漫谈全景分割
加入极市专业CV交流群,与6000+来自腾讯,华为,百度,北大,清华,中科院等名企名校视觉开发者互动交流!更有机会与李开复老师等大牛群内互动!
同时提供每月大咖直播分享、真实项目需求对接、干货资讯汇总,行业技术交流。点击文末“阅读原文”立刻申请入群~
作者:刘环宇
本文授权转载自旷视MEGVII(megvii)
前言
在计算机视觉中,图像语义分割(Semantic Segmentation)的任务是预测每个像素点的语义类别;实例分割(Instance Segmentation)的任务是预测每个实例物体包含的像素区域。全景分割 (Panoptic Segmentation) [1] 最先由 FAIR 与德国海德堡大学联合提出,其任务是为图像中每个像素点赋予类别 Label 和实例 ID ,生成全局的、统一的分割图像。
ECCV 2018 最受瞩目的 COCO + Mapillary 联合挑战赛也首次加入全景分割任务,是全景分割领域中最权威与具有挑战性的国际比赛,代表着当前计算机视觉识别技术最前沿。在全景分割比赛项目中,旷视研究院 Detection 组参与了COCO 比赛项目与 Mapillary 比赛项目,并以大幅领先第二名的成绩实力夺魁,在全景分割指标 PQ 上取得了0.532的成绩,超越了 human consistency ,另外,我们的工作《An End-to-End Network for Panoptic Segmentation》也发表于 CVPR 2019 上。
接下来我们将全面解读全景分割任务,下面这张思维导图有助于大家整体把握全景分割任务特性:
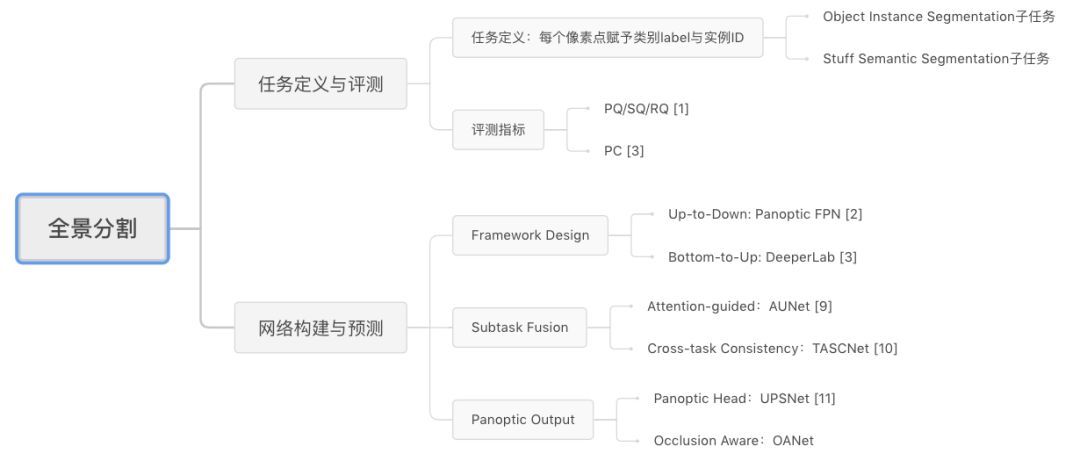
全景分割解读思维导图
首先,我们将分析全景分割任务的评价指标及基本特点,并介绍目前最新的研究进展;然后介绍我们发表于 CVPR 2019 的工作 Occlusion Aware Network (OANet),以及旷视研究院 Detection 组参与的 2018 COCO Panoptic Segmentation 比赛工作介绍;最后对全景分割当前研究进行总结与分析。
任务与前沿进展解读
全景分割任务,从任务目标上可以分为 object instance segmentation 子任务与 stuff segmentation 子任务。全景分割方法通常包含三个独立的部分:object instance segmentation 部分,stuff segmentation 部分,两子分支结果融合部分;通常object instance segmentation 网络和 stuff segmentation 网络相互独立,网络之间不会共享参数或者图像特征,这种方式不仅会导致计算开销较大,也迫使算法需要使用独立的后处理程序融合两支预测结果,并导致全景分割无法应用在工业中。
因此,可以从以下几个角度分析与优化全景分割算法:
(1)网络框架搭建;
(2)子任务融合;
(3)全景输出预测;
这三个问题分别对应的是全景分割算法中的三个重要环节,下面我们将分别分析这些问题存在的难点,以及近期相关工作提出的改进方法与解决方案。
全景分割评价指标
FAIR研究团队 [1] 为全景分割定了新的评价标准 PQ (panoptic segmentation) 、SQ ( segmentation quality)、RQ (recognition quality) ,计算公式如下:
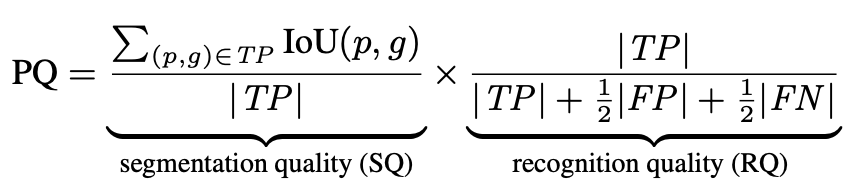
PQ 评价指标计算公式
其中,RQ是检测中应用广泛的 F1 score,用来计算全景分割中每个实例物体识别的准确性,SQ 表示匹配后的预测 segment与标注 segment 的 mIOU,如下图所示,只有当预测 segment 与标注 segment 的 IOU 严格大于 0.5 时,认为两个 segment 是匹配的。
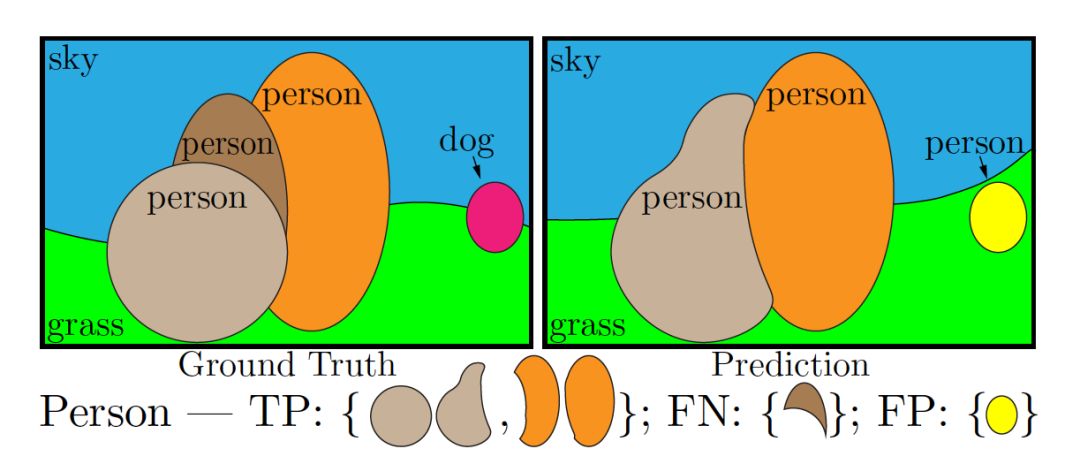
全景分割预测结果与真实标注匹配图解 [1]
从上面的公式能够看到,在预测与标注匹配后的分割质量 SQ 计算时,评价指标PQ只关注每个实例的分割质量,而不考虑不同实例的大小,即大物体与小物体的分割结果对最终的PQ结果影响相同。Yang et al. [6] 注意到在一些应用场景中更关注大物体的分割结果,如肖像分割中大图的人像分割、自动驾驶中近距离的物体等,提出了 PC (Parsing Covering) 评价指标,计算公式如下:
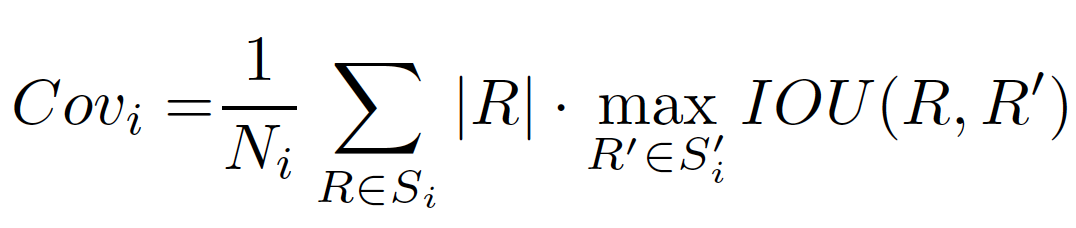
PC 评价指标计算公式
其中, 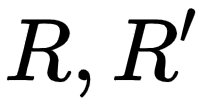
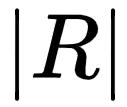
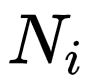
网络框架搭建
由于 object instance segmentation 子任务与 stuff segmentation 子任务分别属于两个不同的视觉预测任务,其输入数据及数据增强方式、训练优化策略与方法、网络结构与方法具有较大的不同,如何将两个子任务融合并统一网络结构、训练策略,是解决该问题的关键。
FAIR 研究团队提出了一种简洁有效的网络结构 Panoptic FPN [2],在网络框架层面将语义分割的全卷积网络(FCN)[3] 和实例分割网络 Mask RCNN [4] 统一起来,设计了单一网络同时预测两个子任务,网络结构如下图所示。
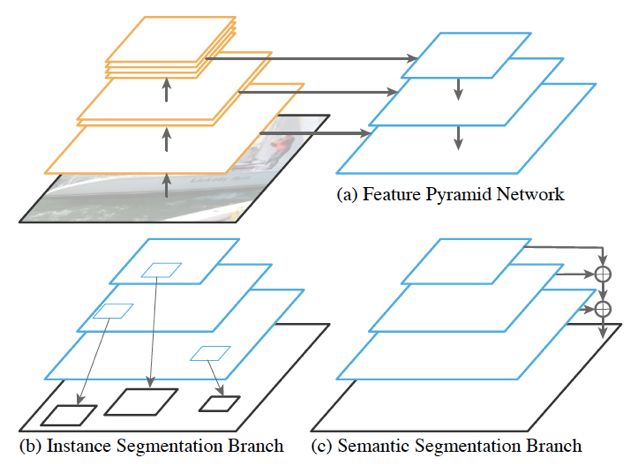
Panoptic FPN网络框架图
该网络结构能够有效预测 object instance segmentation 子任务与 stuff segmentation 子任务。在 Mask RCNN 网络与 FPN [5] 的基础上,作者设计了简单而有效的 stuff segmentation 子分支:在 FPN 得到的不同层级的特征图基础上,使用不同的网络参数得到相同大小的特征图,并对特征图进行加法合并,最后使用双线性插值上采样至原图大小,并进行stuff 类别预测。
MIT与谷歌等联合提出DeeperLab [6] ,使用 bottom-to-up 的方法,同时实现 object instance segmentation 子任务与 stuff segmentation 子任务,其网络结构如下图所示:
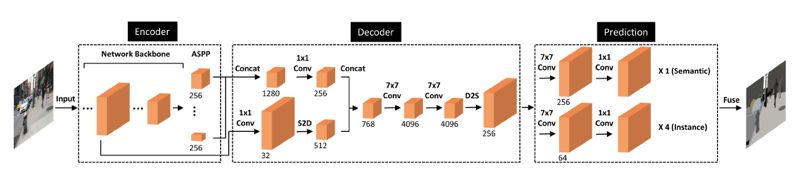
DeeperLab 网络结构图
该网络包含了 encoder、decoder 与 prediction 三个环节,其中,encoder 和 decoder 部分对两个子任务均是共享的,为了增强 encoder 阶段的特征,在 encoder 的末尾使用了ASPP (Atrous Spatial Pyramid Pooling) 模块 [7];而在decoder阶段,首先使用 1×1 卷积对低层特征图与 encoder 输出的特征图进行降维,并使用内存消耗较少的space-to-depth [8, 9] 操作替代上采样操作对低层特征图进行处理,从而将低层特征图(大小为原图1/4)与 encoder 输出的特征图(大小为原图 1/16 )拼接起来;最后,使用两层 7×7 的大卷积核增加感受野,然后通过 depth-to-space 操作降低特征维度。
为了得到目标实例预测,作者采用类似 [10, 11, 12] 的使用基于关键点表示的方法,如下图所示,在 object instance segmentation 子分支头部,分别预测了 keypoint heatmap(图a)、long-range offset map(图b)、short-range offset map(图c)、middle-range offset map(图d)四种输出,得到像素点与每个实例关键点之间的关系,并依此融合形成类别不可知的不同实例,最后得到全景分割的结果。
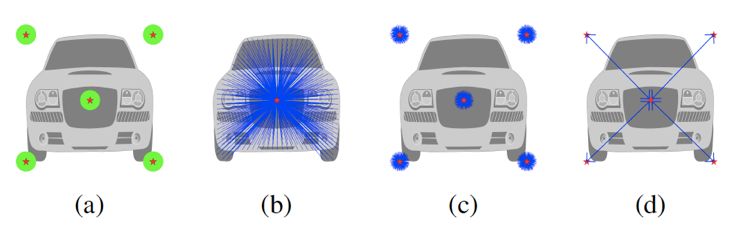
object instance segmentation 子分支头部预测目标
子任务融合
虽然通过特征共享机制与网络结构设计,能够将 object instance segmentation 子任务与 stuff segmentation 子任务统一起来,但是这两个子分支之间的相互联系与影响并没有得到充分的探究,例如:两个子分支的任务是否能够达到相互增益或者单向增益的效果?或者如何设计将两个子分支的中间输出或者预测关联起来?这一部分问题我们可以统一将它称作两个子任务的相互提升与促进。
中科院自动化研究所提出了AUNet [13],文中设计了 PAM (Proposal Attention Module)与 MAM(Mask Attention Module)模块,分别基于RPN阶段的特征图与 object instance segmentation 输出的前景分割区域,为 stuff segmentation 提供了物体层级注意力与像素层级注意力,其网络结构图如下图所示:
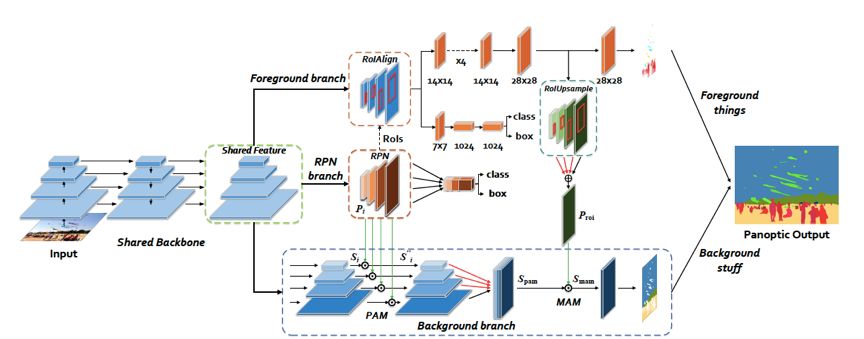
AUNet 网络结构图
为了使 object instance segmentation 的预测输出与 stuff segmentation 预测输出保持一致性,丰田研究院设计了 TASCNet [14],其网络结构如下图所示:
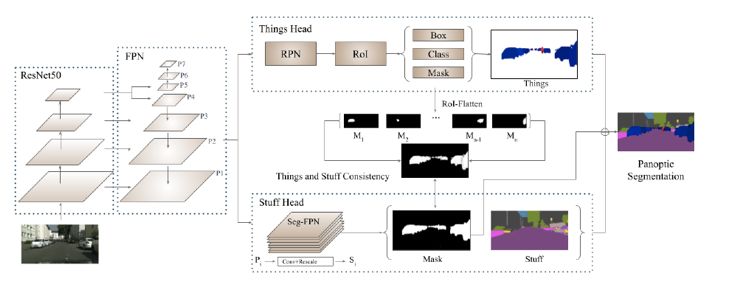
TASCNet网络结构图
网络首先将 object instance segmentation 子分支得到的实例前景掩膜区域,映射到原图大小的特征图中,得到全图尺寸下的实例前景掩膜区域,并与 stuff segmentation 预测的实例前景掩膜进行对比,使用L2损失函数最小化两个掩膜的残差。
全景输出预测
Object instance segmentation 子分支与 stuff segmentation 子分支的预测结果在融合的过程中,一般通过启发式算法(heuristic algorithm)处理相冲突的像素点,例如简单地以 object instance segmentation 子分支的预测结果为准,并以 object instance segmentation 子分支的检测框得分作为不同实例的合并依据。
这种方式依据简单的先验逻辑判断,并不能较好地解决全景分割复杂的合并情况,因此,如何设计有效的模块解决 object instance segmentation 子分支与 stuff segmentation 子分支到全景分割输出的融合过程,也是全景分割任务中的重要问题。
Uber与港中文联合提出了 UPSNet [15] ,其网络结构图如下图所示:
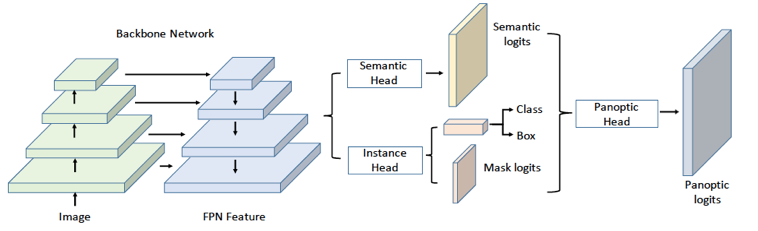
UPSNet网络结构图
将 object instance segmentation 子分支与 stuff segmentation 子分支的输出通过映射变换,可得到全景头部输出的特征张量,该张量大小为 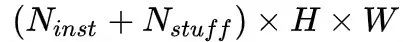
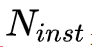

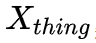
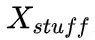
在得到 object instance segmentation 子分支与 stuff segmentation 子分支的输出后,经过如下图所示的变换,映射成
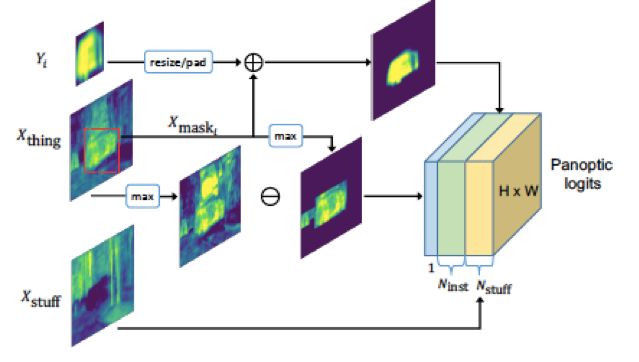
panoptic segmentation head示意图
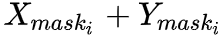
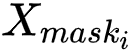
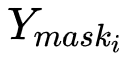
Occlusion Aware Network专栏解读
论文Arxiv链接:
https://arxiv.org/abs/1903.05027
Motivation
在全景分割相关实验中,我们发现,依据现有的启发式算法进行 object instance segmentation 子分支与 stuff segmentation 子分支的预测合并,会出现不同实例之间的遮挡现象。为了解决不同实例之间的遮挡问题,我们提出了 Occlusion Aware Network (OANet),并设计了空间排序模块(Spatial Ranking Module),该模块能够通过网络学习得到新的排序分数,并为全景分割的实例分割提供排序依据。
网络结构设计
我们提出的端到端的全景分割网络结构如下图所示,该网络融合 object instance segmentation 子分支与 stuff segmentation 子分支的基础网络特征,在一个网络中同时实现全景分割的训练与预测。在训练过程中,对于 stuff segmentation 我们同时进行了 object 类别与 stuff 类别的监督训练,实验表明这种设计有助于 stuff 的预测。
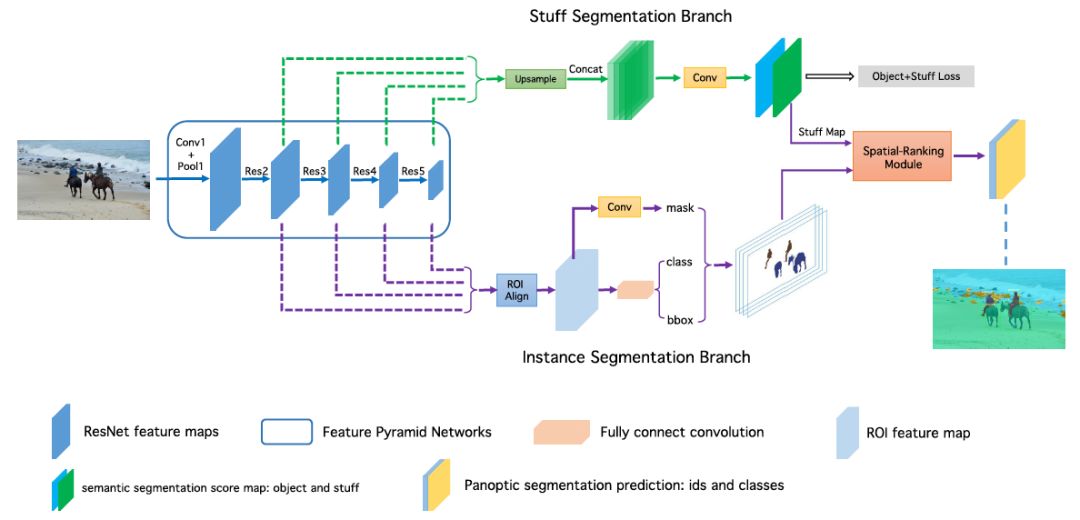
OANet网络结构图
采用一种类似语义分割的方法,我们提出一个简单但非常有效的算法,称作Spatial Ranking Module,能够较好地处理遮挡问题,其网络结构如下所示:
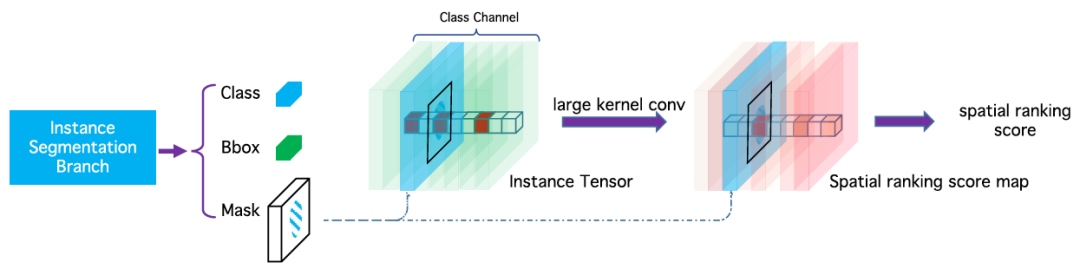
Spatial Ranking Module网络结构图
我们首先将输入的实例分割结果映射到原图大小的张量之中,该张量的维度是实例物体类别的数量,不同类别的实例分割掩膜会映射到对应的通道上。张量中所有像素点位置的初始化数值为零,实例分割掩膜映射到的位置其值设为1;在得到该张量后,使用大卷积核 [16] 进行特征提取,得到空间排序得分图;最后,我们计算出每个实例对象的空间排序得分,如下所示:
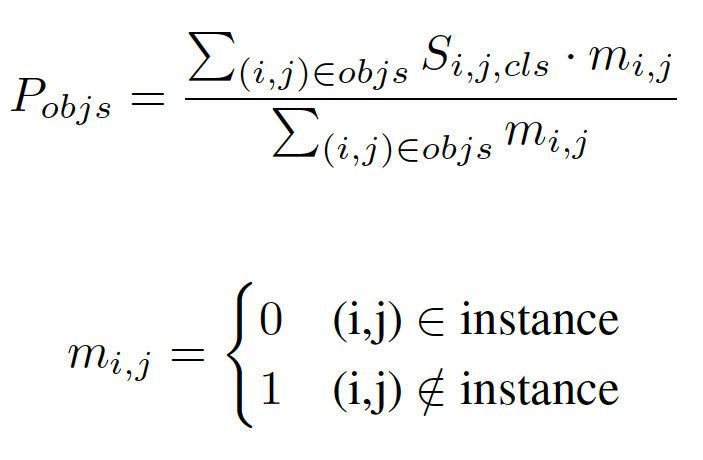
这里,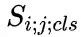
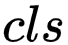
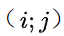
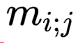
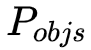
如下图所示,若使用目前通用的启发式融合算法,即仅基于实例分割的检测框的置信度作为遮挡处理依据,如图所示,行人检测框的置信度要明显高于领带检测框的置信度,当两个实例发生重叠时,领带的实例会被行人实例遮挡;当加入空间排序得分模块后,我们通过该模块可以预测得到两个实例的空间排序分数,依据空间排序分数得到的排序会更可靠,PQ 会有更大改善。

空间排序模块流程示意图
实验分析
我们对 stuff segmentation 分支的监督信号进行了剥离实验,如下表所示,实验表明,同时进行 object 类别与 stuff 类别的监督训练,能够为 stuff segmentation 提供更多的上下文信息,并改进预测结果。
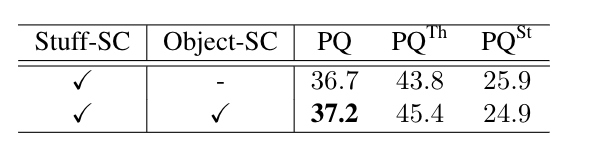
为了探究object instance segmentation 子分支与 stuff segmentation 子分支的共享特征方式,我们设计了不同的共享结构并进行实验,如下表所示,实验表明,共享基础模型特征与FPN 结构的连接处特征,能够提高全景分割指标 PQ 。
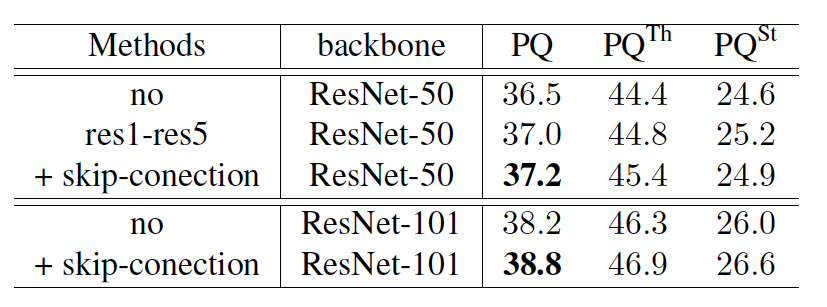
为了探究我们提出的 spatial ranking module 算法的有效性,我们在不同基础模型下进行了实验,如下表所示,其中,w/ spatial ranking module 表示使用我们提出的空间排序模块得到的结果,从实验结果中可以看到,空间排序模块能够在不同的基础模型下大幅提高全景分割的评测结果。

为了测试不同卷积设置对学习处理遮挡的影响,进行了如下实验,结果表明,提高卷积的感受也可以帮助网络学习获得更多的上下文特征,并取得更好的结果。
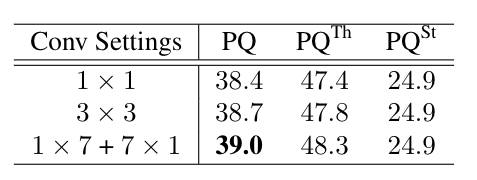
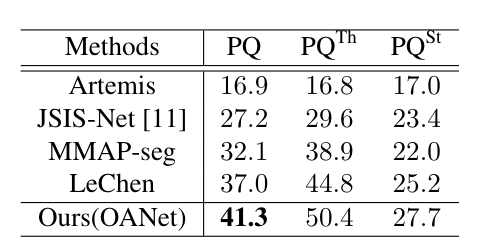
下表是本文提出的算法与现有公开指标的比较,从结果中可以看到,本文提出的算法能够取得最优的结果。
2018 COCO 全景分割比赛冠军解读
旷视研究院 Detection 组参与的全景分割 COCO 比赛项目与 Mapillary 比赛项目中,以大幅领先第二名的成绩实力夺魁,在全景分割指标 PQ 上取得了 0.532 的成绩,超越了 human consistency 。

COCO 2018 Panoptic Leaderboard

全景分割预测可视化图例
在比赛中,我们使用了如下图所示的流程,首先分别预测 stuff semantic segmentation 与 object instance segmentation,然后通过后处理的操作得到全景分割的结果。
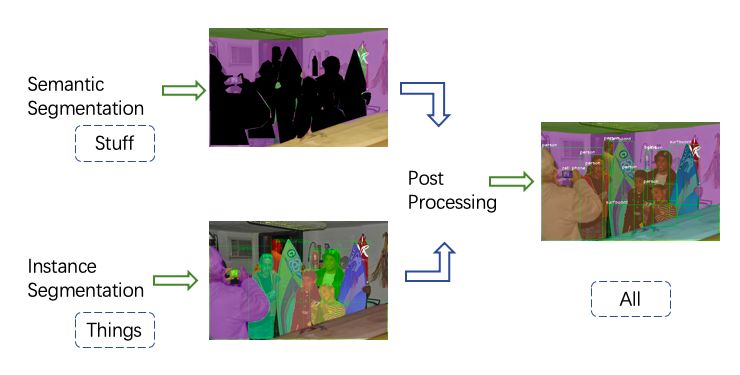
全景分割算法流程图
在 stuff semantic segmentation 预测阶段,首先我们对网络结构进行了部分调整以得到更好的分割效果。首先,网络最终的下采样倍数设为 8 ,保证输出结果的分辨率;然后,由于网络的 encoder 不会扩大网络的感受野, 因此我们在标准 ResNet 之后使用了若干层 Res-Block。
另外,实验发现 stuff 类别和 object 类别之间的上下文对于 stuff 分割较为重要,因此我们在网络预测中融入了上下文信息,并通过多阶段、多种监督的方式实现,网络结构如下图所示:
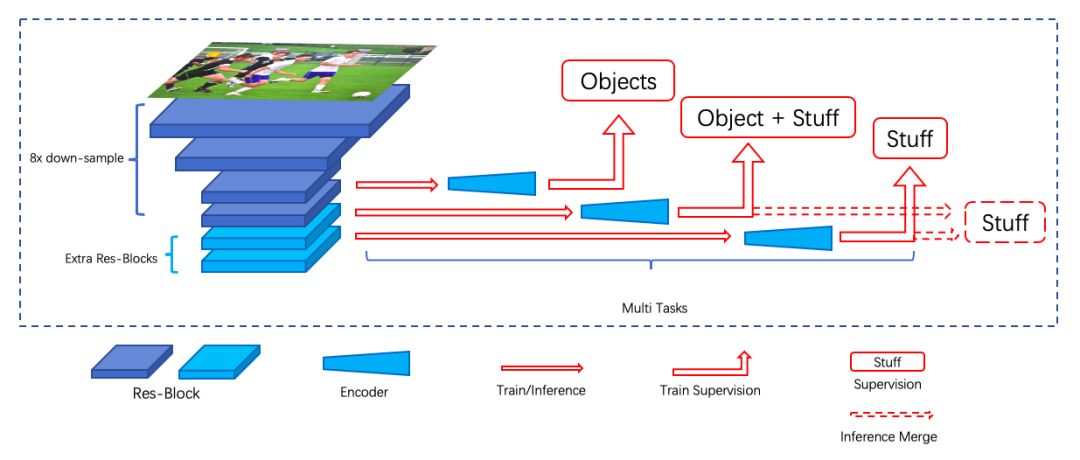
stuff semantic segmentation 结构图
对于 object instance segmentation,我们使用了与 Mask RCNN 相同的网络结构及训练配置。最后,通过使用更大的网络基础模型,multi scale + flip 的测试方法,以及多模型的ensemble操作,我们取得了最终的预测结果,如下图所示:
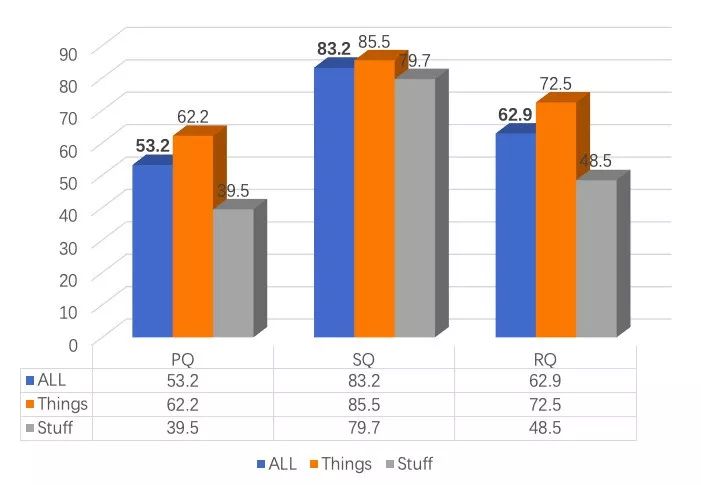
Panoptic Results on COCO test-dev Dataset
总结与分析
从上文的文献分析来看,全景分割任务的不同重要问题均得到了广泛探究,但是全景分割任务依然是有挑战性、前沿的场景理解问题,目前仍存在一些问题需要进行探究:
第一,由于全景分割可通过分别预测实例分割子任务与不规则类别分割子任务、两个子任务预测结果融合得到,整个算法流程中包含较多的细节与后处理操作,包括segments的过滤、启发式融合算法、ignore 像素点的判断等。这些细节对全景分割指标有较大的影响,在一定程度上也阻碍了不同算法的对比与评测;
第二,全景分割评测指标虽然能够较好地评测全景分割中实例物体检测准确度,以及实例物体与不规则类别的分割准确度,但是该评测指标更侧重每个实例,并没有关注每个实例之间的区别。文献 [6] 提出了对大物体有更好的评测指标PC (Parsing Covering),使得大物体的分割效果对最终的评测指标影响更大,在一些关注大物体的任务如肖像分割、自动驾驶中更为有效;
第三,全景分割中子任务的融合问题,目前研究依然较多地将全景分割看做是 object instance segmentation 与 stuff segmentation 两个子任务的合集,如何从全局、统一的分割问题出发,针对性设计符合全景分割的统一网络,具有重要的意义。
参考文献
[1] Kirillov A, He K, Girshick R, et al. Panoptic segmentation[J]. arXiv preprint arXiv:1801.00868, 2018.
[2] Kirillov A, Girshick R, He K, et al. Panoptic Feature Pyramid Networks[J]. arXiv preprint arXiv:1901.02446, 2019.
[3] Long J, Shelhamer E, Darrell T. Fully convolutional networks for semantic segmentation[C]//Proceedings of the IEEE conference on computer vision and pattern recognition. 2015: 3431-3440.
[4] He K, Gkioxari G, Dollár P, et al. Mask r-cnn[C]//Proceedings of the IEEE international conference on computer vision. 2017: 2961-2969.
[5] Lin T Y, Dollár P, Girshick R, et al. Feature pyramid networks for object detection[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2017: 2117-2125.
[6] Yang T J, Collins M D, Zhu Y, et al. DeeperLab: Single-Shot Image Parser[J]. arXiv preprint arXiv:1902.05093, 2019.
[7] Chen L C, Papandreou G, Kokkinos I, et al. Deeplab: Semantic image segmentation with deep convolutional nets, atrous convolution, and fully connected crfs[J]. IEEE transactions on pattern analysis and machine intelligence, 2018, 40(4): 834-848.
[8] Shi W, Caballero J, Huszár F, et al. Real-time single image and video super-resolution using an efficient sub-pixel convolutional neural network[C]//Proceedings of the IEEE conference on computer vision and pattern recognition. 2016: 1874-1883.
[9] Sajjadi M S M, Vemulapalli R, Brown M. Frame-recurrent video super-resolution[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2018: 6626-6634.
[10] Papandreou G, Zhu T, Chen L C, et al. PersonLab: Person pose estimation and instance segmentation with a bottom-up, part-based, geometric embedding model[C]//Proceedings of the European Conference on Computer Vision (ECCV). 2018: 269-286.
[11] Tychsen-Smith L, Petersson L. Denet: Scalable real-time object detection with directed sparse sampling[C] // Proceedings of the IEEE International Conference on Computer Vision. 2017: 428-436.
[12] Law H, Deng J. Cornernet: Detecting objects as paired keypoints [C] // Proceedings of the European Conference on Computer Vision (ECCV). 2018: 734-750.
[13] Li Y, Chen X, Zhu Z, et al. Attention-guided unified network for panoptic segmentation[J]. arXiv preprint arXiv:1812.03904, 2018.
[14] Li J, Raventos A, Bhargava A, et al. Learning to fuse things and stuff[J]. arXiv preprint arXiv:1812.01192, 2018.
[15] Xiong Y, Liao R, Zhao H, et al. UPSNet: A Unified Panoptic Segmentation Network[J]. arXiv preprint arXiv:1901.03784, 2019.
[16] Peng C, Zhang X, Yu G, et al. Large Kernel Matters--Improve Semantic Segmentation by Global Convolutional Network[C] // Proceedings of the IEEE conference on computer vision and pattern recognition. 2017: 4353-4361.
---------解读者介绍-------
刘环宇,浙江大学控制科学与工程自动化系硕士,旷视科技研究院算法研究员,全景分割算法 OANet 第一作者,研究方向包括全景分割、语义分割等;2018 COCO + Mapillary 全景分割比赛旷视 Detection 组冠军团队成员。
*延伸阅读
CVPR2019 | 全景分割:Attention-guided Unified Network
CVPR2019 | 实例分割的进阶三级跳:从 Mask R-CNN 到 Hybrid Task Cascade
点击左下角“阅读原文”,即可申请加入极市目标跟踪、目标检测、工业检测、人脸方向、视觉竞赛等技术交流群,更有每月大咖直播分享、真实项目需求对接、干货资讯汇总,行业技术交流,一起来让思想之光照的更远吧~

△长按关注极市平台
觉得有用麻烦给个在看啦~

