每周论文清单:对话系统综述,全新中文分词框架,视频生成,文字识别

在碎片化阅读充斥眼球的时代,越来越少的人会去关注每篇论文背后的探索和思考。
在这个栏目里,你会快速 get 每篇精选论文的亮点和痛点,时刻紧跟 AI 前沿成果。
点击本文底部的「阅读原文」即刻加入社区,查看更多最新论文推荐。
[ 自然语言处理 ]

@jueliangguke 推荐
#Convolutional Neural Network
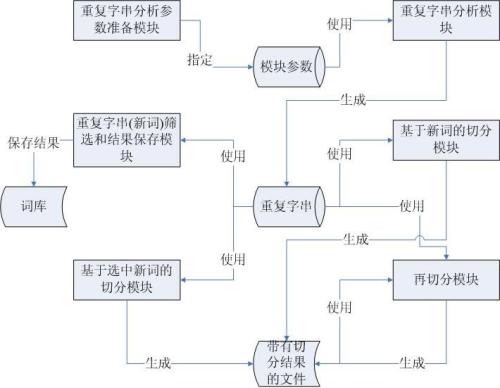
本文提出了一个全新的中文分词框架,使用深度卷积网络在多个数据集上达到了 state-of-the-art。

@paperweekly 推荐
#Dialog Systems
本文来自京东数据科学团队,这是一篇非常全面的对话系统综述,引用了 100+ 篇相关论文,并对论文进行了分类。

How to Make Context More Useful?
@zhangjianhai 推荐
#ContextQA
在自然语言对话领域,论文首先对比了目前几种流行的 Context-aware 模型,包括 Non-hierarchical 模型(将 context 与 query 作为一个序列建模)以及 Hierarchical 模型(将 context 与 query 分别建模生成向量表示,在此基础上采用不同的方式进行整合,包括 sum,concat,sequential integration 等)。
最后,论文提出了一种 Weighted Sequential Integration 的上下文整合方式,对不同的上下文赋予不同的权重。对 ContextQA 相关工作具有一定借鉴意义。

@cfjmonkey 推荐
#Text Style Transfer
该文实现了基于给定属性的文本风格的转换。属性包括标题、作者和类别。不同类别的文章用词分布不同,同一作者的写作风格是一致的,标题个人理解可以看做关键词定基调,相比关键词语料更丰富。
实验在新闻、影评和歌词三大类文本中进行。 该工作作者来自今日头条,eBay 和清华。

@zhangjun 推荐
#Question Answering
来自百度的 QA 系统,本文已被 EMNLP 2017 接收。

@YiqiYan 推荐
#Semantic Segmentation
本文提出了一种新的概念 — Panoptic Segmentation,它是对 instance sengmentation 和 semantic segmentation 的统一。
例如一副街景:instance sengmentation 只分割出一些实例,但是要区分同一类别的个体(分割出车 a,车 b,车 c);semantic segmentation 是把每一个像素分入一个类别,但是不区分个体;Panoptic Segmentation 既要完成 semantic segmentation 的任务,又要区分同一个类别的不同个体。

@Synced 推荐
#Adversarial Training
该论文提出了一种在现实世界中创建通用、鲁棒、针对性的对抗图像 patch 的方法。该 patch 是通用的,因为它们可用于攻击任何场景;是鲁棒的,因为它们在多种图像变换中都是有效的;是有针对性的,因为它们可以令分类器输出任意目标类。
这些对抗样本可以被打印出来,添加到任意的场景、照片,并展示给图像分类器;即使 patch 很小,也能导致分类器忽略场景中的其它物体,输出选定的目标类。

@Aidon 推荐
#Video Captioning
文章指出现有的 captioning 模型都是用交叉熵损失(XE: cross-entropy loss)训练的,而实际评估的时候用的是其他指标比如 BLEU,METEOR 等。
这里对应的是第一个问题:objective mismatch,很自然地会想到可以直接对评价指标进行优化。第二个问题是 exposure bias,即训练集和测试集上 captions 的分布很有可能是不一样的。虽然强化学习有被用于解决第一个问题,但它的计算开销大,并且在每一步都有指定 baseline reward 才能保证模型的收敛。
针对以上问题,文章提出基于一致性的序列训练来做 video captioning。首先从理论上解释了 XE training 和 RL training 之间的联系,即后者是前者的一个加权形式;然后引入一个简单的 WXE pre-training 来近似 RL training,这样就解决了前面提到的第一个问题。
更进一步地,文章提出用 full REINFORCE 来进行 fine-tune,利用 gt captions 的 consensus score 作为 baseline reward,这样就可以避免 XE training 带来的第二个问题。

@zhangjun 推荐
#Video Generation
本文是 MILA 最近的一篇工作,实现了一个根据 text 合成唇同步视频的架构,并以奥巴马做了一个 demo,命名为 ObamaNet。
Demo 地址:http://ritheshkumar.com/obamanet/

@chenhong 推荐
#Text Detection
论文中 2D 图像的任意方向的字符编码为 4 个方向的 4 个特征序列表示:左→右,右→左,上→下,下→上(每个方向的特征序列长度相同)。
论文提出一个鲁棒性算法,基于 AON 识别规则和不规则自然场景字符。基于 top-down,无需检测字符,直接预测原始图像整个字符,end-to-end 实现。
本文由 AI 学术社区 PaperWeekly 精选推荐,社区目前已覆盖自然语言处理、计算机视觉、人工智能、机器学习、数据挖掘和信息检索等研究方向,点击「阅读原文」即刻加入社区!
我是彩蛋
解锁新功能:热门职位推荐!
PaperWeekly小程序升级啦
今日arXiv√猜你喜欢√热门职位√
找全职找实习都不是问题
解锁方式
1. 识别下方二维码打开小程序
2. 用PaperWeekly社区账号进行登陆
3. 登陆后即可解锁所有功能
职位发布
请添加小助手微信(pwbot01)进行咨询
长按识别二维码,使用小程序
*点击阅读原文即可注册

关于PaperWeekly
PaperWeekly 是一个推荐、解读、讨论、报道人工智能前沿论文成果的学术平台。如果你研究或从事 AI 领域,欢迎在公众号后台点击「交流群」,小助手将把你带入 PaperWeekly 的交流群里。