![]()
中国占总投稿近四成
2019年11月3日-7日,信息检索和数据挖掘的顶会 ACM CKIM 2019在北京召开,并于昨日颁发了本届会议的最佳论文奖,其中来自以色列本古里安大学的Noy Cohen等人获得最佳研究论文奖,阿里巴巴安全团队获得最佳应用论文奖、IBM获得最佳Demo奖。
本届会议是CIKM的第28届会议,由梅宏院士和Ramamohanarao Kotagiri担任大会荣誉主席,朱文武教授和陶大程教授担任大会主席。自1992年首次举办至今,CIKM也是第二次来到中国。
在本次会议中著名学者Steve Maybank、韩家炜、裴健和石建萍等人分别做了主题演讲,除了顶会必备的tutorial、workshop、oral以及post外,本次会议还举办了AnalytiCup 以及十余场工业演讲(Industrial Plenary Speech)。
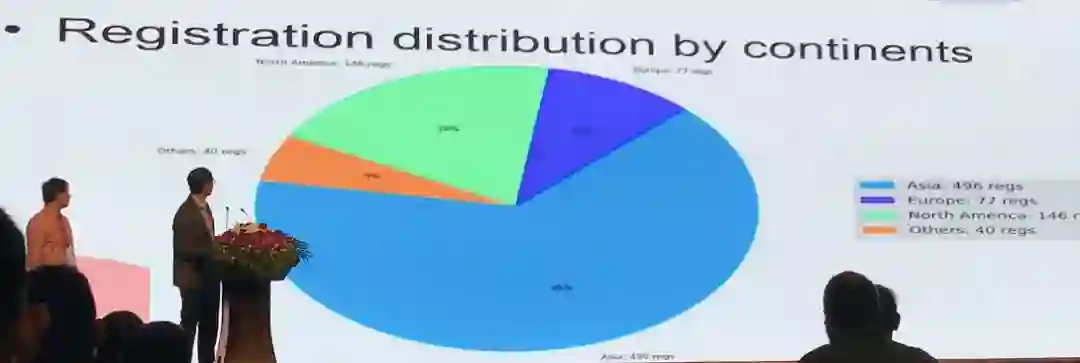
本次会议参会人数达700人次,由于地理原因,其中亚洲学者占绝大多数(约65%),而其中大部分又是中国学者(365人);其次是来自美国的学者(139人)。
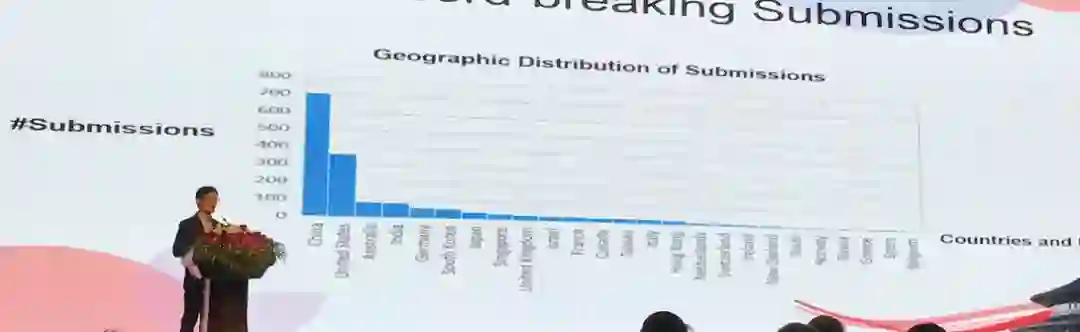
在论文投递方面,本届会议共有1720篇投稿,其中长论文1031篇,短论文471篇,应用研究论文174篇,Demo论文44篇。相较于去年会议论文显著增加,其中长论文也在历史中首次破千。
考虑论文投稿的地理分布,可以看出绝大部分论文是来自中国,占全部论文的四成;其次则来自美国,约有300多篇。
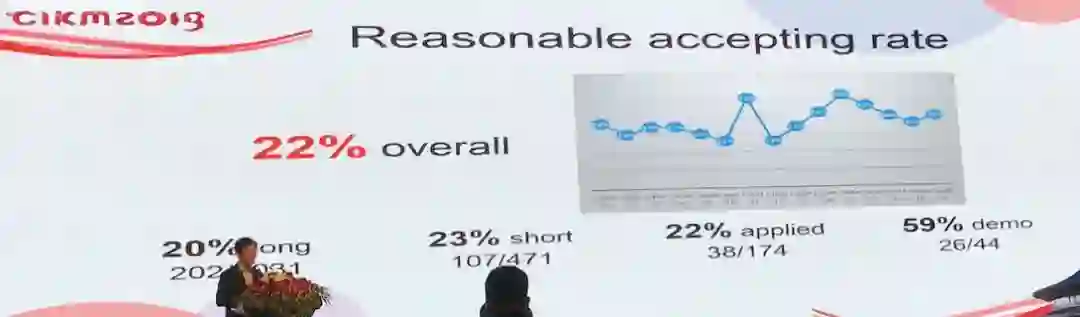
据大会PC主席介绍本次大会共有5194名审稿人,平均来说每篇文章都会有3.02个审稿人进行评审,这保证了会议论文接收的质量。
本次论文共接收202篇长论文(20%)、107篇短论文(23%)、38篇应用论文(22%)和26篇Demo论文(59%),平均接收率仅为22%。
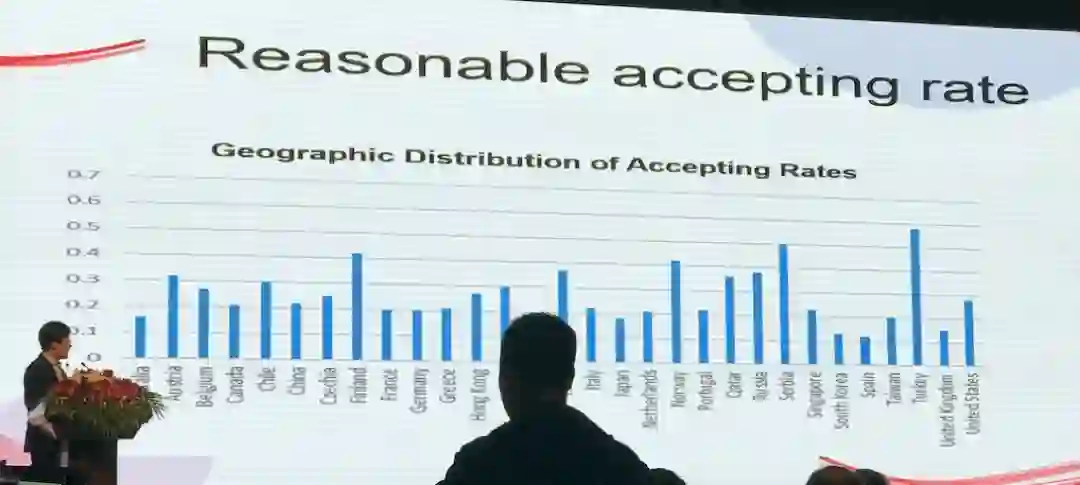
而按地域来考察论文的接收率,我们可以从下图中看出,来自中国的论文接收率为20%多一点,基本与平均接收率持平;而来自美国和澳大利亚的都在30%左右。这说明,在数据挖掘、信息检索和数据库这些领域来自中国的论文质量已经处于较高水平,但仍需提升。
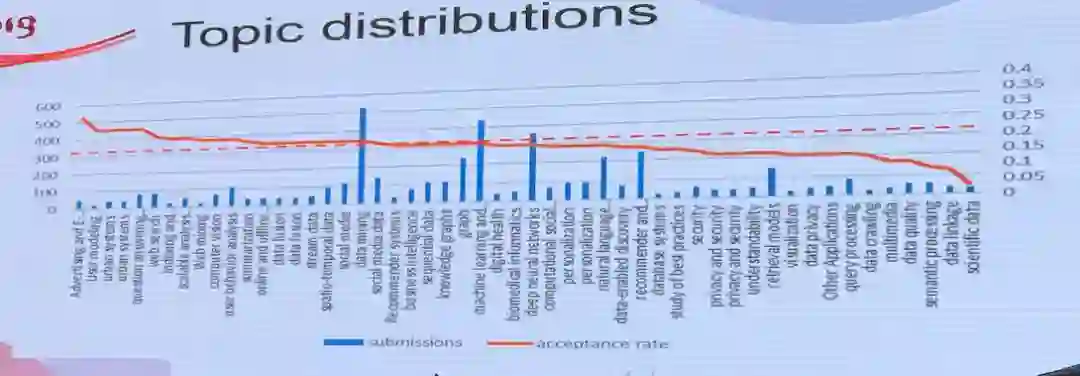
最有意思的是对论文话题分布的分析。话题论文的接收率(红线)一定程度上反映了审稿人的兴趣,若按接收率进行排序,可以看出广告和金融方向的论文更容易被接收;而对科学数据进行处理的文章更可能被拒绝掉。而另一方面,柱状图的高低则能够反映研究者的兴趣点,显然data mining、机器学习和深度神经网络仍然占据高位,而数据库、网页挖掘等则相对小众。
本届会议的主题是“AI for Future Life”,可见以深度学习等为主的人工智能技术在信息检索、数据挖掘领域已经起到了关键作用,成为研究的主流技术。大会联合主席陶大程表示:“我们认为未来人工智能会渗透到生活的各个方面,目前其主要深度学习,本届大会希望讨论深度学习和传统的统计学习在未来会有什么样的发展趋势。”
在本次会议中,图神经网络成为最大的热点,相关的tutorial及报告也往往成为参与人员趋之若鹜的重点内容。大会程序主席崔鹏告诉AI科技评论:“从第一天讲习班的情况来看,只要涉及到图,听的人都比较多。
现在大家对深度学习已经基本无感了,但图神经网络是一个值得研究方向,是深度学习的下一波研究。
”
陶大程认为之所以图神经网络受到关注,主要有三点:1、相对于深度学习,图的表征比较多;2、目前对于图的理论分析还比较欠缺,因此还有许多可以研究的地方;3、虽然图网络有各种各样的问题,但实际上在一些问题上已经取得了比其他网络较好的优势。
在11月5日的晚宴上颁发了最佳论文奖,共有三类、四个奖项:最佳研究论文奖、最佳研究论文(runner-up)奖、最佳应用论文奖与最佳 Demo奖。
最佳研究论文奖由以色列本古里安大学的Noy Cohen等人获得。
论文链接:
http://www.cikm2019.net/attachments/papers/p821-cohen-shapiraA.pdf
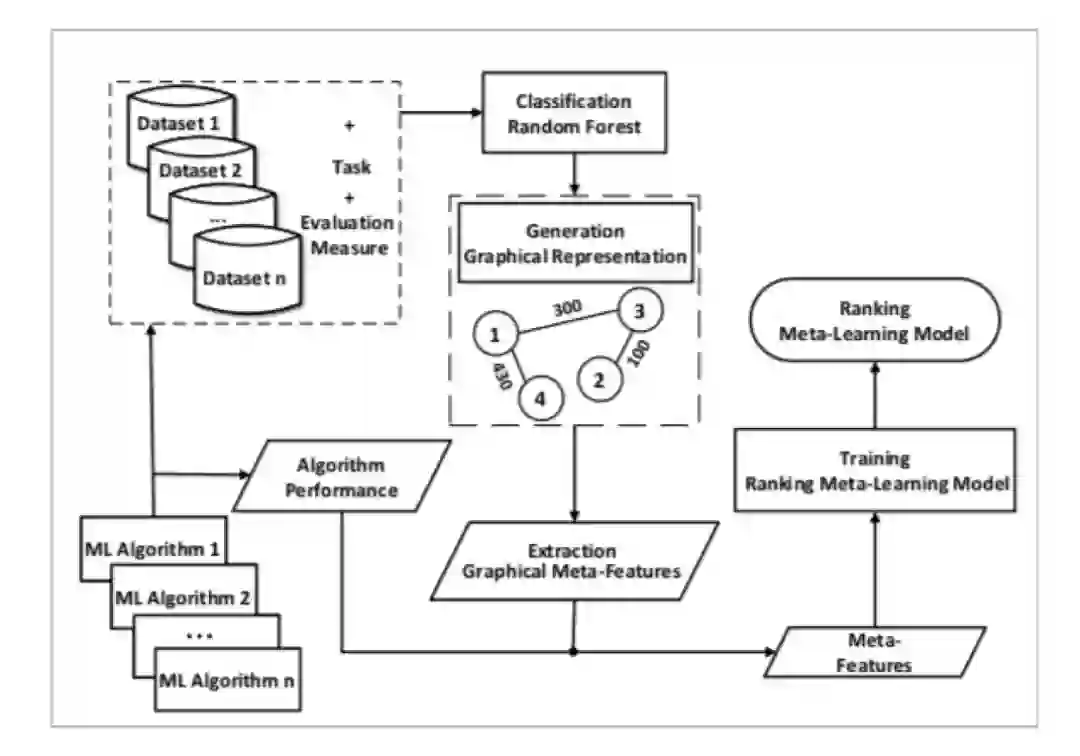
现在,机器学习算法已经被广泛地应用于许多领域,然而并非所有使用的人都是机器学习的专家,在自己的研究中如何找到最合适的算法成为一个函待解决的问题。作者认为对于这些非机器学习专家来说,一个正确的算法就是,在给定数据集、任务和评价方法的情况下得到最好的效果。基于此种考虑,Cohen等人提出了AutoGRD的模型,这是一种新型的用于算法推荐的元学习模型。如下图所示是AutoGRD训练的流程图:
![]() AutoGRD首先将数据集表示为图,并将它的隐式表示提取出来,然后将这个表示用来训练排序元模型,这个模型能够对未见过的数据集准确地推荐性能最佳的算法。
Cohen等人在250个数据集上进行了评估,结果证明AutoGRD对分类和回归任务都极为有效,比最新的元学习和贝叶斯方法都要好。
AutoGRD首先将数据集表示为图,并将它的隐式表示提取出来,然后将这个表示用来训练排序元模型,这个模型能够对未见过的数据集准确地推荐性能最佳的算法。
Cohen等人在250个数据集上进行了评估,结果证明AutoGRD对分类和回归任务都极为有效,比最新的元学习和贝叶斯方法都要好。
Runner-Up奖由北大、微软和阿里巴巴的研究人员共同获得,其中第一作者Qingqing Long来自北京大学。
论文链接:http://www.cikm2019.net/attachments/papers/p409-longA.pdf
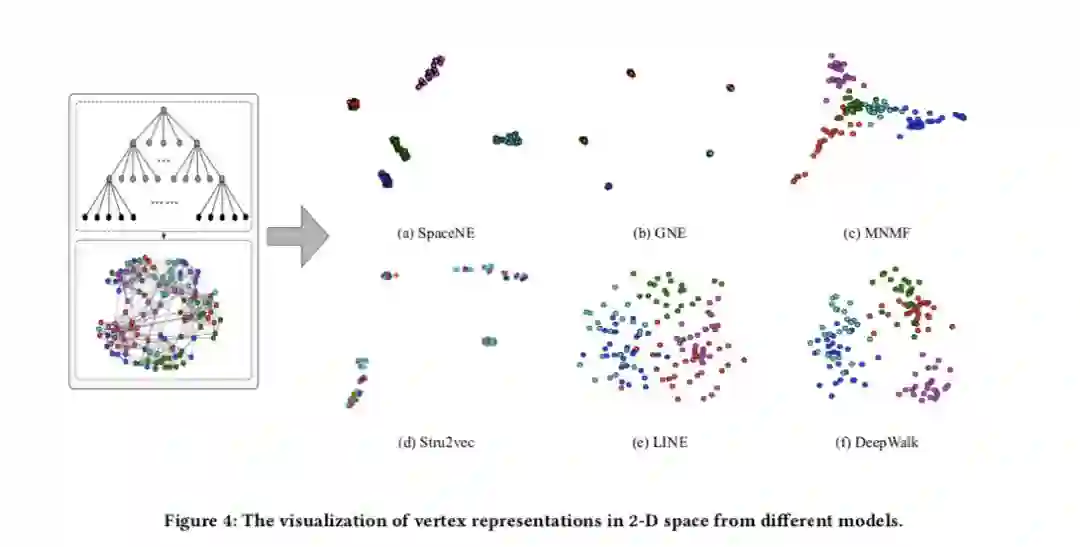
对于现实世界中普遍存在的关系数据,网络是对其建模最好的方式。于是将顶点映射到低维空间(即网络嵌入)适用于各种各样的预测任务。已经有许多工作研究了如何利用真实网络所具有的成对接近性(pairwise proximity),然而却很少有研究者关注真实网络的另一个特性,即聚类性。所谓聚类性,即顶点倾向于形成各种规模的社区——由此形成一个囊括不同社区的层级结构。
在Qingqing Long等人的这篇文章中,作者提出了一种子空间网络嵌入的框架SpaceNE(Subspace Network Embedding)。这个框架保留了社区通过子空间形成的层级结构,具有灵活的维数,且本质上具有层级结构。此外,在文章中作者认为子空间还能够解决表征层级社区的其他问题,例如稀疏性、空间扭曲等。
作者在论文中还提出针对子空间尺寸进行限制从而达到消除噪声的方法。这些约束条件通过可微分函数进一步逼近,从而达到联合优化。此外他们还采用了逐层方案来减少由参数过多引起的开销。实验证明SpaceNE在解决社区层级结构方面是有效的。
该奖项的获得者全部来自阿里巴巴安全团队,研究的内容是关于闲鱼上垃圾评论检测过滤,这也是应用向唯一的最佳论文(不像research track还有runner-up奖)。
论文链接:
http://www.cikm2019.net/attachments/papers/p2703-liA.pdf
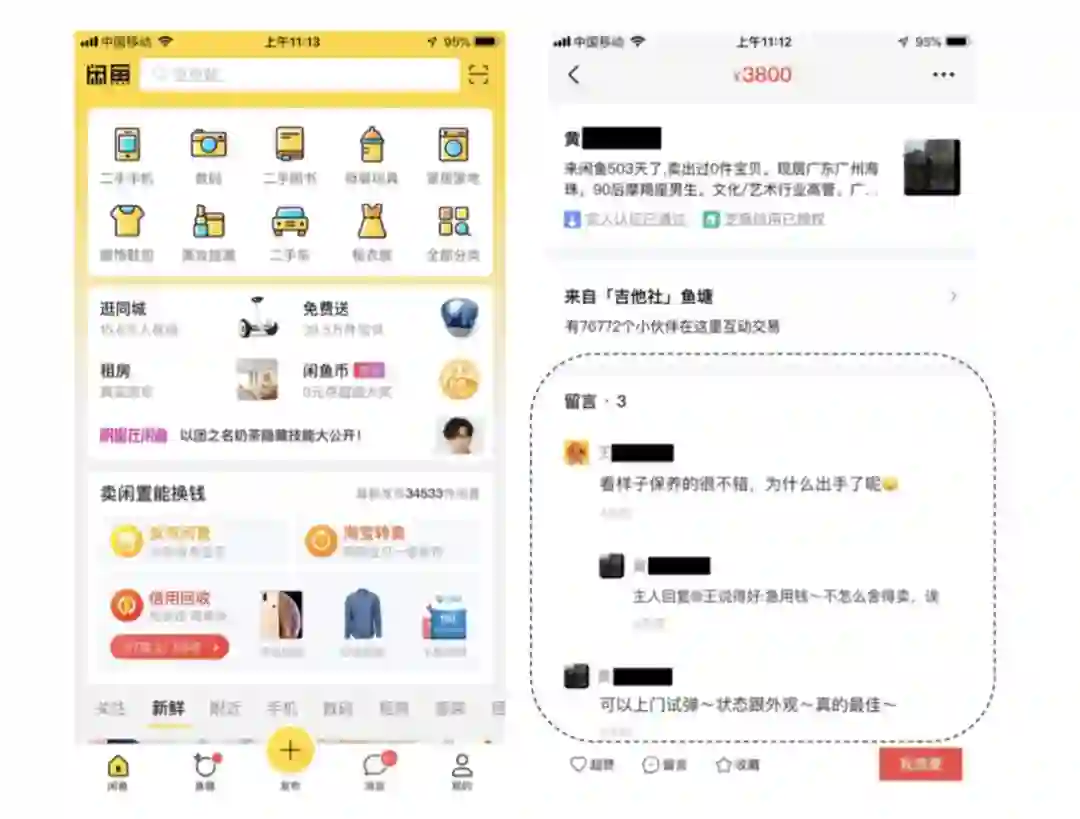
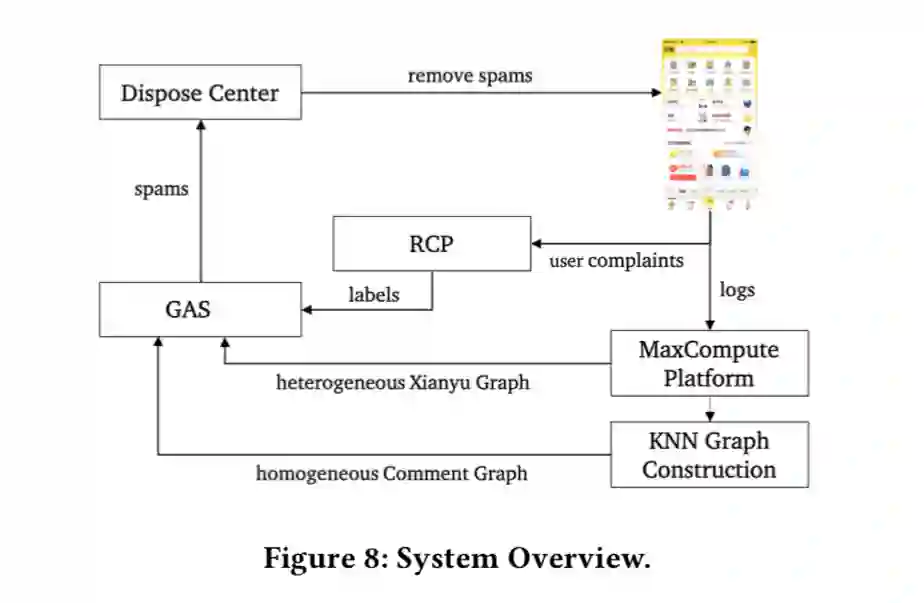
网上购物平台的评论会影响顾客的购买选择,这是我们每个人的亲身体会;但在各个网上购物平台往往会存在大量具有误导性的评论。闲鱼作为中国最大的二手商品交易平台,垃圾评论也同样大量存在。其背后的反垃圾系统面临着两个巨大的挑战:数据的可扩展性以及垃圾评论者的对抗行为。
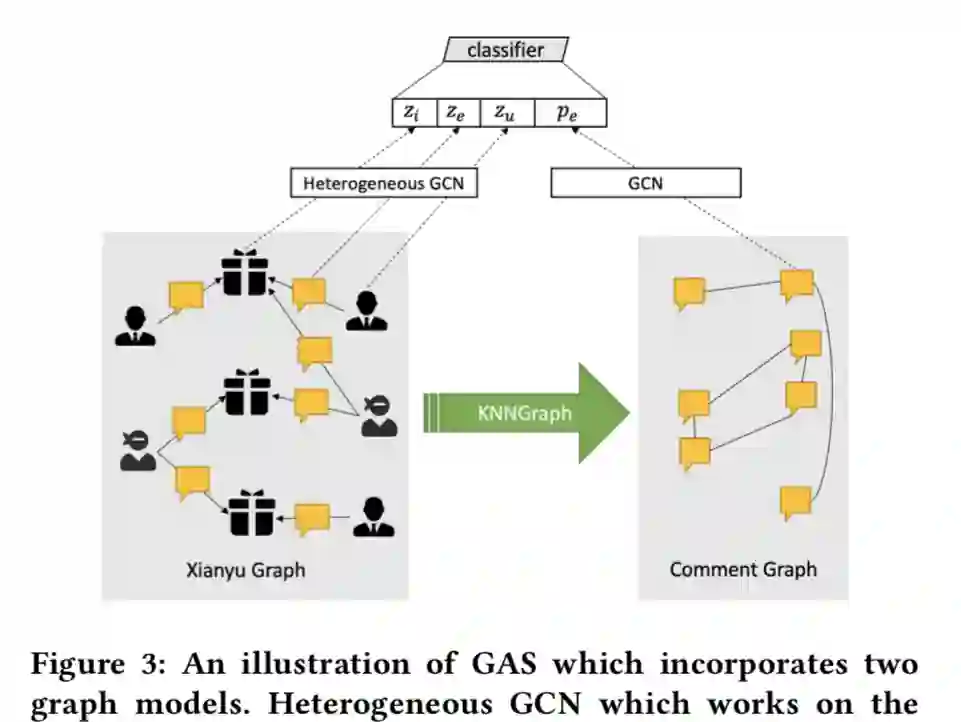
阿里的安全团队提出了一种基于图卷积网络(GCN)的大规模反垃圾的方法,名为GAS(GCN-based Anti-Spam)模型。
论文通过图神经网络算法提取闲鱼异构图和评论同构图上用户、商品、评论的表征信息,综合对评论进行判断。离线实验表明,这种方法优于利用评论信息、用户特征和浏览商品信息等来反垃圾的基线方法。
目前,这种新的算法已经在闲鱼评论的线上防控中部署,减少了包括刷单、兼职广告、引导线下交易的评论,优化了交易体验,降低了平台交易风险。
这里需要着重提一下,本次会议阿里不仅获得了两项最佳奖,还独家承办了2019年CIKM的挑战赛。在挑战赛中,开放了真实电商数据集供选手在用户行为预测和大规模推荐系统两大赛道进行角逐。主会期间,阿里巴巴甚至主办了一整天的E-commerce AI Workshop,分享了阿里的电商AI算法和电商AI基础设施。
论文链接:
http://www.cikm2019.net/attachments/papers/p2953-bozarthA.pdf
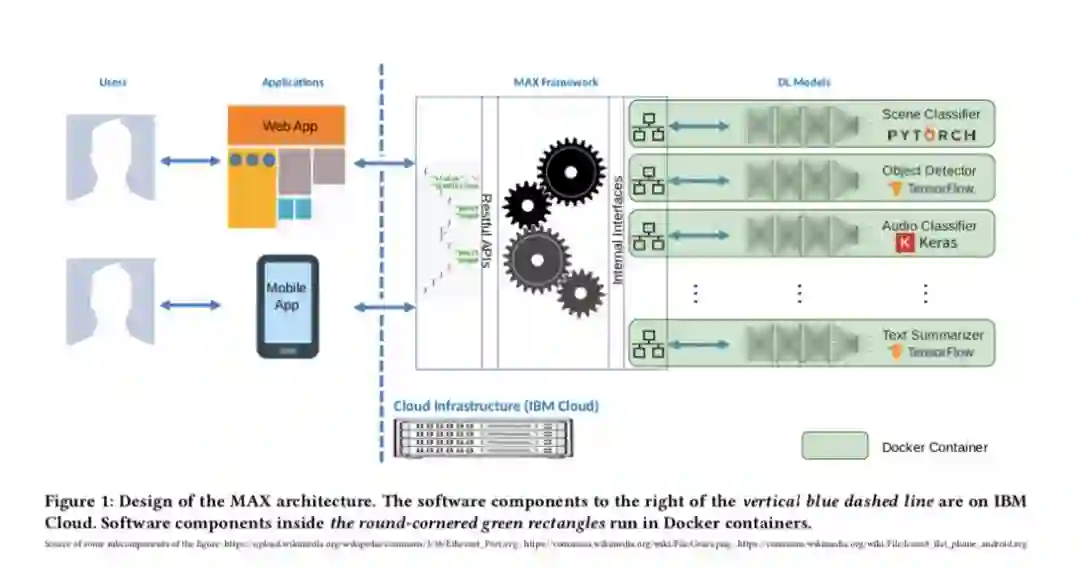
深度学习模型迅速发展,现在可以说已经无处不在。然而尽管研究人员很兴奋,但大多数软件开发者却并非深度学习专家,很难直接将DL的研究成果用到自己的开发当中,最新的DL模型通常需要相当长的时间才能在工业中得以广泛应用。特别是加上TensorFlow、PyTorch、Theano等框架的不兼容更导致这种情况恶化。
IBM的研究人员为了解决这个问题,提出了一个称为Model Asset Exchange(MAE)的系统,使用这个系统,开发人员可以轻松地访问最先进的深度学习模型。
在这个系统中,底层的深度学习框架可以是任何一种,在此之上他们提供了一个开源的Python库(MAX框架),这个库会将深度学习进行封装,并使用标准化的RESTful API将编程接口进行统一化。开发者只需使用这些API接口,便可以利用封装在里面的深度学习模型,而不用去管底层的框架。
IBM的研究人员利用MAX,封装并开源了30多个来自不同研究领域的最先进的深度学习模型,包括计算机视觉、自然语言处理和信号处理等。
本次会议满满的中国元素,特别是在Banquet中,舞狮,戏剧相继上演,甚至都把画脸谱、吹糖人都搬到了现场,看图说话:
![]() 舞狮
舞狮
![]() 京剧
京剧
![]() 画脸谱
画脸谱
![]()
![]() 点击“阅读原文”查看一份完全解读:是什么使神经网络变成图神经网络?
点击“阅读原文”查看一份完全解读:是什么使神经网络变成图神经网络?



 AutoGRD首先将数据集表示为图,并将它的隐式表示提取出来,然后将这个表示用来训练排序元模型,这个模型能够对未见过的数据集准确地推荐性能最佳的算法。
AutoGRD首先将数据集表示为图,并将它的隐式表示提取出来,然后将这个表示用来训练排序元模型,这个模型能够对未见过的数据集准确地推荐性能最佳的算法。



 舞狮
舞狮
 京剧
京剧
 画脸谱
画脸谱








