论文浅尝 | MulDE:面向低维知识图嵌入的多教师知识蒸馏
笔记整理:朱渝珊,浙江大学在读博士,研究方向为快速知识图谱的表示学习,多模态知识图谱。

Motivation
为了更高的精度,现有的KGE方法都会采用较高的embedding维度,但是高维KGE需要巨大的训练成本和存储空间。现在一般有两种方法解决这一问题,第一种是直接训练低维的KGE(例如8维或32维),但是这种方式的缺陷是不能利用高维KGE中高精度知识;另一种解决方法是将预训练的高维KGE压缩到较低的维度,这种方法的缺点是很高的预训练成本,并且在KG变化时不能继续训练。
那么,我们能否在避免训练高维模型的同时,将高精度的知识转移到低维模型中?本文提出了一种新的面向低维知识图嵌入的多教师知识蒸馏方法MulDE来解决这个问题。选择使用多个低维度(64维)教师有以下3个好处:
1.降低预训练成本;2.能保证教师的性能;3.提升蒸馏效果。
方法
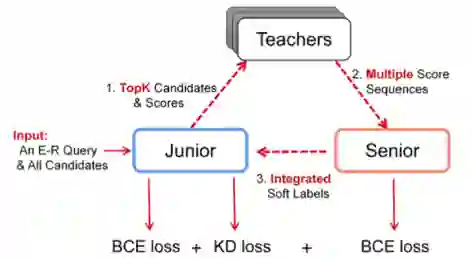
整个模型框架分为3个部分:
Junior:目标模型。它会挑选分数较高的K个候选实体,并把这些实体及它们的得分送到Teachers。
Teachers:一个Teacher团队,针对Junior挑选的K个实体,生成多个分数序列。在整个训练过程中,Teachers不会更新。
Senior:它将Teachers的多个评分序列整合为最终的软标签,然后返回给Junior。
Junior:
目标模型。它会挑选分数较高的K个候选实体,并把这些实体及它们的得分送到Teachers。
具体来说,给定一个e-r查询,Junior会评估整个实体集中的所有实体的得分,最后选择出得分最高的前K个实体:
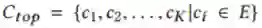
它们的得分表示为:
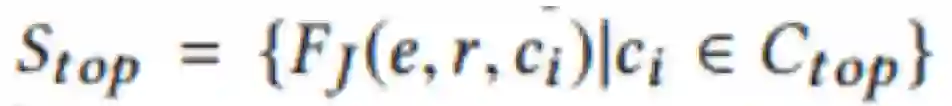
这K个实体以及它们的得分会被输出到Teachers中,Senior会基于Teachers的输出给出Junior训练的soft label。因此,Junior的soft label损失可以表示为:
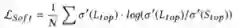
另外,Junior还受到ground-truth标签(即hard label)的监督,Junior的hard label损失可以表示为:
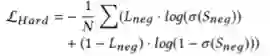
Junior的最终损失为soft label损失和hard label损失的和:
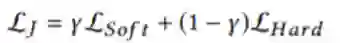
Teachers:
一个Teacher团队,针对Junior挑选的K个实体,生成多个分数序列。在整个训练过程中,Teachers不会更新。假设有m个Teacher,则Teachers表示为:
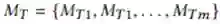
本文作者选择了以下4个模型组成Teachers:
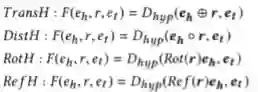
Teachers输出m个分数序列:
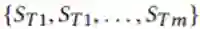
每个序列的长度为K,对应于从Junior接收的K个候选实体。
Senior:
它将Teachers的多个评分序列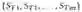
A. 关系特定的放缩机制
考虑到一个Teacher对不同的关系有不同的关注度,每个Teacher都有自己擅长的关系,作者设置了一个关系矩阵:
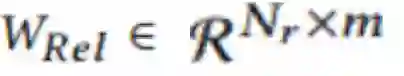
这个矩阵行代表不同的关系,列代表不同的Teacher。每个Teacher的分数序列都会通过这个关系矩阵进行放缩:
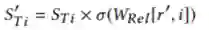
而这个关系矩阵的优化也是通过真实one-hot标签进行监督:
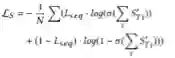
B. 对比注意机制
这个机制的提出是考虑到,Teachers是预训练好的,而Junior是随机初始化的,Senior通过整合Teachers输出的分数序列得到的soft label可能和Junior的输出差距过大,不利于训练收敛。因此希望在训练的初始阶段,Senior生成的soft label能比较接近Junior的输出。Senior会对比和评价Junior输出序列和每个教师序列之间的相似性:
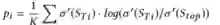
而相似度更高的Teacher分数序列会在整合过程中拥有更高的权重:
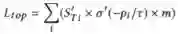
而随着训练时间t的增加,这个权重的影响逐渐减小,各Teacher的贡献趋于相同。
整个模型的算法流程如下:

实验
作者在两个数据集WN18RR和FB15K-237上进行了实验,对比了不同高维和低维KGE模型。实验结果如下:
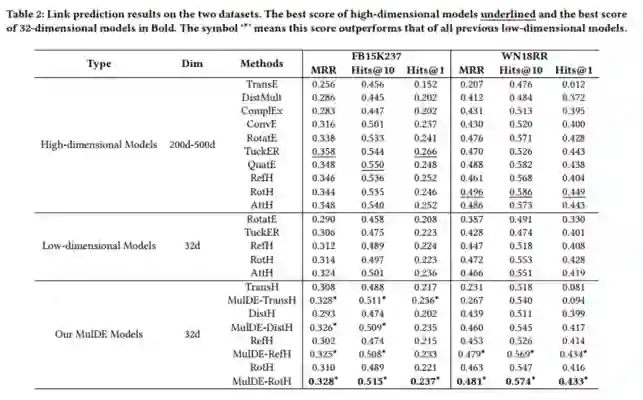
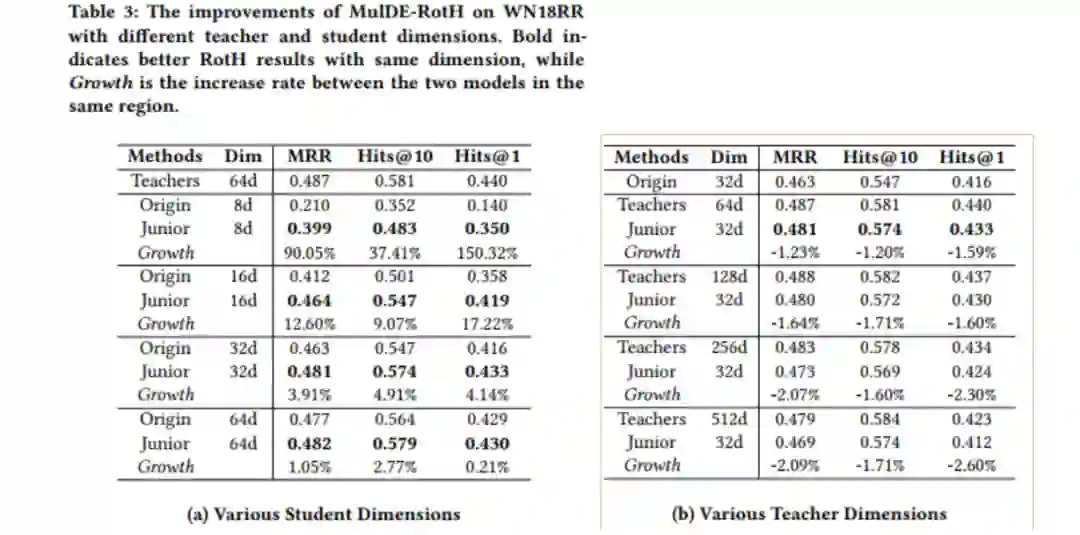
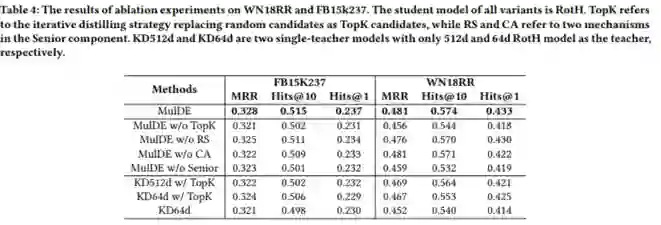
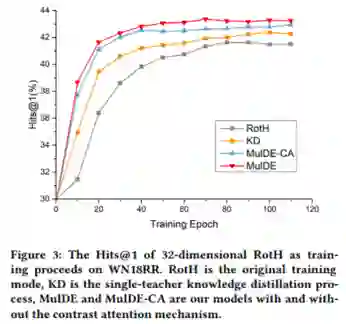
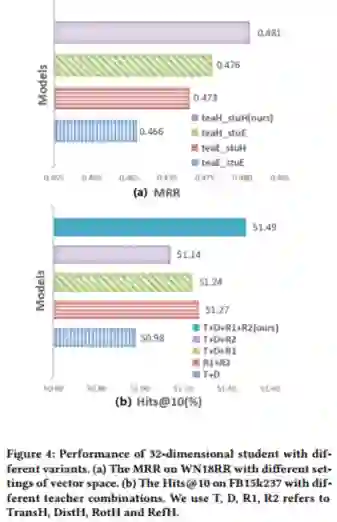
从实验结果中可以看出MulDE相较于现有的KGE方法在链接预测上有明显提升,并且有较快的训练速度。
欢迎有兴趣的同学阅读原文。
OpenKG
OpenKG(中文开放知识图谱)旨在推动以中文为核心的知识图谱数据的开放、互联及众包,并促进知识图谱算法、工具及平台的开源开放。

点击阅读原文,进入 OpenKG 网站。


