ACL 2019 | 巧用文本语境信息:基于上下文感知的向量优化

「论文访谈间」是由 PaperWeekly 和中国中文信息学会社会媒体处理专委会(SMP)联合发起的论文报道栏目,旨在让国内优质论文得到更多关注和认可。


论文动机
作为典型的细粒度情感分析任务,目标-方面级别情感分析是自然语言处理领域的研究热点之一,结合注意力机制的深度网络模型在目标-方面级别情感分析任务中取得了令人瞩目的成功,但是仍存在一些待解决问题。
本文主要解决以下两个问题:
1. 现有的方法在表示目标(target)和方面(aspect)时往往会脱离上下文。这种随机初始化或不依赖于上下文的表示方法有三个弊端:1)同一个目标或方面的向量表示在表达不同情感极性的句子中没有得到区分;2)目标不是确定实体时(例如“这个酒店”,“这个餐馆”,“那部电影”等),输入信息无法体现实体本身的价值;3)忽略了目标和方面之间的相互联系。
2. 目标和方面在上下文中存在重叠的关联映射关系。在一句话中,一个目标可能会对应多个方面,而不同的方面可能会包含不同的情感极性。另一方面,在同一句话中往往会存在多个目标,所以目标和方面之间会存在错综复杂的对应关系。如图 1:

句子中的“location1”和“location2”是两个不同的目标,每一个目标会对应多个方面(Safety,Price,Transit 等),并且不同的方面可能会存在不同的情感极性。这里有一个有趣的现象,如果将“location1”和“location2”的位置交换,那么“location1”和“location2”所表达的方面和情感都会发生改变。所以,如何通过语境上下文精确推断目标和方面的相互关系以及文本对不同方面对象表达的情感是目标-方面级别情感分析任务的主要挑战之一。
方法
为解决上述问题,本文提出了一种结合上下文信息优化目标和方面向量表示的方法,该方法可以直接和现有基于神经网络的目标-方面级别情感分析模型相结合(如图 2 所示)。
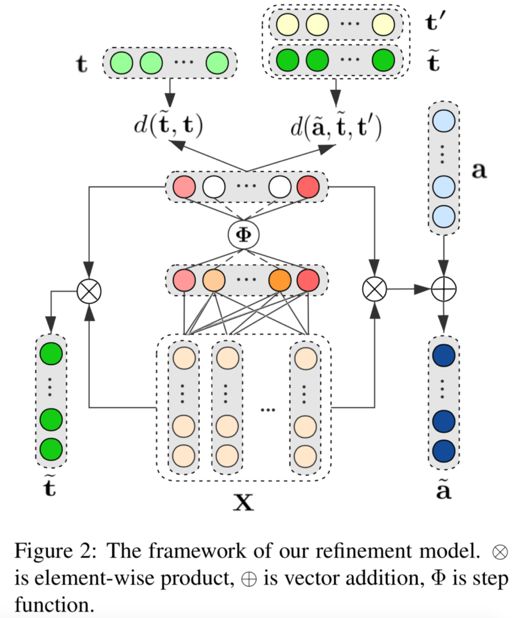
因为句子中的目标是任务的基础,然而考虑到同一个句子存在多个目标,如何针对不同目标从上下文中自动学习向量表示呢?
具体来说,我们使用一个稀疏系数向量来提取文本中与目标相关度较高的词语,并使用这些词语作为目标的上下文信息。通过对目标上下文词向量的聚合获得目标的最终表示。通过这种方法,目标的向量表示可以从上下文中自动学习,所以就算句子中的目标不是确定的实体,我们也能得到有价值的向量表示。
上下文感知的向量优化主要包含两个部分:重新构建目标向量和微调方面向量。为了使文本词向量里带有目标与方面信息,此处首先将文本的词向量序列输入一个全连接网络,之后利用一个阶跃函数将得到的文本向量稀疏化,以此表示文本中与目标相关的词语的掩码。最后通过将稀疏系数向量和输入的文本向量结合可以得到上下文相关的目标和方面表示。
在训练过程中,1)针对目标表示,我们希望获得的上下文相关目标向量尽量接近输入的目标向量,2)针对方面表示,我们希望上下文相关的方面表示尽可能靠近和它相关联的目标,远离无关的目标。
上下文相关的目标向量表示
为了使目标表示从上下文中自动生成,所以我们将提取上下文中和目标有高度关联的重要词语来优化目标向量表示:
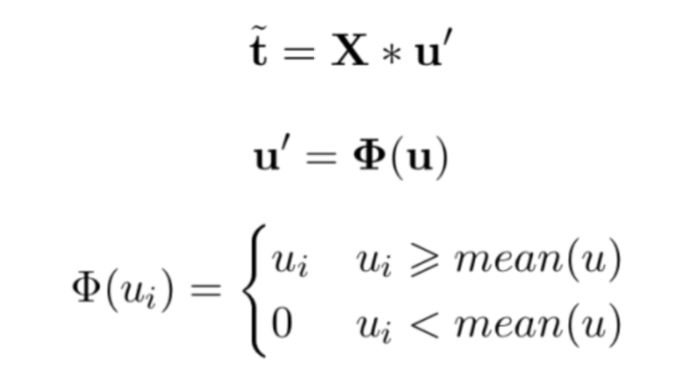
其中是优化后的目标向量表示,u' 是稀疏系数矩阵,Φ 是阶跃函数,mean(·) 代表取平均值。本文将通过最小化原始目标向量和优化目标向量来学习优化信息:
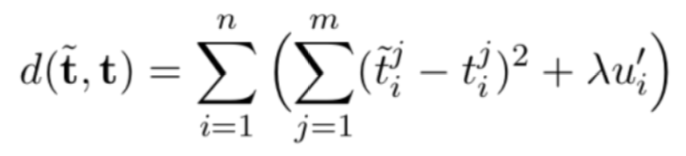
其中用来控制稀疏系数矩阵稀疏度。
上下文相关的方面向量表示
在方面向量表示优化中,因为方面本身的词语也具有一定的价值,例如方面“Price”,单从词语本身,我们可以知道该方面涉及“价格”相关信息,所以我们保留了方面的原始向量信息。通过将方面本身的词语和稀疏系数矩阵提取到的上下文信息结合可以得到优化后的方面向量表示:
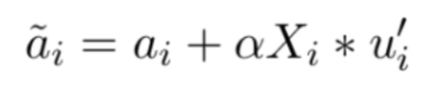
其中 α 用来控制上下文信息对优化向量的影响程度。
因为同一个句子中存在多个目标,而不同的目标又关联多个不同的方面,如何区分不同目标-方面之间的相互联系呢?为了解决该问题,对于每一个优化方面向量,我们不仅考虑它和对应目标之间的距离,同时也关注它和那些无关目标之间的距离,所以我们将目标函数分为了两部分:
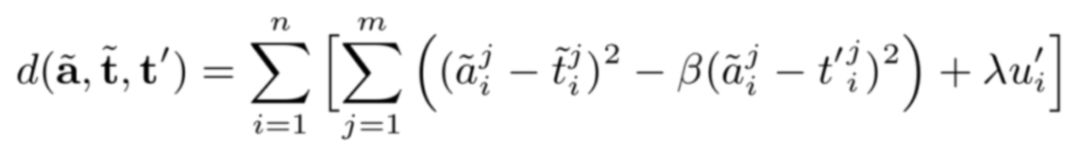
通过目标函数的两部分作用,可以使优化后的方面向量尽可能靠近与它相关联的目标,并远离与它无关的目标,从而使输入句子针对不同方面的情感信息得到有效区分。
实验结果
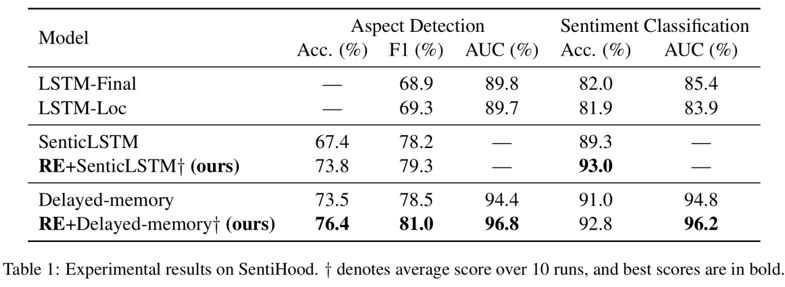
从表中结果可以看出,本文提出的优化目标和方面向量表示的方法在目标识别和情感分类任务中都取得了更好的表现,这说明了上下文相关的目标和方面表示能提升模型在细粒度情感分析任务中的效果。同时我们可以发现本文提出的目标-方面向量表示可以适用于大部分基于深度学习的目标-方面文本情感分类模型。
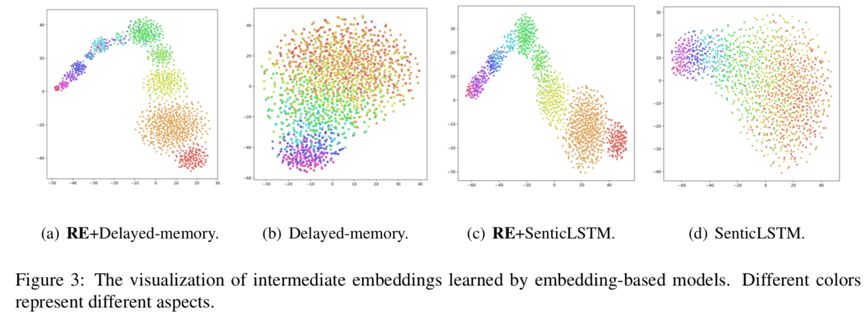
可视化部分,本文使用了 t-SNE 对模型学习到的方面向量表示中间结果进行可视化对比实验。从图 3 结果可以看出,本文提出的方法能使不同方面在训练过程中得到更好的区分,有效提升了方面向量表示的质量。
总结
本文提出了一种作用在细粒度情感分析的上下文感知目标和方面向量优化方法。实验结果表明,该向量优化方法可以直接和现有的基于神经网络的目标-方面级别情感分析模型相结合,并取得更好的效果。未来,我们尝试将向量优化方法应用到其他自然语言处理任务中,并进一步改善方法的有效性和通用性。
关于作者

梁斌,哈尔滨工业大学(深圳)计算机科学与技术学院博士研究生,主要研究方向为文本情感分析。

杜嘉晨,哈尔滨工业大学(深圳)计算机科学与技术学院博士生,研究方向为文本情感计算与文本生成。

徐睿峰,哈尔滨工业大学(深圳)计算机科学与技术学院教授,研究方向为自然语言处理、情感计算、人机接口。
主办单位



🔍
现在,在「知乎」也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」订阅我们的专栏吧
关于PaperWeekly
PaperWeekly 是一个推荐、解读、讨论、报道人工智能前沿论文成果的学术平台。如果你研究或从事 AI 领域,欢迎在公众号后台点击「交流群」,小助手将把你带入 PaperWeekly 的交流群里。

▽ 点击 | 阅读原文 | 下载论文




