WSDM2022 | DualDE:基于知识图谱蒸馏的低成本推理


论文题目:DualDE: Dually Distilling Knowledge Graph Embedding for Faster and Cheaper Reasoning
本文作者:朱渝珊(浙江大学)、张文(浙江大学)、陈名杨(浙江大学)、陈辉(阿里巴巴),程旭(北京大学),张伟(阿里巴巴),陈华钧(浙江大学)
发表会议:WSDM 2022
论文链接:https://www.zhuanzhi.ai/paper/12c6a095c207373b5e207d3375290234
欢迎转载,转载请注明出处
背景
知识图谱(Knowledge Graph)由以表示事实的三元组形式(头实体,关系,尾实体)组成,可简写为(h,r,t)。知识图谱已被证明可用于各种AI任务,如语义搜索,信息提取和问答等。然而众所周知,知识图谱还远非完备,这进而也促进了许多关于知识图谱完备性的研究。其中比较常见且广泛使用的方法是知识图谱嵌入(KGE Knowledge Graph Embedding),如TransE、ComplEx和RotatE等。同时,为了获得更好的性能,通常首选训练具有更高维度的KGE。
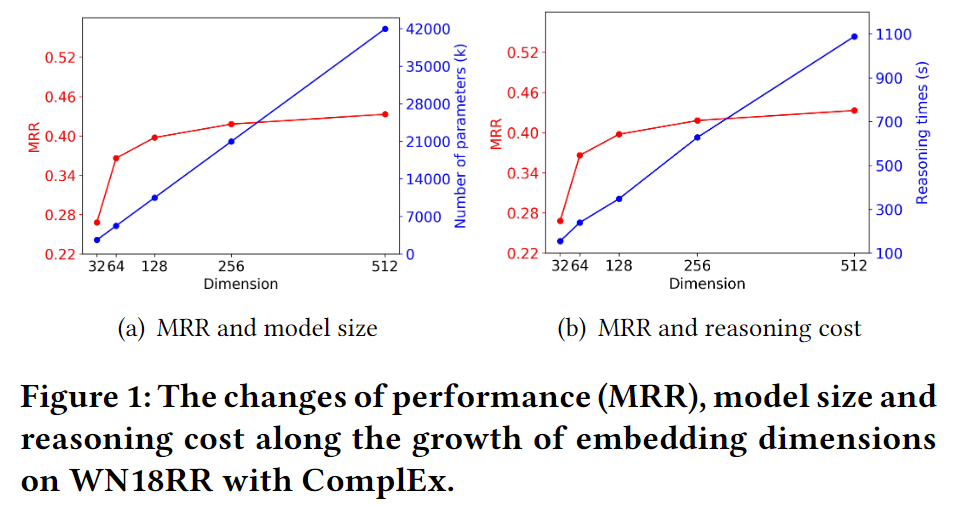
图 1
但是模型大小(参数的数量)以及推理时间的成本通常随embedding维度的增加而快速增加,如图1所示:随着embedding维度的增大,性能增益越来越小,而模型大小和推理成本却仍几乎保持线性增长。此外,高维KGE在许多现实场景中是不切实际的,尤其是对于计算资源有限或者是在推理时间有限的应用中,低维的KGE是必不可少的。然而,直接训练一个小尺寸KGE通常表现不佳,我们进一步提出一个新的研究问题:是否有可能从预训练的高维KGE中获得低维KGE,在更快成本更低的情况下取得良好的效果。
知识蒸馏是一种广泛使用的技术,用于从大模型(教师模型)中学习知识以构建较小的模型(学生模型)。学生从真实标签和老师模型中的软标签这二者中学习。在本项工作中,我们提出了一种名为DualDE的新型KGE蒸馏方法,该方法能够将高维KGE蒸馏提取出较小的嵌入尺寸,而精度损失很小或没有损失。在DualDE中,我们考虑了老师和学生之间的双重影响:(1)教师对学生的影响(2)学生对教师的影响。
在老师对学生的影响方面,众所周知,老师模型输出的软标签会对学生产生影响。虽然在之前的许多蒸馏工作中,所有样本都具有相同的硬标签和软标签权重,但它们并没有从老师模型那里区分不同样本的软标签的质量的能力。事实上,KGE方法对不同三元组的掌握程度是不同的。对于一些难以被KGE方法掌握三元组,他们通常难以获得可靠的分数。让学生按照不可靠的分数模仿老师,会给学生模型带来负面影响。为了获得更好的蒸馏效果,我们建议学生应该能够评估老师提供的软标签的质量并且有选择地向他们学习,而非一视同仁地学习。我们在DualDE中引入了软标签评估机制来评估老师提供地软标签质量,并自适应地为不同地三元组分配不同的软标签和硬标签权重,这将保留高质量软标签的积极作用并避免低质量软标签的负面影响。
在学生对老师的影响方面,以前的工作研究得并不充分。已有工作证明了蒸馏的整体表现还取决于学生对老师得接受程度。我们希望根据学生目前的学习情况不断调整老师,让老师更能被学生接受,提高最终的提炼效果。因此,我们在DualDE中提出了一种两阶段的蒸馏方法,通过根据学生的输出调整教师来提高学生对教师的接受度。其基本思想是,尽管预训练的老师已经很强了,但对于现在的学生来说,可能不是最适合的。还有相关工作指出,与学生具有相似输出分布的教师更有利于学生的学习。因此,除了教师始终保持静止的标准蒸馏阶段外,我们还设计了第二阶段蒸馏,其中教师解冻并尝试反向向学生学习,以使其更容易被学生接受。
我们使用几个典型的KGE方法和标准KG数据集评估DualDE。结果证明了我们方法的有效性。本文的贡献有三方面:
-
我们提出了一种新颖的框架,能从高维KGE中提取低维KGE,并取得良好的性能。 -
我们在蒸馏过程中考虑了教师和学生之间的双重影响,并提出了软标签评估机制来区分不同三元组的软标签的质量和两阶段蒸馏以提高学生对老师的适应性。 -
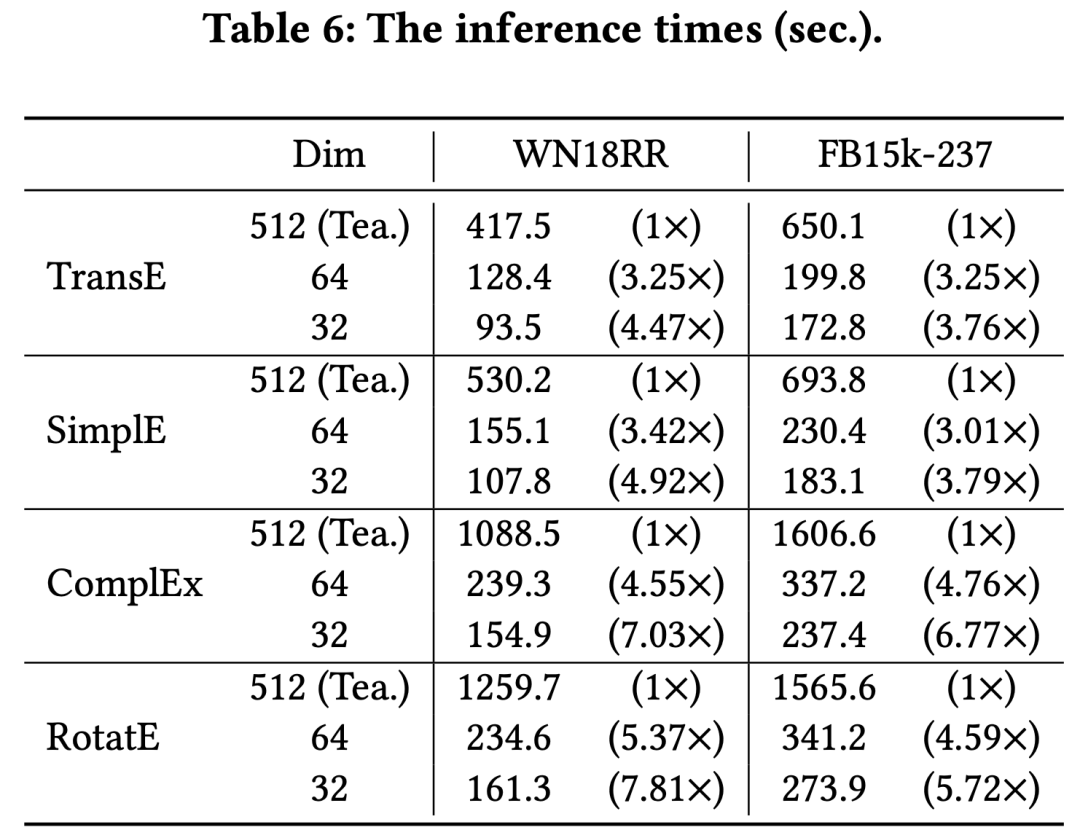
我们通过实验证明,我们的方案可以在很少的性能损失基础上,将高维KGE的嵌入参数减少7-15 倍,并将推理速度提高约 2-6 倍。
方法
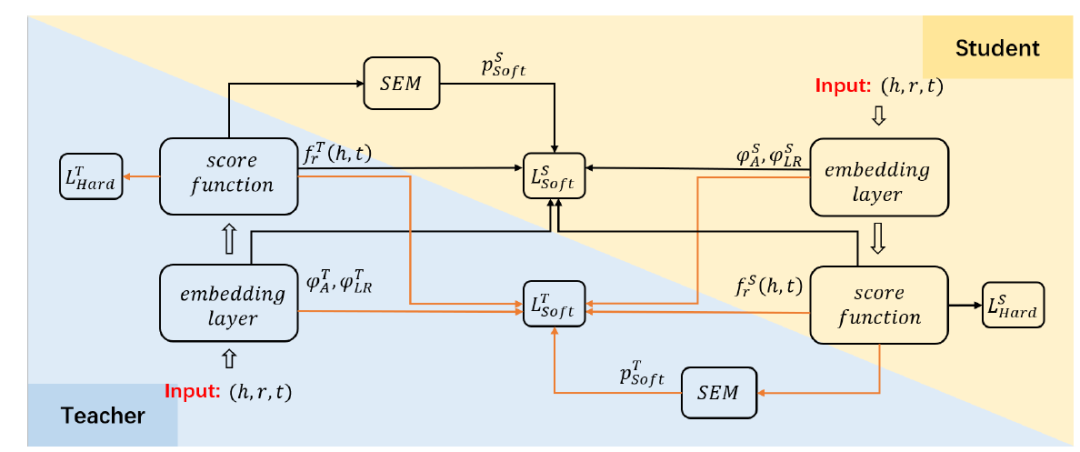
图 2
蒸馏目标
软标签评估机制可评估教师提供的软标签的质量,并自适应地为不同的三元组分配不同的软标签和硬标签权重,从而保留高质量软标签的积极作用,避免低质量软标签的负面影响。
理论上,KGE模型会给正三元组更高的分数,给负三元组更低的分数,但对于一些KGE模型难以掌握的三元组则相反。具体来说,如果教师给一个负(正)三元组打高(低)分,这意味着教师倾向于将其判断为正(负)三元组,那么教师输出的这个三元组的软标签是不可靠的,甚至会误导学生。对于这个三元组,我们需要削弱软标签的权重,鼓励学生更多地从硬标签中学习。
上一部分介绍了如何让学生从 KGE 教师那里提取知识,其中学生用硬标签训练,软标签由固定教师生成。为了获得更好的学生,我们提出了一种两阶段蒸馏方法,通过解冻教师并让其在蒸馏的第二阶段向学生学习来提高学生对教师的接受度。(1)第一阶段。第一阶段类似于传统的知识蒸馏方法,其中教师在培训学生时保持不变;(2)第二阶段。在第二阶段调整教师的同时,对于那些学生没有掌握好的三元组,我们也希望减少学生的输出对教师的负面影响,让教师更多从硬标签中学习,从而以保持教师的高准确性。因此,我们也将软标签评估机制应用于教师的调整。通过评估学生给每个三元组的分数,教师的硬标签和软标签的权重被自适应分配。在此阶段,教师和学生一起优化。
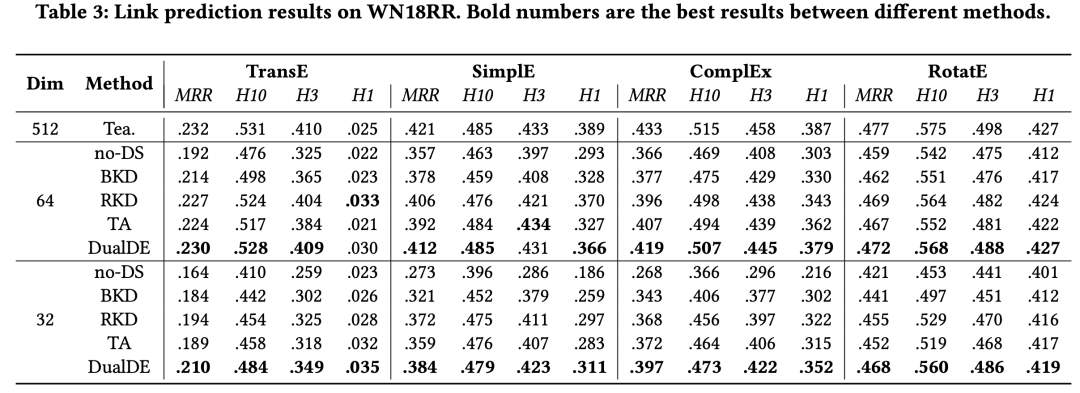
实验结果
专知便捷查看
便捷下载,请关注专知公众号(点击上方蓝色专知关注)
后台回复“DUDE” 就可以获取《WSDM2022 | DualDE:基于知识图谱蒸馏的低成本推理》专知下载链接







