一文详尽系列之EM算法
思想
举例
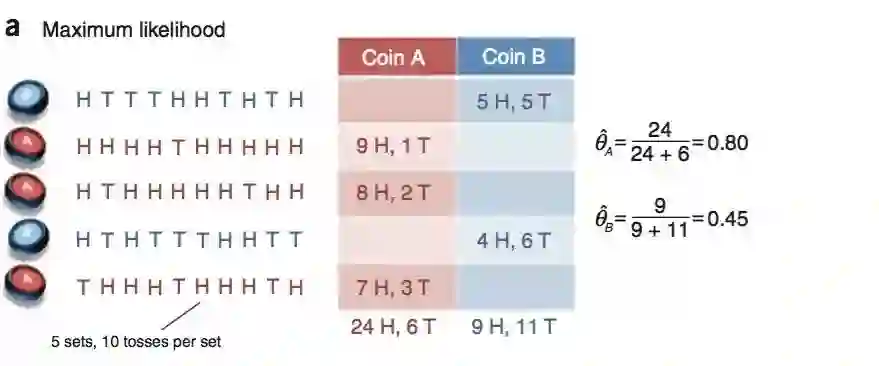
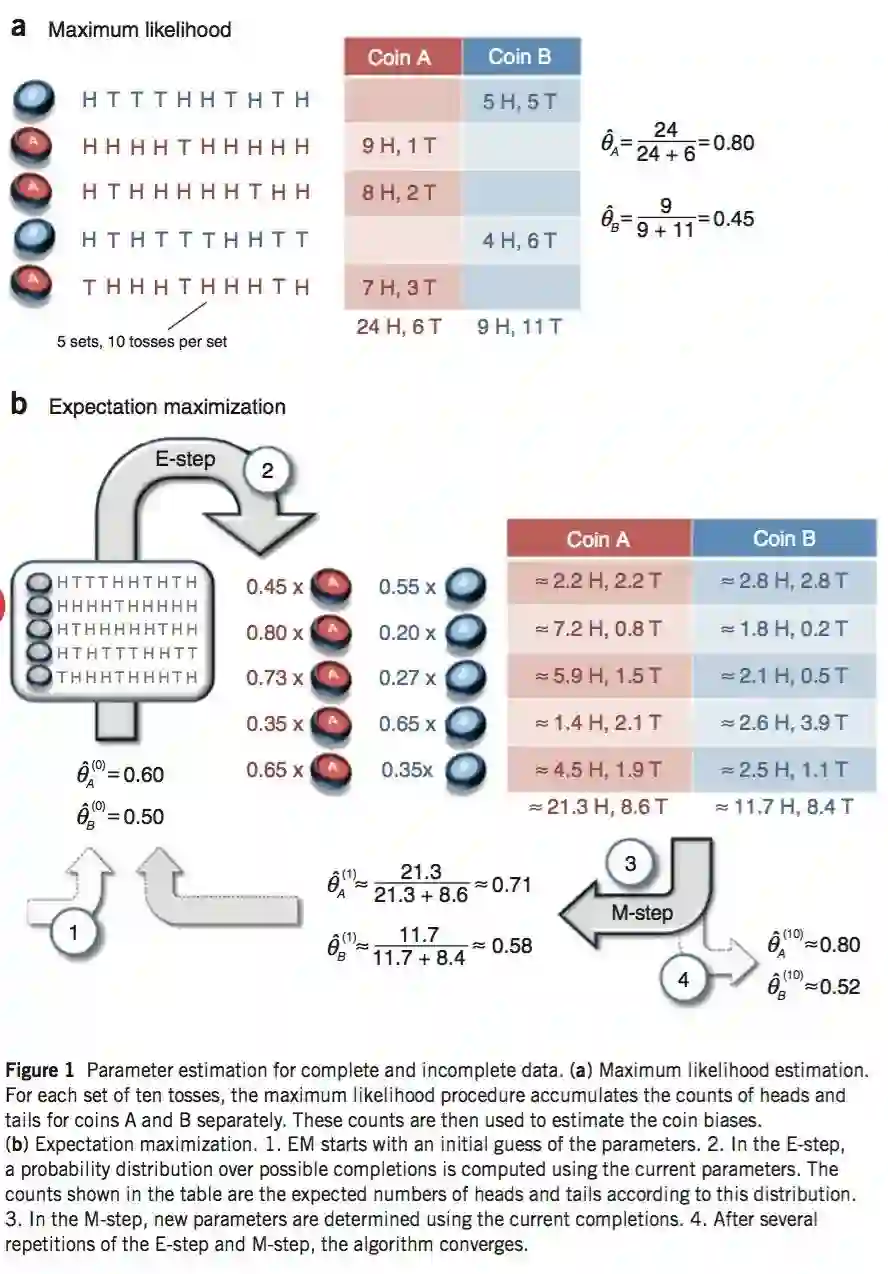
| Coin | Statistics |
|---|---|
| Coin * | 5 H, 5 T |
| Coin * | 9 H, 1 T |
| Coin * | 8 H, 2 T |
| Coin * | 4 H, 6 T |
| Coin * | 7 H, 3 T |
| No | Coin A | Coin B |
|---|---|---|
| 1 | 0.45 | 0.55 |
| 2 | 0.80 | 0.20 |
| 3 | 0.73 | 0.27 |
| 4 | 0.35 | 0.65 |
| 5 | 0.65 | 0.35 |
| No | Coin A | Coin B |
|---|---|---|
| 1 | 2.2 H, 2.2 T | 2.8 H, 2.8 T |
| 2 | 7.2 H, 0.8 T | 1.8 H, 0.2 T |
| 3 | 5.9 H, 1.5 T | 2.1 H, 0.5 T |
| 4 | 1.4 H, 2.1 T | 2.6 H, 3.9 T |
| 5 | 4.5 H, 1.9 T | 2.5 H, 1.1 T |
| total | 21.3 H, 8.6 T | 11.7 H, 8.4 T |
推导
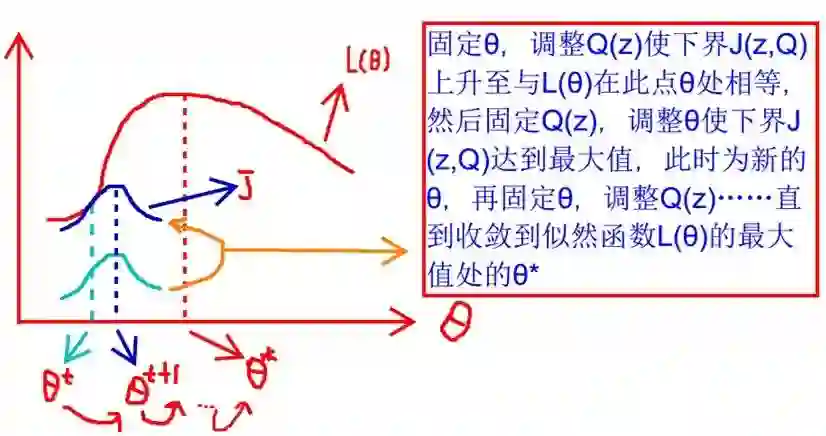
-
什么时候下界 与 相等? -
为什么一定会收敛?
另一种理解
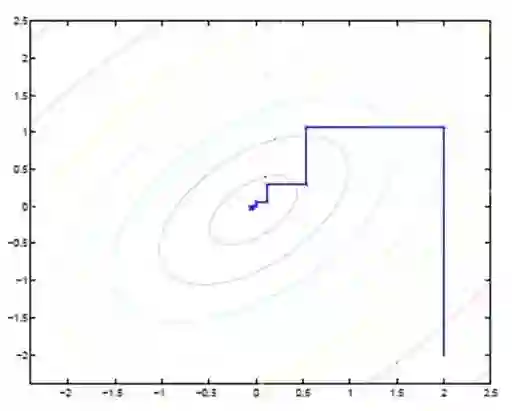
应用
参考
推荐阅读
T5 模型:NLP Text-to-Text 预训练模型超大规模探索
关于AINLP
AINLP 是一个有趣有AI的自然语言处理社区,专注于 AI、NLP、机器学习、深度学习、推荐算法等相关技术的分享,主题包括文本摘要、智能问答、聊天机器人、机器翻译、自动生成、知识图谱、预训练模型、推荐系统、计算广告、招聘信息、求职经验分享等,欢迎关注!加技术交流群请添加AINLP君微信(id:AINLP2),备注工作/研究方向+加群目的。

登录查看更多
相关内容


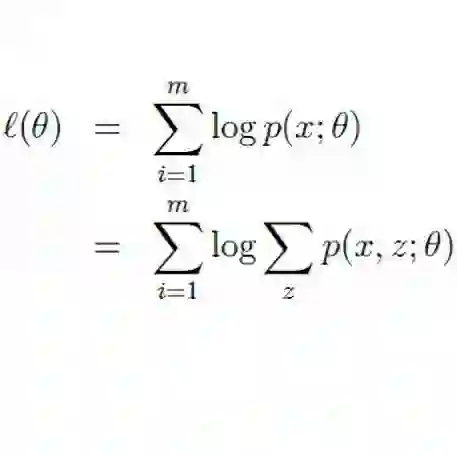

相关VIP内容
相关资讯
相关论文