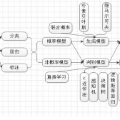
数据分析师应该知道的16种回归方法:定序回归
定序回归适用于因变量是有序的情形,可用预测有序数据。那么什么是有序数据呢?我们考虑以下三种情形:
1=1岁,2=2岁,3=3岁;
1=红色,2=黄色,3=蓝色;
1=不喜欢,2=无所谓,3=喜欢。
上述三种不同的情形,其数据代码都是1、2、3。第一种情形下,代码代表了小孩的年龄,这里的1、2、3是有具体的数值意义的,可作代数运算,即2岁-1岁=1岁,说明2岁的孩子比1岁的孩子大1岁。但是,第二种情形下,不能作代数运算,其数据类型是没有任何数值意义的。类似地,情形3中的数据类型也没有数值意义。那么,情形2和情形3的数据类型又有什么不一样的呢?对于情形2,我们完全可以打乱顺序而不会造成任何混乱。但是对于情形3,打乱顺序则会造成数据分析的混乱。由此可见,情形3中的数据有两个特征:
没有数值意义;
有顺序意义。
我们称这样的数据类型为定序数据。下面开始介绍定序回归的内容。
设因变量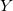


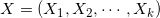
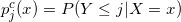
满足:
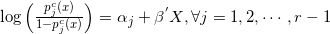
其中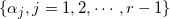
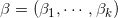
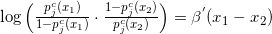
即在不同的
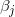
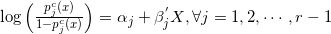
称这个模型为累积逻辑模型。在使用累积逻辑模型首先需要对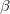
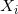
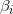
对于上述模型,可利用极大似然法可以对定序回归进行参数估计。一般来讲有两种估计路径:
先估计
,然后计算
,注
;
直接估计
。
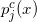 ,然后计算
,然后计算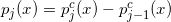 ,注
,注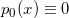 ;
;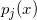 。
。案例
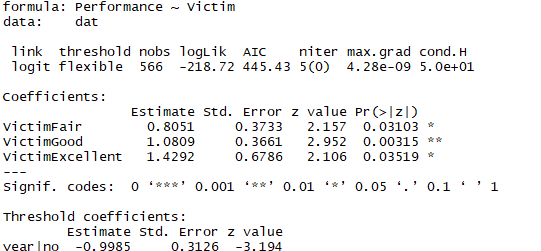
在某次社会调研中,要求受访群众对该地的刑事法官的工作进行评级。
一共有四种评价尺度,从低到高依次为:1=差,2=一般,3=好,4=极好。与此同时要求受访者报告近三年,家庭中是否有人是犯罪受害者。调查结果见下表

在R中使用ordinal包中的clm函数执行定序回归。
library(ordinal)
dt <- matrix(c(14,28,31,3,38,170,248,34),ncol = 4,
byrow = T,dimnames=list(c("year", "no"),
c("Poor", "Fair", "Good","Excellent")))
dat <- reshape2::melt(dt)
names(dat) <- c("Performance",'Victim','Number')
dat$Performance=as.factor(dat$Performance)
dat$Victim=as.factor(dat$Victim)
fm1 <- clm(Performance ~ Victim, weights = Number, data = dat)
summary(fm1)
推荐阅读
reticulate: R interface to Python
使用jupyter notebook搭建数据科学最佳交互式环境


长按二维码关注“数萃大数据”