R语言机器学习:xgboost的使用及其模型解释

作者:黄天元,复旦大学博士在读,目前研究涉及文本挖掘、社交网络分析和机器学习等。希望与大家分享学习经验,推广并加深R语言在业界的应用。
邮箱:huang.tian-yuan@qq.com
xgboost作为当前基于树模型的最佳预测方案,值得深入了解并实践。这里仅基于DALEX_and_xgboost(相关内容点击阅读原文)的内容进行简要的实践操作和介绍。
# 回归模型
## 数据的载入
这里使用breakDown包的wine函数进行建模。
```{r}
library("breakDown")
head(wine)
```
## 模型构建
在xgboost包中进行建模,必须要所有变量都转化为数值,而且最佳的方案是使用xgboost包内置的数据类型(使用`xgb.DMatrix`构造)。首先我们来构造这个矩阵:
```{r}
library("xgboost")
model_martix_train <- model.matrix(quality ~ . - 1, wine)
data_train <- xgb.DMatrix(model_martix_train, label = wine$quality)
```
这里,`model.matrix`函数一般用来对因子变量进行展平变为数值,但是这里我们的数据集没有因子变量,所以就仅仅把响应变量抽取了出来,并转化为矩阵类型(matrix)。下面,对必要的参数进行设置,并开始建模。
```{r}
param <- list(max_depth = 2, eta = 1, silent = 1, nthread = 2,
objective = "reg:linear")
wine_xgb_model <- xgb.train(param, data_train, nrounds = 50)
wine_xgb_model
```
用的是线性模型,参数请参考官网<XGBoost Parameters>。
## 模型解析
直接上DALEX包的explain函数即可。
```{r}
library("DALEX")
explainer_xgb <- explain(wine_xgb_model,
data = model_martix_train,
y = wine$quality,
label = "xgboost")
explainer_xgb
```
## 单变量解析
随着酒精含量的变化,酒的质量有什么变化?
```{r}
sv_xgb_satisfaction_level <- variable_response(explainer_xgb,
variable = "alcohol",
type = "pdp")
head(sv_xgb_satisfaction_level)
plot(sv_xgb_satisfaction_level)
```
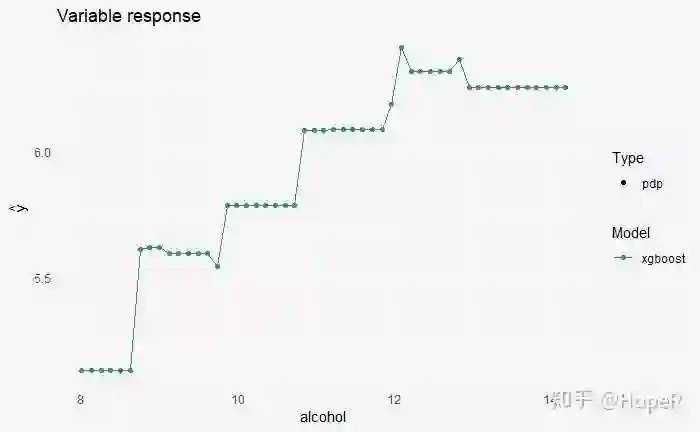
## 在一次预测中不同变量的贡献
尽管模型是对总体的总结,但是对于不同的个体而言,每个变量对其最终预测起到的作用是有差别的。我们把第一个样本取出来,然后进行尝试。
```{r}
nobs <- model_martix_train[1, , drop = FALSE]
sp_xgb <- prediction_breakdown(explainer_xgb,
observation = nobs)
head(sp_xgb)
plot(sp_xgb)
```
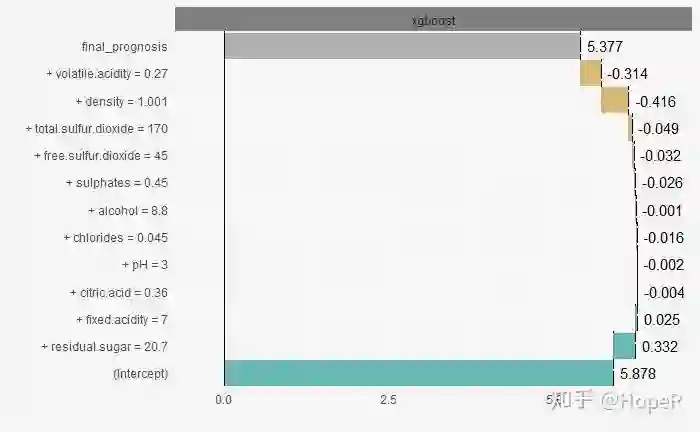
从这个试验中我们可以看到,fixed.acidity和residual.sugar在这个预测中被认为有积极的作用,而volatile.acidity和density则相反。
## 变量重要性
```{r}
vd_xgb <- variable_importance(explainer_xgb, type = "raw")
head(vd_xgb)
plot(vd_xgb)
```
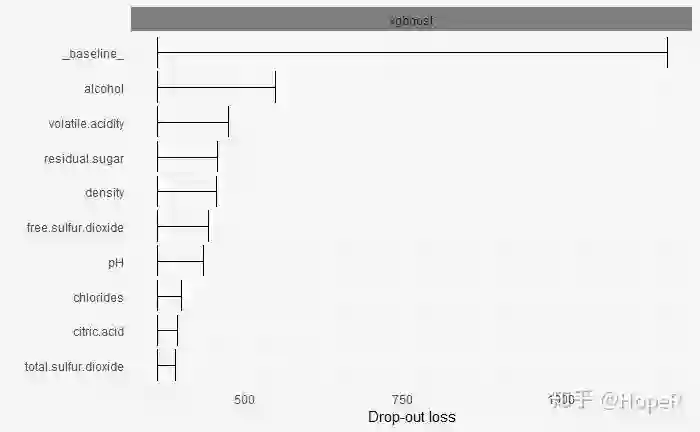
# 分类模型
## 数据的载入
这里使用离职率预测的数据集进行探索。
```{r}
library("breakDown")
head(HR_data)
```
## 模型构建
过程基本与上面一致,不做赘述。值得注意的是,这份数据集中是有因子变量的,所以做model.matrix非常合适。此外,中间的公式`left ~ . - 1`表示的是减去截距,如果不理解,可以不减试试看。因为响应变量只有两种类型,所以使用逻辑回归,采用AUC作为评价标准。
```{r}
library("xgboost")
model_martix_train <- model.matrix(left ~ . - 1, HR_data)
data_train <- xgb.DMatrix(model_martix_train, label = HR_data$left)
param <- list(max_depth = 2, eta = 1, silent = 1, nthread = 2,
objective = "binary:logistic", eval_metric = "auc")
HR_xgb_model <- xgb.train(param, data_train, nrounds = 50)
HR_xgb_model
```
## 模型解析
DALEX只能够处理数值型的响应变量,因此这里需要设置连接函数和预测函数。
```{r}
library("DALEX")
predict_logit <- function(model, x) {
raw_x <- predict(model, x)
exp(raw_x)/(1 + exp(raw_x)) #虽然官方文档加了这个,但是真的需要吗?预测值本身就是概率值
}
logit <- function(x) exp(x)/(1+exp(x))
```
我们来看看函数的功能。predict_logit函数接受一个模型和数据x(虽然没有定义类型,但是我们能够判断基本是一个新的数据集),根据模型对新的数据进行预测,然后对预测值进行转化(链接函数)。而logit就是链接函数的格式。
下面用函数进行解析。
```{r}
explainer_xgb <- explain(HR_xgb_model,
data = model_martix_train,
y = HR_data$left,
predict_function = predict_logit,
link = logit,
label = "xgboost")
explainer_xgb
```
# 单变量解析
```{r}
sv_xgb_satisfaction_level <- variable_response(explainer_xgb,
variable = "satisfaction_level",
type = "pdp")
head(sv_xgb_satisfaction_level)
plot(sv_xgb_satisfaction_level)
```
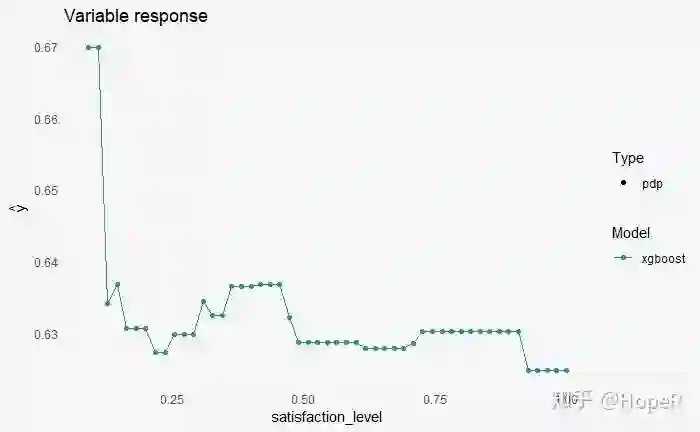
随着满意度升高,离职的概率在减少。
# 单样本预测
```{r}
nobs <- model_martix_train[1, , drop = FALSE]
sp_xgb <- prediction_breakdown(explainer_xgb,
observation = nobs)
head(sp_xgb)
plot(sp_xgb)
```

对于这个员工而言,最后一次评估这个变量的贡献最大。
## 变量重要性
```{r}
vd_xgb <- variable_importance(explainer_xgb, type = "raw")
head(vd_xgb)
plot(vd_xgb)
```
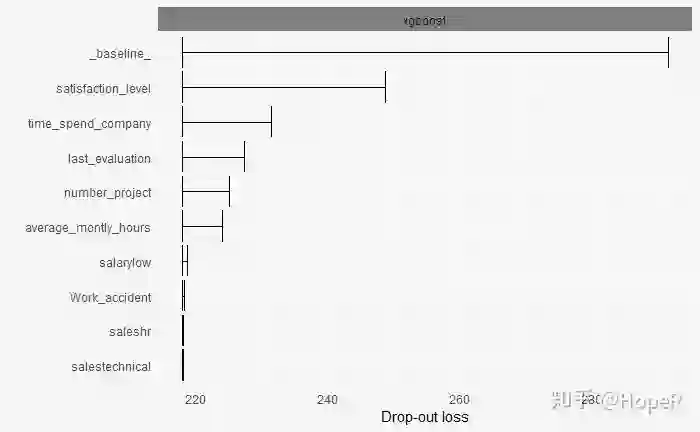
员工的满意度是最能够反映离职率的变量。
——————————————
往期精彩:





