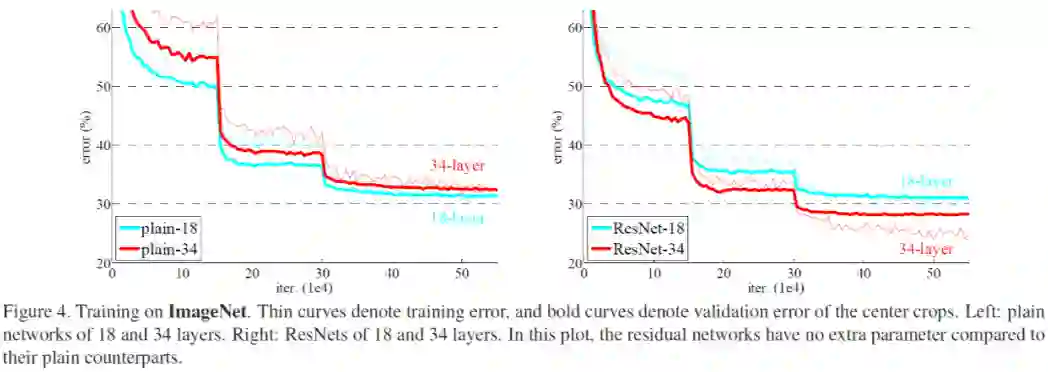
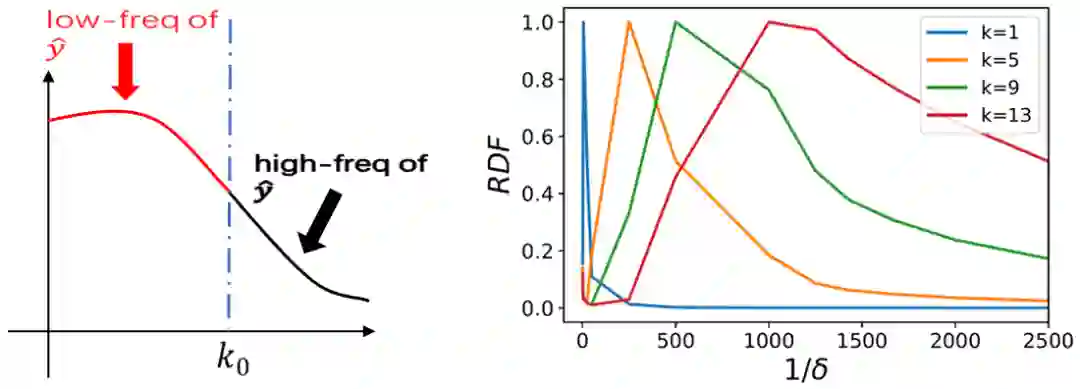
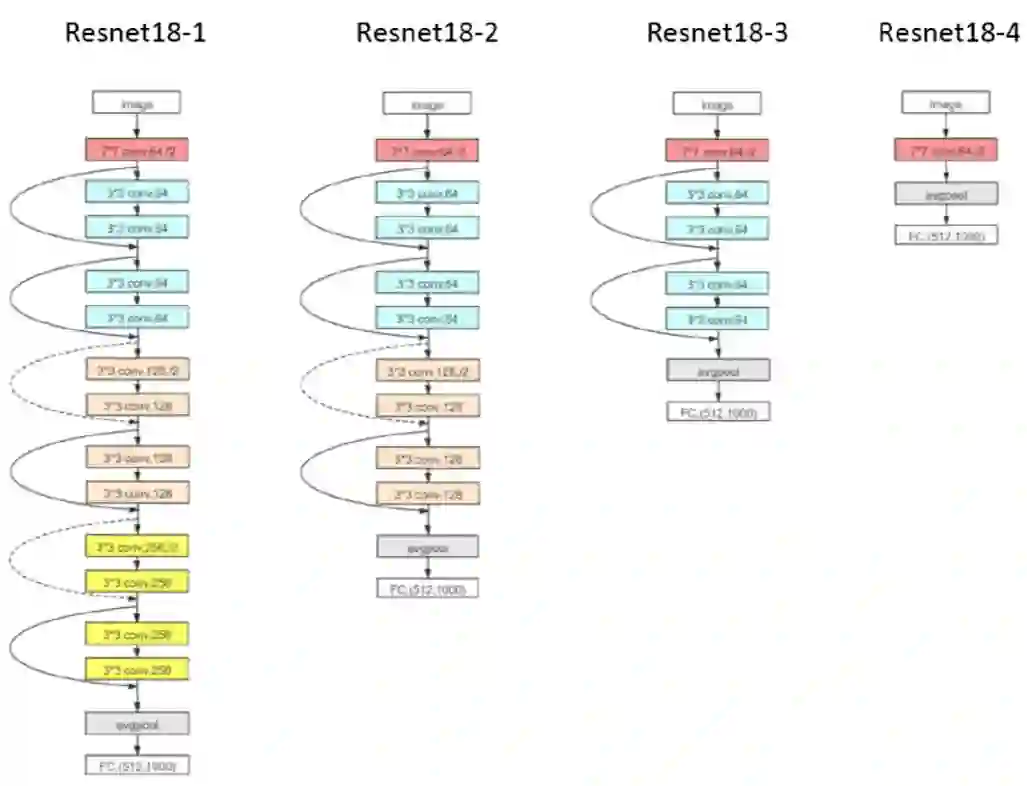
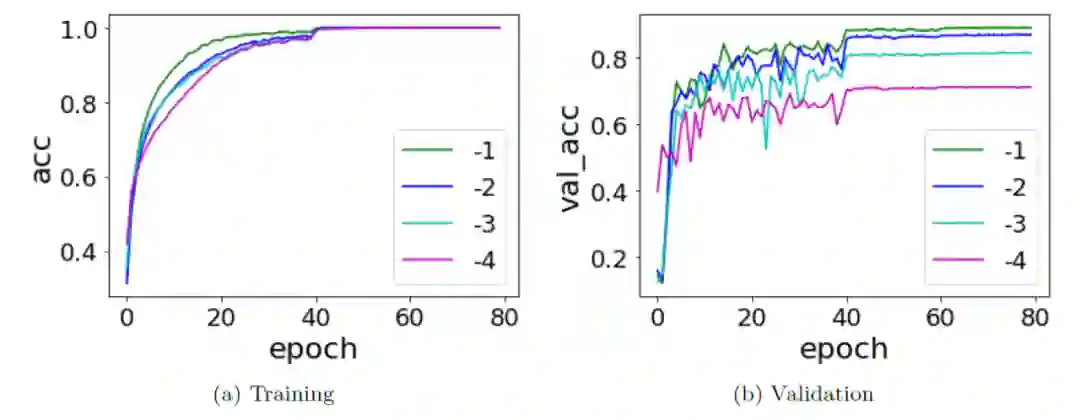
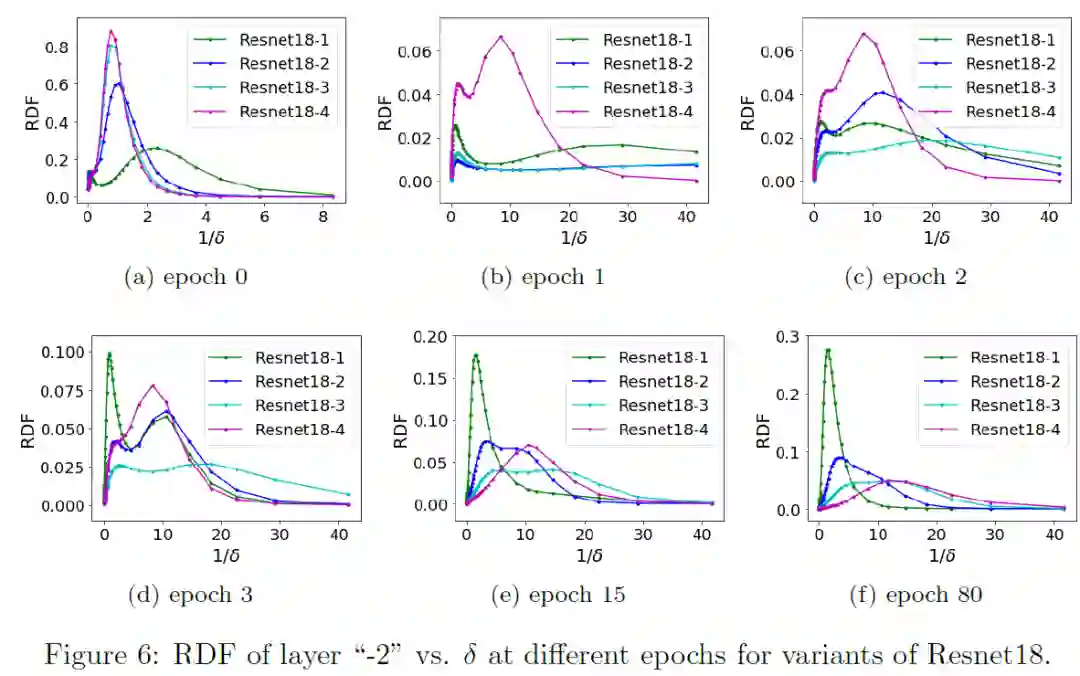
观察其 learning component 的等效目标函数的 RDF,我们发现,拥有更多隐藏层(也就是网络更深)的神经网络其 learning component 相比浅网络会更趋于低频,并最后保持在更加低频处。我们得到了 Deep Frequency Principle——更深层神经网络的有效目标函数在训练的过程中会更趋近于低频。 再基于 F-principle——低频先收敛,我们就能够得到更深层的神经网络收敛得更快的结果。尽管频率是一个相对可以定量和容易分析的量,但当前实验跨越了多个不同结构的网络,也会给未来理论分析造成困难。因此,我们后面研究单个神经网络中的 Deep Frequency Principle。
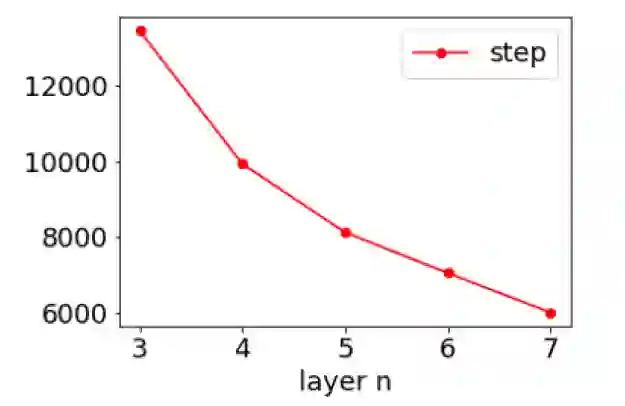
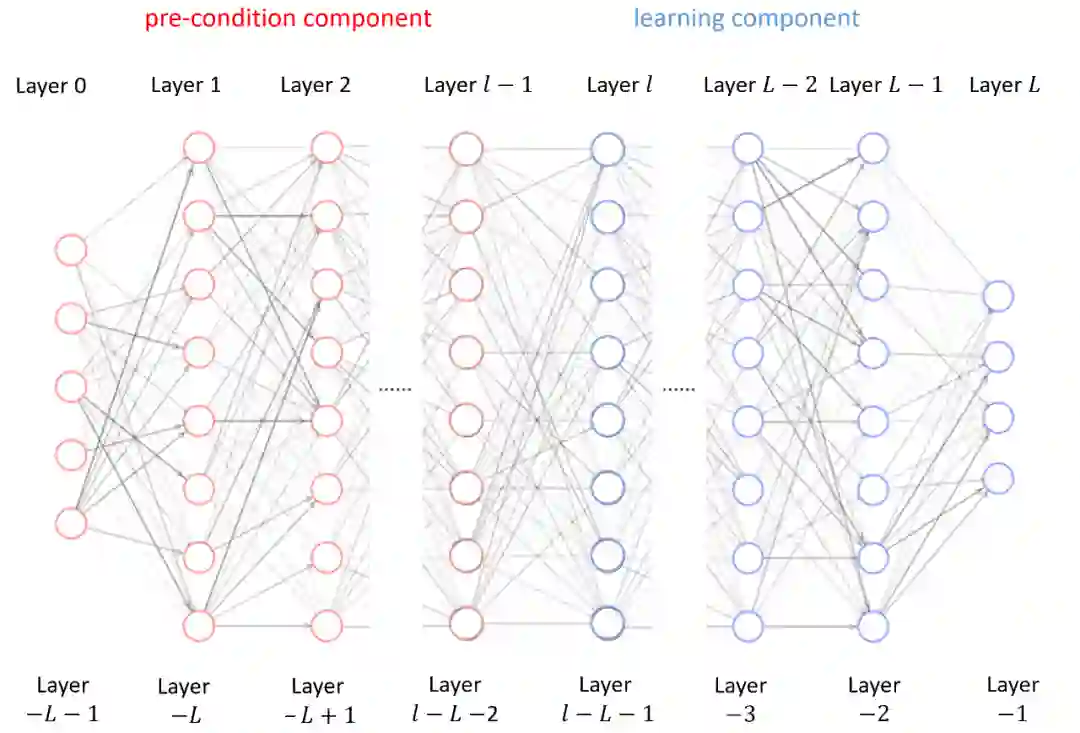
于是,我们探究同一个深度神经网络内不同隐藏层的等效目标函数的 RDF,即改变 pre-condition 和 learning component 的层数(但保持网络的结构和总层数不变)。这个实验是在 MNIST 上的,深度神经网络(DNN),并取了 5 个相同大小的隐藏层。 在下图中,我们发现,虽然初始时神经网络更深层的等效目标函数的 RDF 聚集于较高频处,但随着训练,更深层的 RDF 会快速地趋于更低频的地方,并保持在低频处。这也是 Deep Frequency Principle——更深层的神经网络的有效目标函数会在训练的过程中会更趋近于低频。在该工作中,基于傅里叶分析以及对 F-principle 的理解,我们给出了一个新的角度来处理和看待多层、深层的前馈神经网络,即通过分成 pre-condition component 和 learning component 两个部分,研究 learning component 的等效目标函数的 RDF,得到 Deep frequency principle,并最终提供了一种可能的角度来解释为何多层的网络能够训练得更快!相信这个工作会为未来的理论分析提供重要的实验基础。关于作者:周瀚旭,许志钦 上海交通大学联系:xuzhiqin@sjtu.edu.cnhttps://ins.sjtu.edu.cn/people/xuzhiqin/
参考文献
[1] Deep frequency principle towards understanding why deeper learning is faster. Zhi-Qin John Xu and Hanxu Zhou, arXiv: 2007.14313. (to apear in AAAI-2021)
[2] Zhi-Qin John Xu; Yaoyu Zhang; Tao Luo; Yanyang Xiao, Zheng Ma , ‘Frequency principle: Fourier analysis sheds light on deep neural networks’, arXiv:1901.06523. (2020, CiCP)
[3] Zhi-Qin John Xu; Yaoyu Zhang; Yanyang Xiao, Training behavior of deep neural network in frequency domain, arXiv preprint arXiv: 1807.01251. International Conference on Neural Information Processing.