discovery 无法保证对任何下游奖励函数都是最优的。同时在,作者证明了在某种特定的下游任务 adaption 方式下(在后续的章节中详细讲解),通过预训练得到的 policy 能够最大化不同的 reward 下游任务中的最差情况(worst case)下的表现。

论文标题:
The Information Geometry of Unsupervised Reinforcement Learning
https://arxiv.org/pdf/2110.02719.pdf

符号定义
定义某 MDP 下依策略 ,折扣状态占有率(state occupancy)为 ,
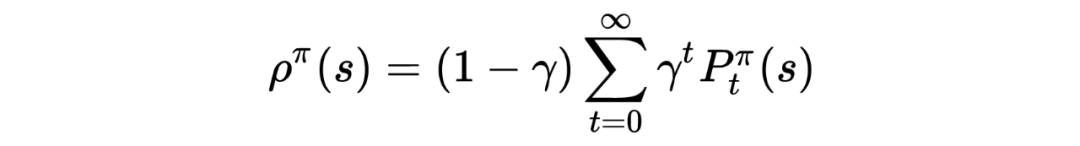
其中, 为依策略 进行采样, 时刻处于状态 的概率。据此重新定义强化学习的优化目标:
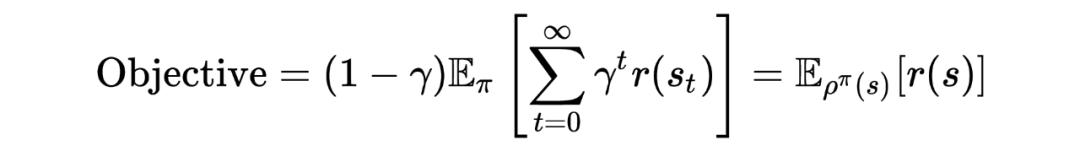
其中这里使用了仅与 state 有关的奖励函数 。

无监督的技巧学习
此前的无监督技巧学习试图学习策略 ,除了状态 s 以外,策略同时与额外的输入变量 条件相关。其中 z 通过一个分布来进行生成 (这个分布同样是训练得到的)。在此前的一些工作中,通过最大化 与 之间的互信息进行优化:
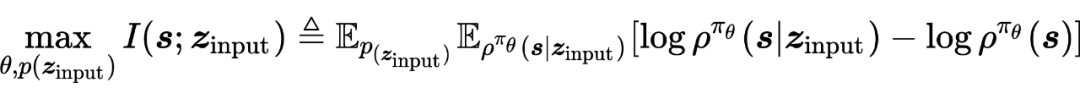
上式中需要同是对 (对应参数 )以及 进行优化。作者对问题进行简化,将两者进行整合,定义: ,据此定义,上式优化问题可以被表示为:
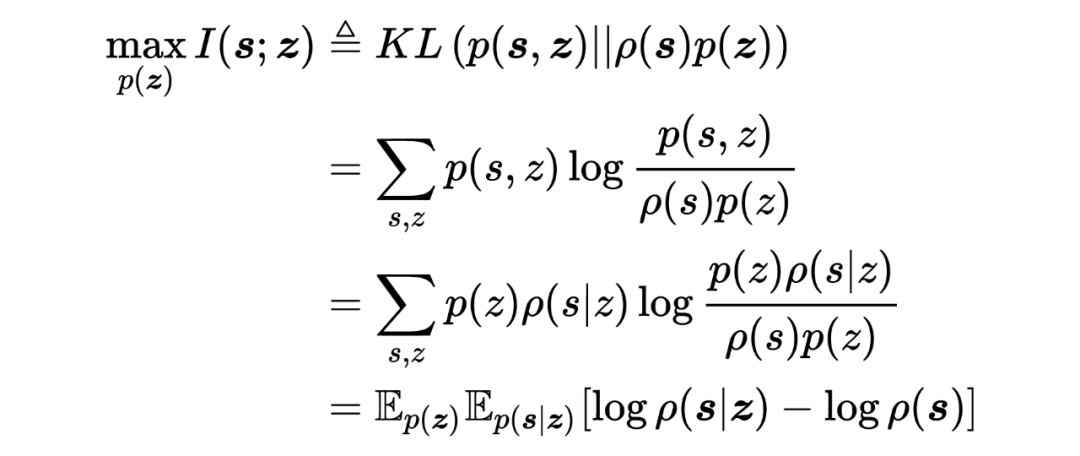

Theorem 4.1证明(本文的核心定理)
定理如下:
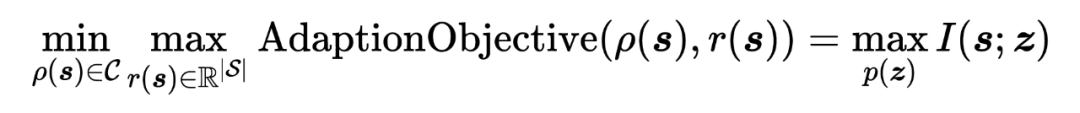
其中,
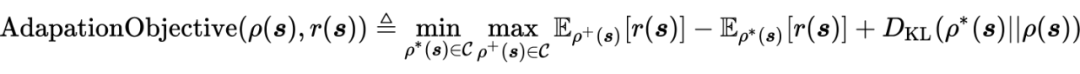
公式中 代表初始化数据分布(即 pre-train 后得到的分布,初始化是相对于下游任务来说), 为在下游任务上(对于奖励函数 )进行 adaption(finetune)得到的 state 分布; 下游任务 上的最优 state 分布。
首先对 AdapationObjective 进行理解:
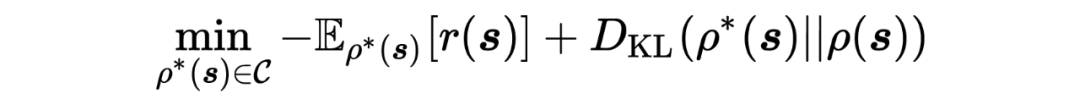
为 的优化目标,即策略在下游任务上的 adaption 过程,其中第一项以策略在下游任务 为优化目标,第二项为 与初始化策略分布 分布之间的 KL 散度,KL 散度越小,两者之间差异性越小,策略能够越容易的 general 到下游任务(作者称此项为 information cost)。可以看到 与 的唯一差别是: 为 下的最优 state 分布,仅仅以策略最优性作为优化目标,而 的优化过程需要同时考虑策略最优性以及 adaption 过程的 information cost。
Proof:
假定下游任务 以及初始化分布 已经给定,首先针对 进行优化:
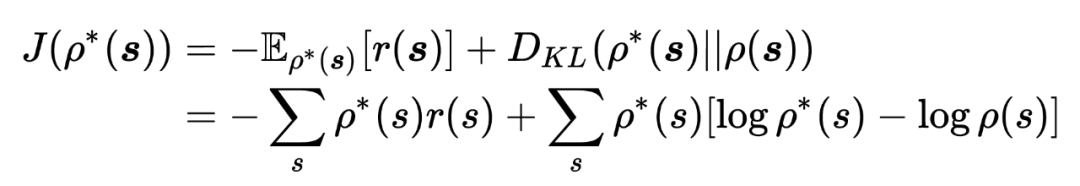
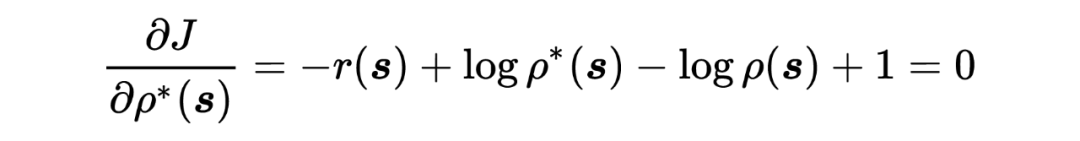
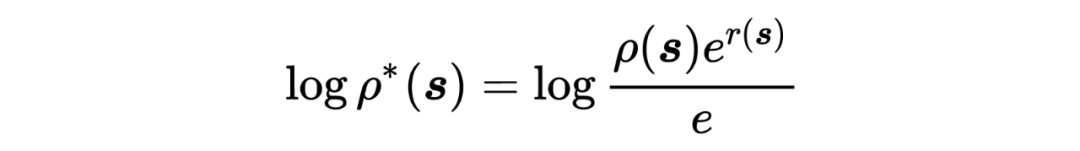
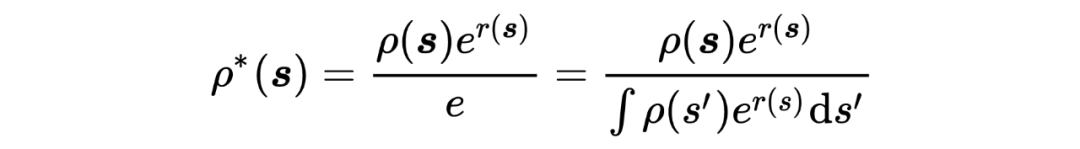
将 带入 AdaptionObjective 中,有,
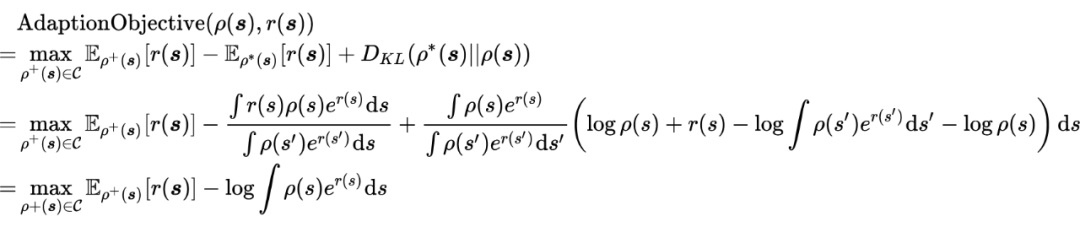
因此,问题的原始优化目标可以被表示为:
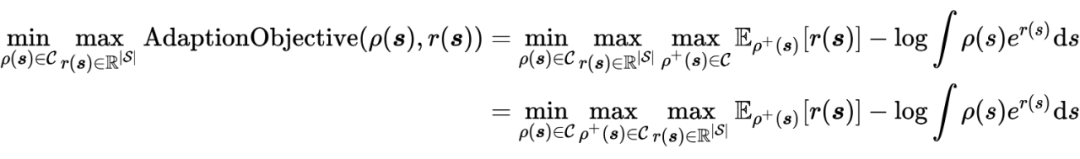
对 进行优化,
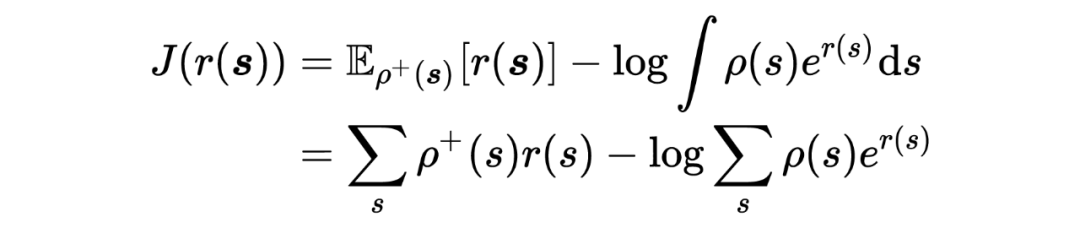
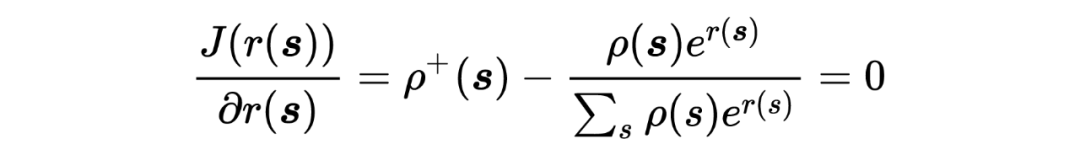
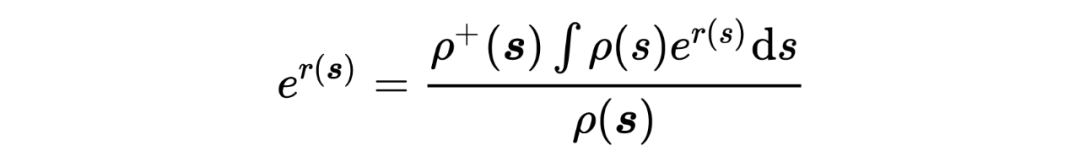
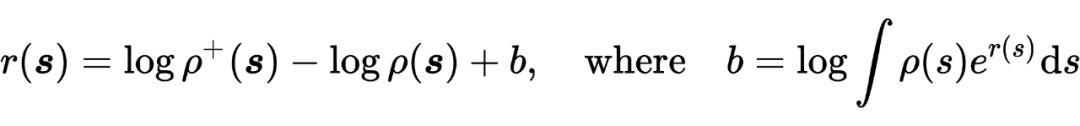
将 进一步带入,得
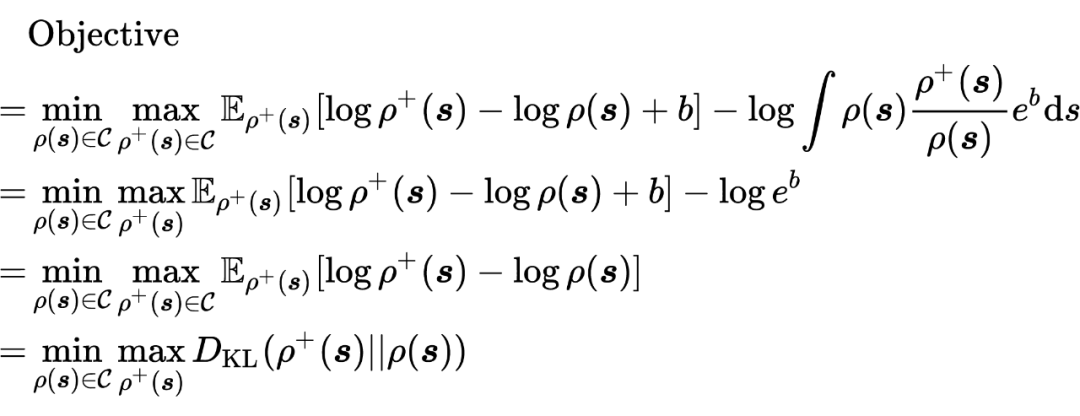
根据 Lemma 6,5,在 给定的情况下,有:
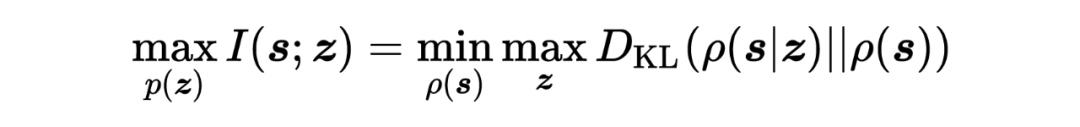
将优化变量由 替换为 ,在 给定的情况下(事实上根据作者的定义, ,那么 仅仅与环境转移有关)。
至此,Theorem 4.1得证。

Skill Learning的几何解释
5.1 哪些策略(以及策略对应的state分布)是可达的?

作者以状态空间 为例,对问题进行可视化分析。状态的 state-occupancy 需要满足:
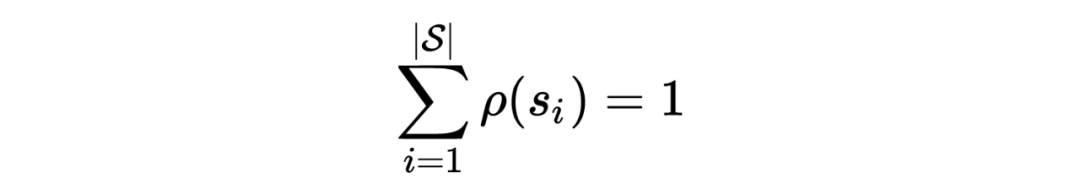
也就是所有可能的 state-occupancy 都分布在此超平面上。
Proposition 1. 给定一系列可行的 state marginals(state-occupancy 分布,即图中黄色点),那么这些可达的 state marginals 的所有凸组合一定也是可达的,这些可能的所有凸组合构成了整个可行空间(图中橘黄色多面体)。
该可达区域实际上构成了一个凸集。
5.2 哪些策略(以及对应的state分布)是最优的?
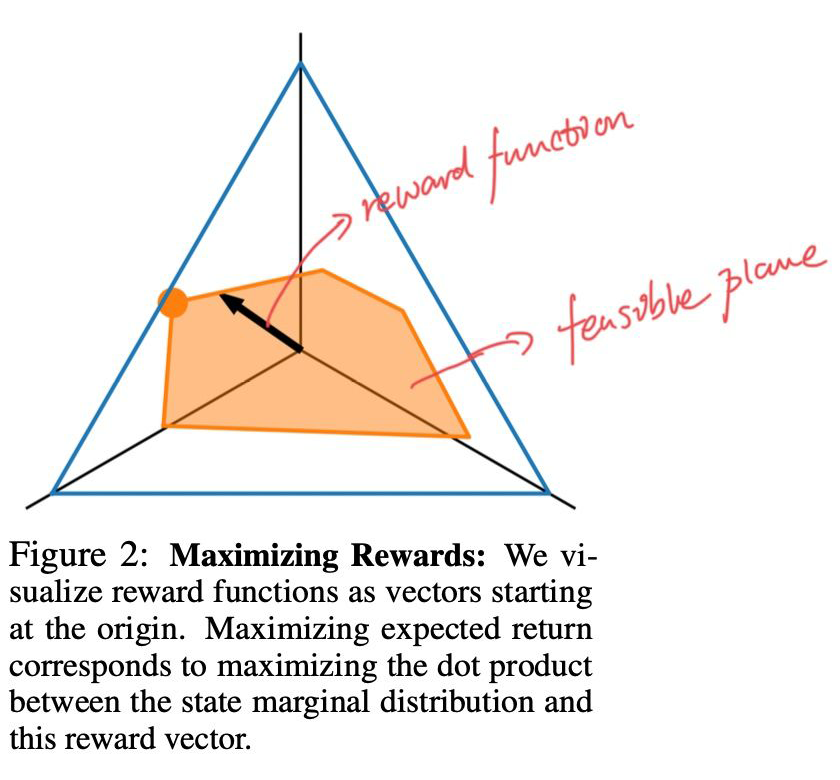
同样以状态空间 为例,假定状态分布为 ,并且 。作者将奖励函数 可视化为三位空间中的某个向量 ,那么累计奖赏可以被表示为:
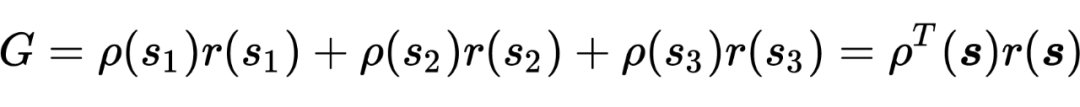
即累计奖赏可以被表示为 reward 函数与状态分布向量的内积。
Fact 1. 对于每个仅与状态有关(state-dependent)的奖励函数 ,对于策略可达区域内的所有策略,能够使在 下的累计奖赏 G 最大的策略一定在可达区域多面体的顶点上。
proposition 2 可以由最大值原理(maximum principle)得到,这里不进行过多介绍。
Fact 2. 对于状态可达多面体的每一个顶点,存在一个特定的奖励函数 ,使得该顶点对应的策略为 下的最优策略。
Definition 5.1:顶点发现问题(Vertex Discovery Problem):给定某个受控 MDP 过程(没有 reward 的 MDP 过程),寻找一个最小策略集合,使得状态可达多面体的每个顶点至少有一个策略与之对应。
5.3 基于Mutual information的Skill learning学得的策略是如何在策略可达多面体内分布的?
回顾 Skill learning 的原始优化问题,即最大化互信息 ,
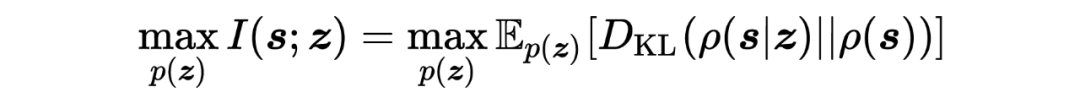
其中, 为 下的平均状态分布,
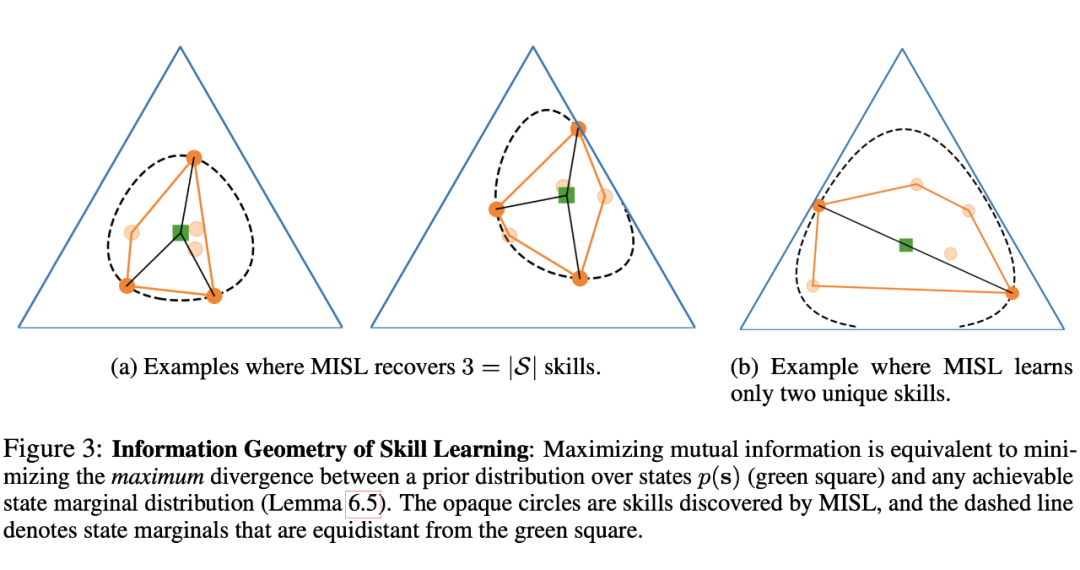
对于上述优化问题进行优化时,最大化互信息会驱使 skill learning 学得的策略的状态分布 远离平均状态分布 (因为最大化 KL 散度会放大两个不同分布之间的差异性)。因此,当 skill learning 达到最优时,对于距离平均分布 的最远的策略赋予一个比较大的概率,而对于其余策略(与 的距离小于最远距离的策略),则会赋予概率为 0。
作者在 Figure 3(下图)进行了举例分析,其中图中绿色点代表状态的平均分布 ,橙色的点代表算法学得的 skill,图中的虚线圆圈代表了 与策略可达区域的最大边界线(可以理解为策略可达多面体的外切球)。我们以最左边的图进行分析,图中的策略可达多面体有 3 个节点分布最大边界上,也就是 skill learning 共学得了三个不同的 skill,其概率和为 1(0.28 + 0.28 + 0.44=1),因此,作者想表达的意思是,只有分布在最大边界上的策略才能被习得。
作者对此现象在 lemma 6.2 进行了公示化表述:
5.4 Skill learning最多能够习得多少个不同的skill?
为了回答这个问题,作者提出如下假设:
Assumption 1:假定 中任意取出 个节点构成的集合,都不关于 KL 散度共圆。也就是不存在某个 使得集合中所有节点距离 的距离相等。
存在于 维空间中,共有 个自由度(因为和为1的约束)。当不断习得 skill 时,需满足与 的距离为 ,其中 作为变量提供了一个额外的自由度。因此,最多添加 个约束, 便可以完全确定,继续增加额外的 skill 会让该问题变成 ill-defined。因此,最多同时习得 个 skill。

独家定制炼丹中/Fine-Tuning
超超超超超大鼠标垫
限量 200 份
扫码回复「鼠标垫」
立即免费参与领取
👇👇👇

更多阅读




#投 稿 通 道#
让你的文字被更多人看到
如何才能让更多的优质内容以更短路径到达读者群体,缩短读者寻找优质内容的成本呢?答案就是:你不认识的人。
总有一些你不认识的人,知道你想知道的东西。PaperWeekly 或许可以成为一座桥梁,促使不同背景、不同方向的学者和学术灵感相互碰撞,迸发出更多的可能性。
PaperWeekly 鼓励高校实验室或个人,在我们的平台上分享各类优质内容,可以是最新论文解读,也可以是学术热点剖析、科研心得或竞赛经验讲解等。我们的目的只有一个,让知识真正流动起来。
📝 稿件基本要求:
• 文章确系个人原创作品,未曾在公开渠道发表,如为其他平台已发表或待发表的文章,请明确标注
• 稿件建议以 markdown 格式撰写,文中配图以附件形式发送,要求图片清晰,无版权问题
• PaperWeekly 尊重原作者署名权,并将为每篇被采纳的原创首发稿件,提供业内具有竞争力稿酬,具体依据文章阅读量和文章质量阶梯制结算
📬 投稿通道:
• 投稿邮箱:hr@paperweekly.site
• 来稿请备注即时联系方式(微信),以便我们在稿件选用的第一时间联系作者
• 您也可以直接添加小编微信(pwbot02)快速投稿,备注:姓名-投稿

△长按添加PaperWeekly小编
🔍
现在,在「知乎」也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」订阅我们的专栏吧





