COLING 2018 最佳论文解读:序列标注经典模型复现


在碎片化阅读充斥眼球的时代,越来越少的人会去关注每篇论文背后的探索和思考。
在这个栏目里,你会快速 get 每篇精选论文的亮点和痛点,时刻紧跟 AI 前沿成果。
点击本文底部的「阅读原文」即刻加入社区,查看更多最新论文推荐。
本期推荐的论文笔记来自 PaperWeekly 社区用户 @handsome。这篇论文是 COLING 2018 的 Most reproducible Paper。作者用 PyTorch 实现了一个统一的序列标注框架,重现了 CoNLL 2003 English NER、CoNLL 2000 Chunking 和 PTB POS tagging 这三个数据集上不同模型的的表现。值得一提的是,基于这个统一的框架,作者对一些已有工作的一些不一致的结论进行了反驳,提出了一些新的看法。对于实践者而言,这篇论文还是很有借鉴意义的。
如果你对本文工作感兴趣,点击底部阅读原文即可查看原论文。
关于作者:梁帅龙,新加坡科技设计大学博士生,研究方向为自然语言处理。
■ 论文 | Design Challenges and Misconceptions in Neural Sequence Labeling
■ 链接 | https://www.paperweekly.site/papers/2061
■ 源码 | https://github.com/jiesutd/NCRFpp
引言
这篇论文是 COLING 2018 的 Best Paper 之一 “Most Reproducible Paper”,论文基于的 PyTorch 代码框架 NCRF++ 也收录于 ACL 2018 的 Demo Paper。
作者用一个统一的序列标注框架实现了不同模型架构在 NER, Chunking, POS Tagging 数据集上的表现,并对已有工作的一些不一致的结论进行了检验,发现了新的结论。代码在 Github 上已经开源,使用文档也非常详尽,做序列标注的童鞋们又多了一把利器可以使用。
任务
CoNLL 2003 英文的命名实体识别 (NER)
CoNLL 2000 Chunking
PTB POS Tagging
模型
字符序列表示
在词的表示方面,本文摒弃了基于传统的特征的方法,直接使用词本身的信息进行编码。除了词向量以外,为了更好地对那些不常见的词编码,文章使用 LSTM 或者 CNN 对构成词语的字符进行编码。
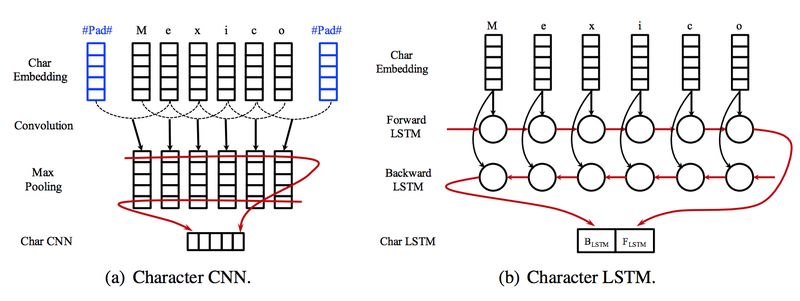
词序列表示
在整个句子级别,文章同样使用 LSTM / CNN 对构成句子的词语的表示进行上下文的编码。
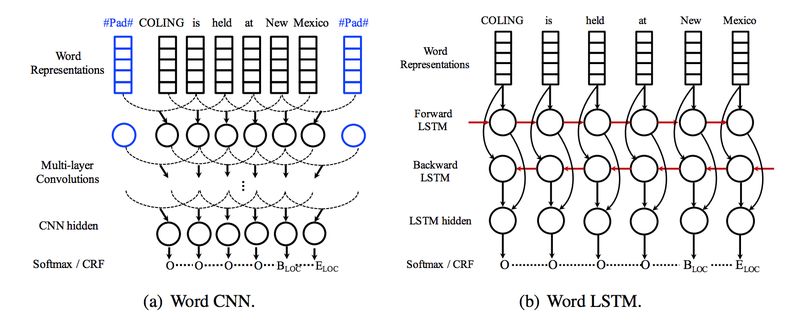
预测层
获取了每个词的上下文表示之后,在最后的预测层,文章使用了基于 Softmax 的和基于 CRF 的结构。和 Softmax 相比, CRF 往往更能有效地结合上下文的标签的依赖关系进行预测。
实验结果
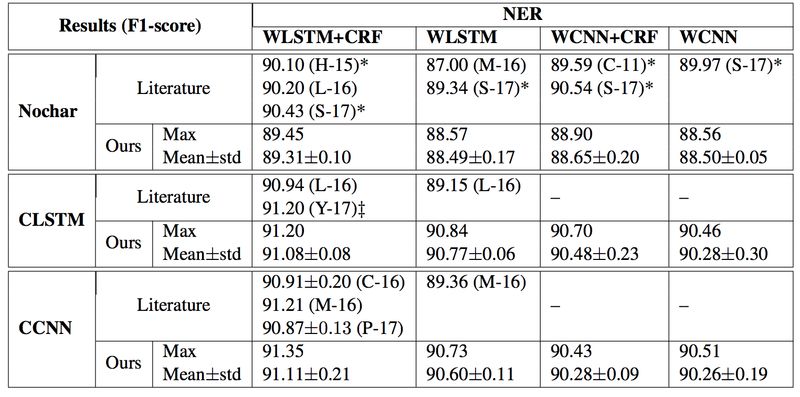
NER的实验结果
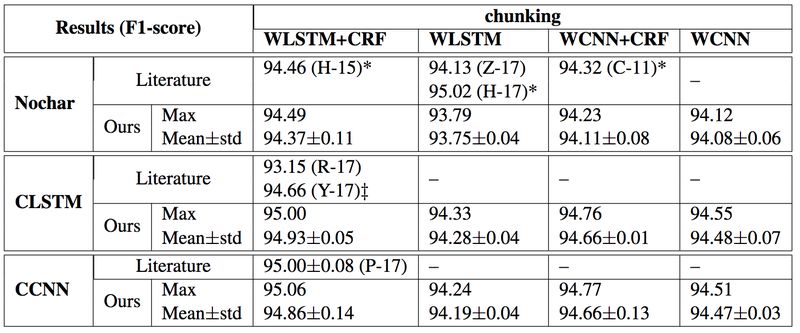
Chunking的实验结果
POS Tagging的实验结果
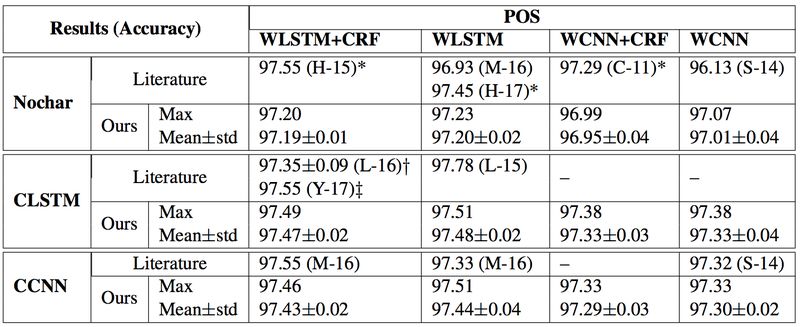
从以上结果来看,字符序列的表示方面,CNN 和 LSTM 的结果差别不大;词序列的表示方面,LSTM 的结果比 CNN 的稍好一些,说明全局信息的有效性;预测层方面,POS Tagging 任务的 CRF 和 Softmax 表现相当,但是 NER、Chunking 的 CRF 的结果要比 Softmax 好一些。相比 POS 的tags,BIE 标签之间的依赖关系可能更容易被 CRF 所建模。
其他
这篇文章也检验了预训练的词向量的不同(GloVe/SENNA),标注体系的不同 (BIO/BIOES),运行环境的不同(CPU/GPU),以及优化器的不同 (SGD/Adagrad/Adadelta/RMSProp/Adam)对结果的影响。感兴趣的同学可以查看论文原文。
最后
本文代码已开源,使用非常方便,也可以加自定义的 feature,几乎不用自己写代码就可以使用了。
本文由 AI 学术社区 PaperWeekly 精选推荐,社区目前已覆盖自然语言处理、计算机视觉、人工智能、机器学习、数据挖掘和信息检索等研究方向,点击「阅读原文」即刻加入社区!

点击标题查看更多论文解读:

AI活动推荐
中国人工智能大会 CCAI 2018
AI领域规格最高、规模最大
影响力最强的专业会议之一
热点话题√核心技术√科学问题√
活动时间
2018年7月28日-29日
中国·深圳
长按识别二维码,查看大会简介
▼

关于PaperWeekly
PaperWeekly 是一个推荐、解读、讨论、报道人工智能前沿论文成果的学术平台。如果你研究或从事 AI 领域,欢迎在公众号后台点击「交流群」,小助手将把你带入 PaperWeekly 的交流群里。

▽ 点击 | 阅读原文 | 查看原论文





