唐杉博士:人工智能芯片发展及挑战

分享嘉宾:唐杉博士 壁仞科技
编辑整理:许浩 西安邮电大学
出品平台:DataFunTalk
导读:本文来自DataFunSummit:AI基础软件架构峰会上唐杉博士的分享。将讨论人工智能芯片的架构特征、发展趋势、以及AI DSA架构给AI软件栈带来的挑战。主要内容包括:
Al DSA产生的背景和产业现状
百花齐放的Al DSA硬件
Al DSA软件栈面临的挑战
先看一下Al DSA产生的背景。
1. 人工智能的发展以及背后的算力支撑
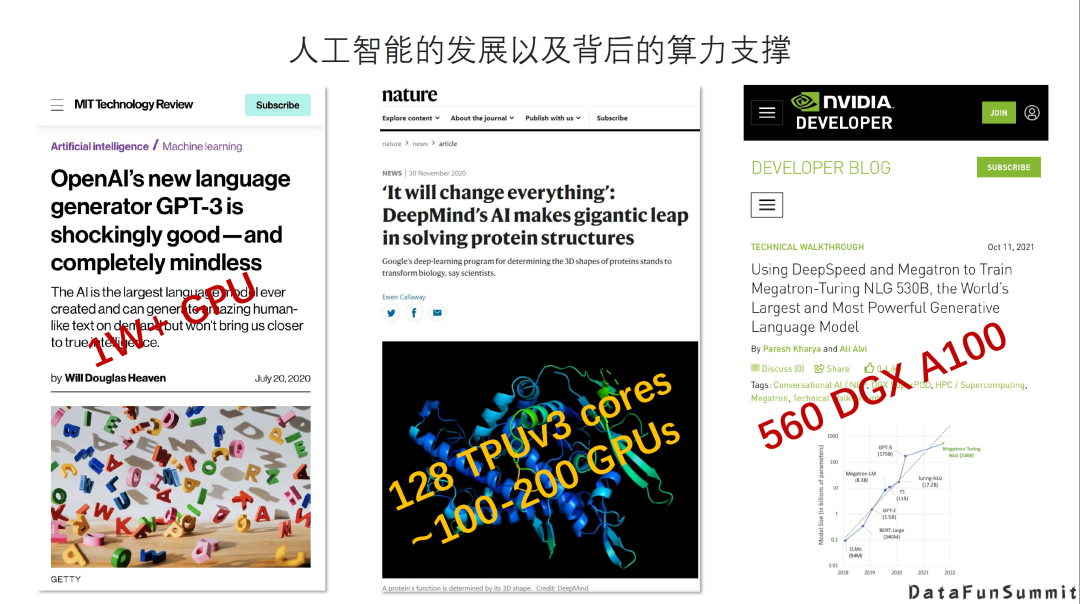
我们看到近几年取得非常惊人效果的AI模型,比如GPT-3、AlphaFold等,其实背后都用了大量的的GPU芯片来作为训练的平台。像最右侧英伟达和微软合作训练的530B参数的模型使用了560个DGX A100平台。这些芯片提供的算力为人工智能的发展提供了巨大的支撑。
2. Al DSA产生的背景
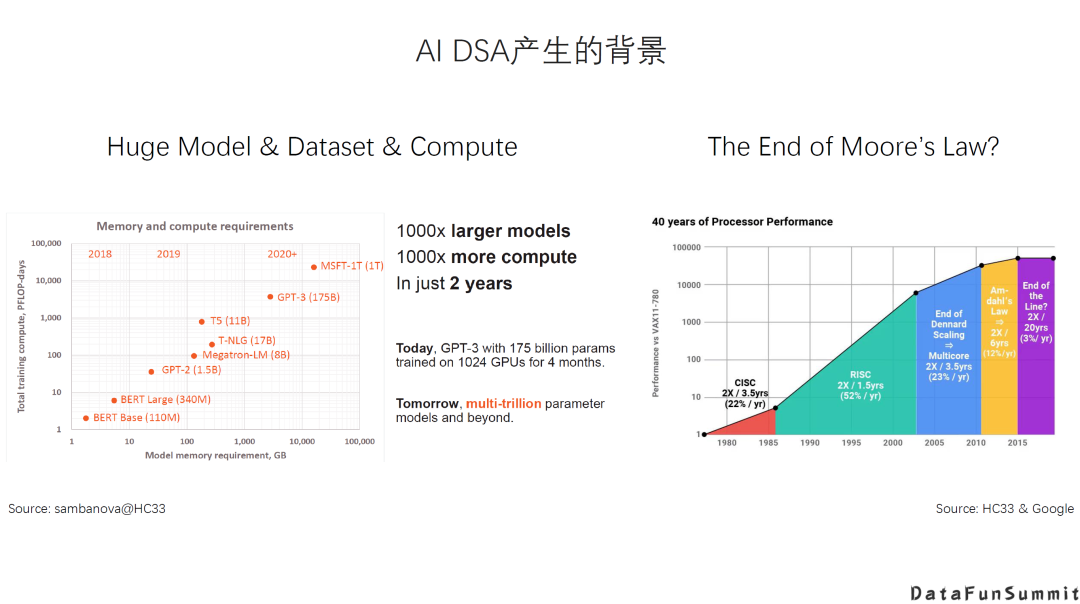

随着AI应用和算法的发展以及落地场景越来越复杂,出现了以下两点问题:
不论是模型的规模还是算力需求,都是呈指数形式的增长。同时,由于摩尔定律放缓,通用处理器的性能提升已经十分有限。因此,计算需求与处理能力的提升之间存在较大的GAP。
第二,AI计算现在无处不在,AI计算任务多样且复杂。例如,在云上、边缘侧与端设备上,不同的场景下面包括不同的训练和推理的需求,差异是非常大的。在云上进行训练,可能需要非常高的吞吐量,非常高的精度,以及非常强的扩展性等等;而在端上,情况更加复杂,会有计算量需求巨大的情况,如自动驾驶可能需要P级算力;同时,也会有能耗和成本非常受限的应用,像可穿戴设备中的AI计算等等。
总之,不管是对巨型模型的支持,还是碎片化的需求,都和通用处理器提供的处理能力之间有很大的GAP,所以近几年我们针对AI提出很多专用的架构(DSA)。
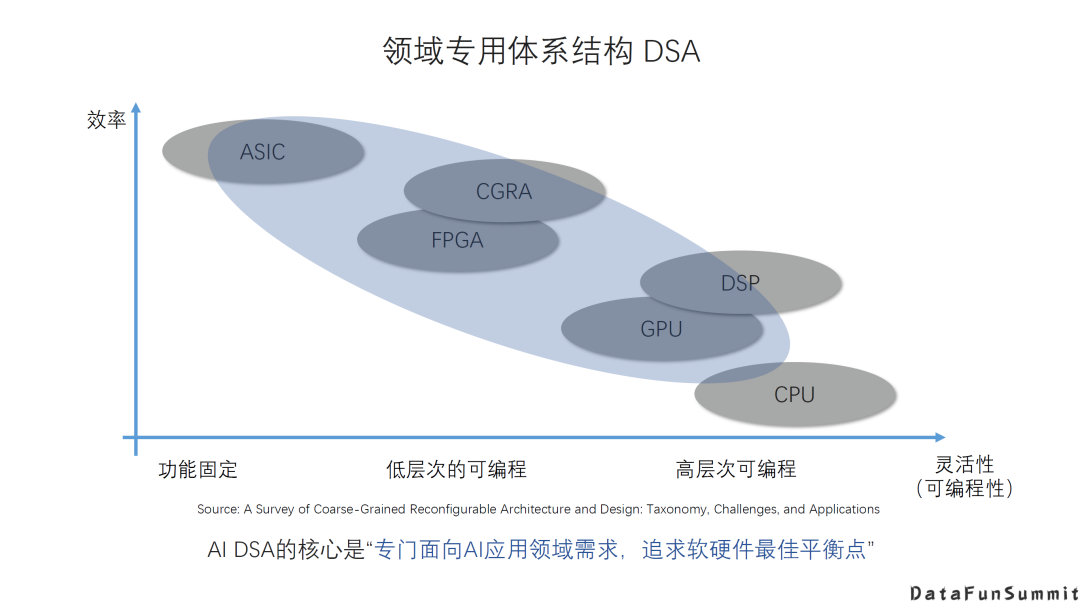
近几年,“领域专用架构DSA”被不断提起,它其实也不是一个新的概念。我们看图中这些最常见的芯片架构,除了CPU是一个通用架构之外,实际上其它的都可以认为是一个领域专用的架构,也就是为了效率和灵活性上找一个最优点而针对某一个领域或者某一类应用而设计的架构。
那么针对Al的AI DSA,它的核心就是“专门面向Al应用领域需求,追求软硬件最佳平衡点”。然而由于AI应用场景非常复杂,目前大家还是在使用用各种各样的架构来加速AI应用,还没有形成一个或几个稳定的平衡点。
3. Al DSA的分类
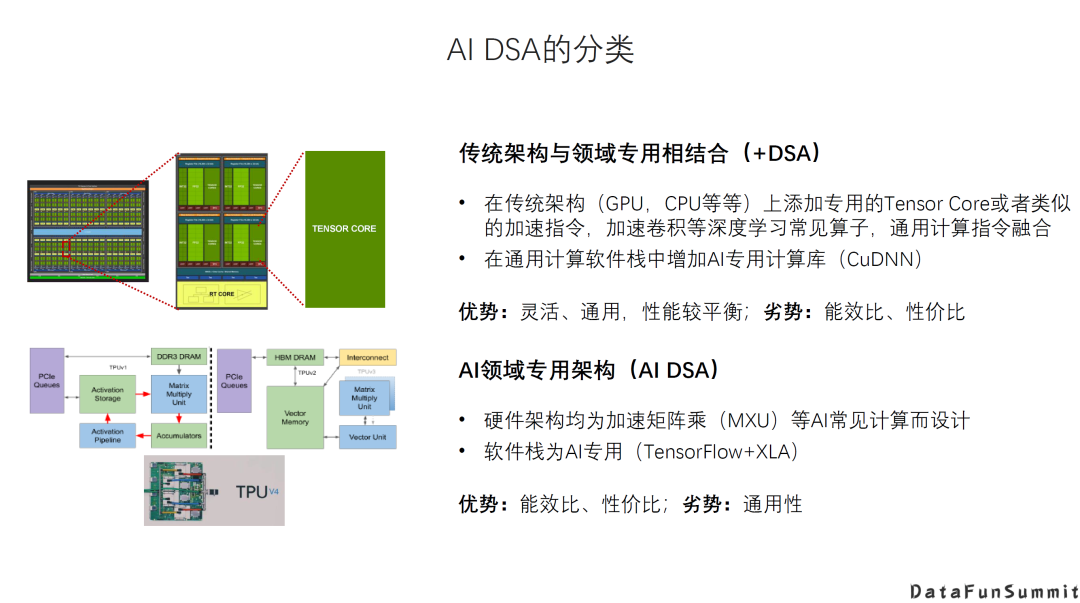
对Al DSA的分类可以有很多不同的方式,一种大的分类方法是从基础架构来看:
传统架构+DSA。在传统架构的基础上增加新的DSA的硬件以及相应的指令。例如GPU增加Tensor Core这种专用的加速器。它的优势是灵活通用,性能比较平衡,而劣势是相对更专用的DSA在特定应用场景下的能效比、性价比。
Al领域专用架构,即针对AI的新架构。例如Google TPU,它的设计是专门针对有限的AI应用场景,牺牲一定的通用性和灵活性来换取更高的能效或者性价比。
当然不同的架构选择其实都是针对不同的应用场景特点所作的tradeoff。
下面我们回顾一下近几年各种很有特色的Al DSA的设计。
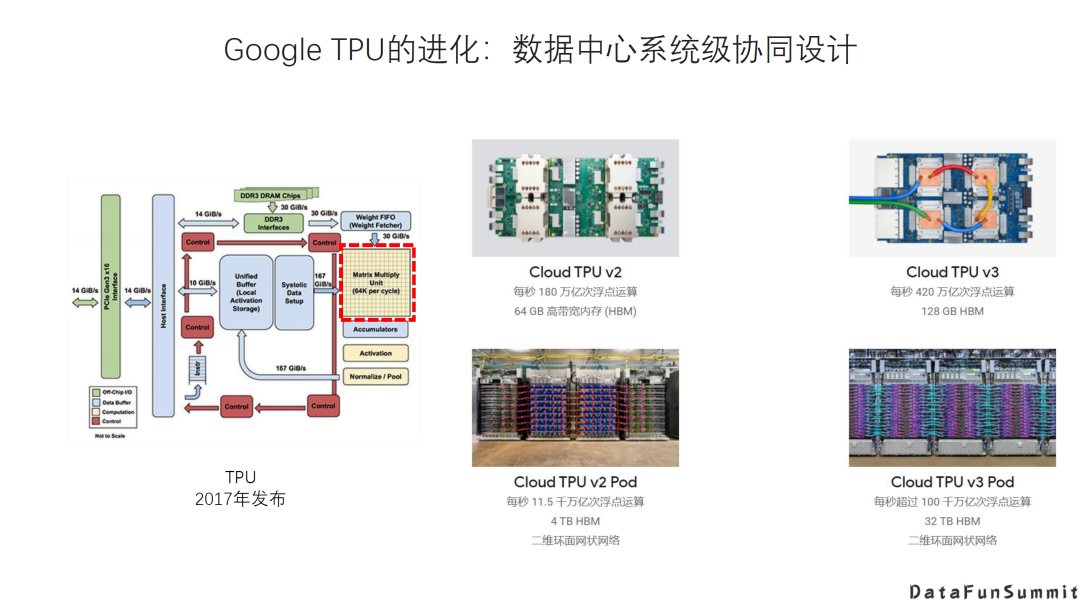
Google的TPU:于2017年正式发布,可以说在当时掀起了我们这几年AI芯片的热潮,到现在已经发布了四代。其实是一个相对来说是个比较专用的设计,围绕一个比较大的脉动阵列展开,其设计思路主要强调面向AI的数据中心系统级协同设计的方法,也就是说它的芯片是原生服务于整个的数据中心的系统,做了很多互联,扩展,散热等系统方面的优化。
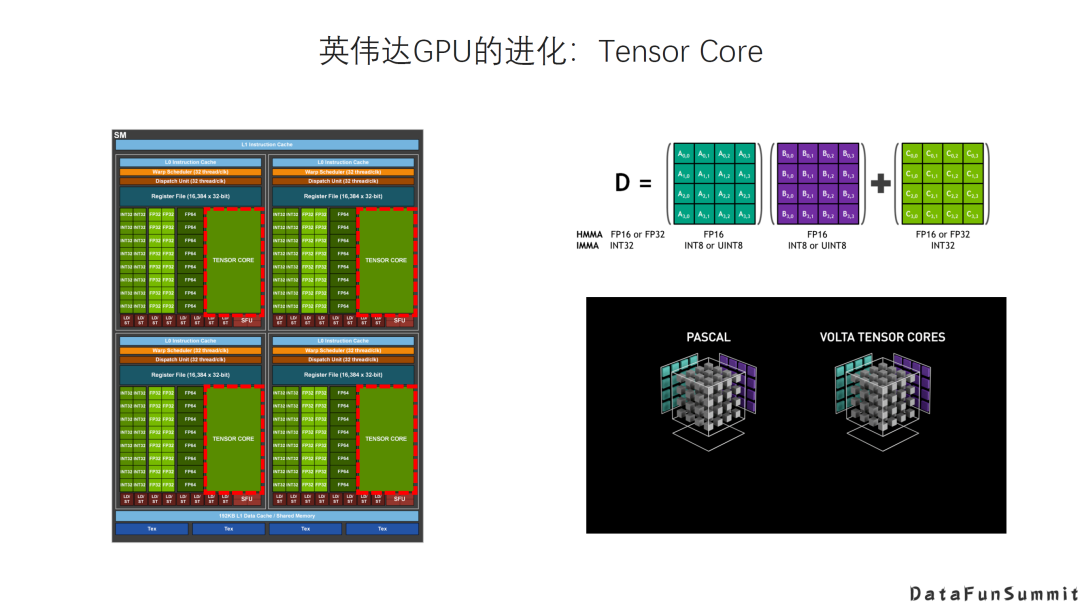
英伟达的GPU:增加Tensor Core和相应指令,大大提升了AI的矩阵运算的效率。
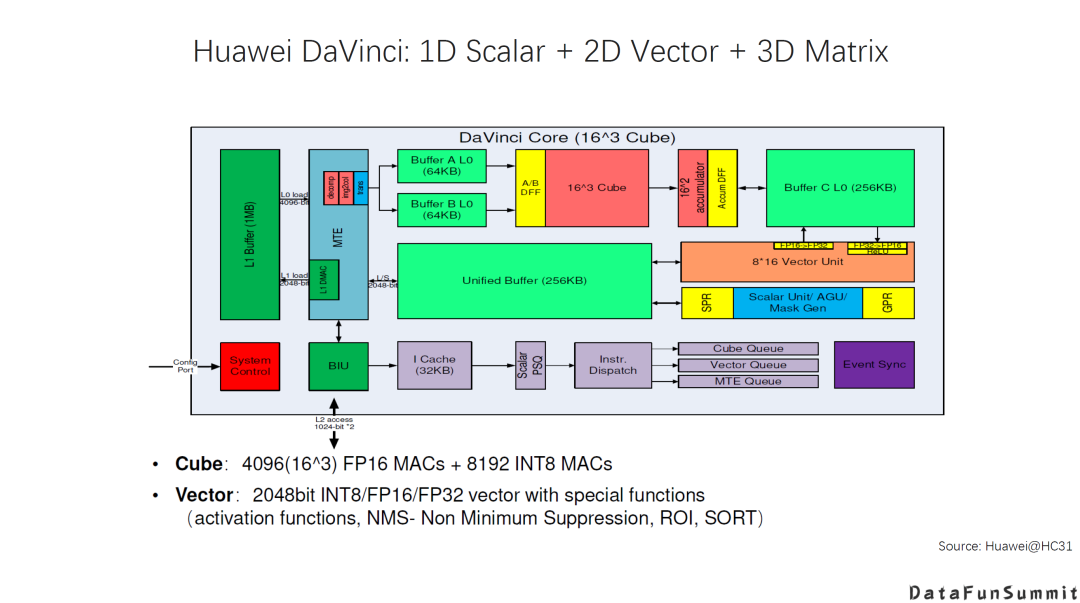
华为的DaVinci架构:这是一个比较典型的Al DSA架构,它从一维的Scalar到二维的vector再到三维Matrix,都有专用硬件加速引擎,同时也有相应的Memory的Hierarchy,包括各种Buffer,也是AI的专用加速器常见的一种设计选择。

Device Soc也加入了Al DSA的设计:2017年的时候华为旗舰智能手机芯片开始加入了NPU,苹果也加入了Neural Engine,到现在都发展了好几代,而且AI加速在芯片的SOC里面占的分量也是越来越重。

还有一个很典型的Al DSA场景就是自动驾驶芯片:这个是2019年特斯拉发布的FSD,可以看到在它的芯片里面,NPU这一部分也是占了相当大的面积。
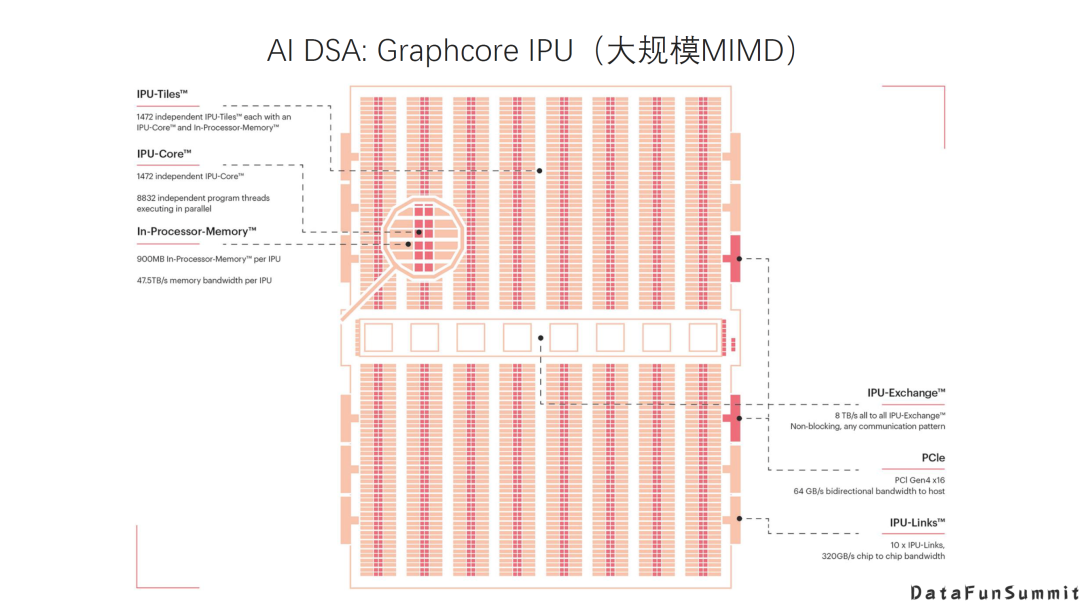
近几年还看到很多创新的AI DSA的架构:
例如Graphcore IPU,它是一个非常大规模的规模的的MIMD多核系统。它在设计里面另一个比较大的创新就是实现了非常大的片上SRAM。另外它的多核互联,多核同步机制也有很多有意思的设计。

另外一个是Cerebras晶圆级芯片,一个芯片就是用整个晶圆来实现的,比普通的芯片面积要大得多,可以在一个芯片内实现更大规模的算力。当然相应的也会有很多挑战在里面,硬件的挑战,系统的挑战。Cerebras的WSE是算力提升的一个思路,也做了大量工程上的创新,非常值得关注。

此外,Cerebras除了大规模的芯片和相应的CS-2的硬件系统之外,还提供了专用的互联和存储设备,目标是支持一个120T参数级别的神经网络的模型。其实我们现在看到的参数级别已经有上T的了,可能未来这种100T参数级别的模型也会出现。像这一类AI DSA,未来发展的方向可能是针对一个更专用的领域去优化,比如支持巨型模型。
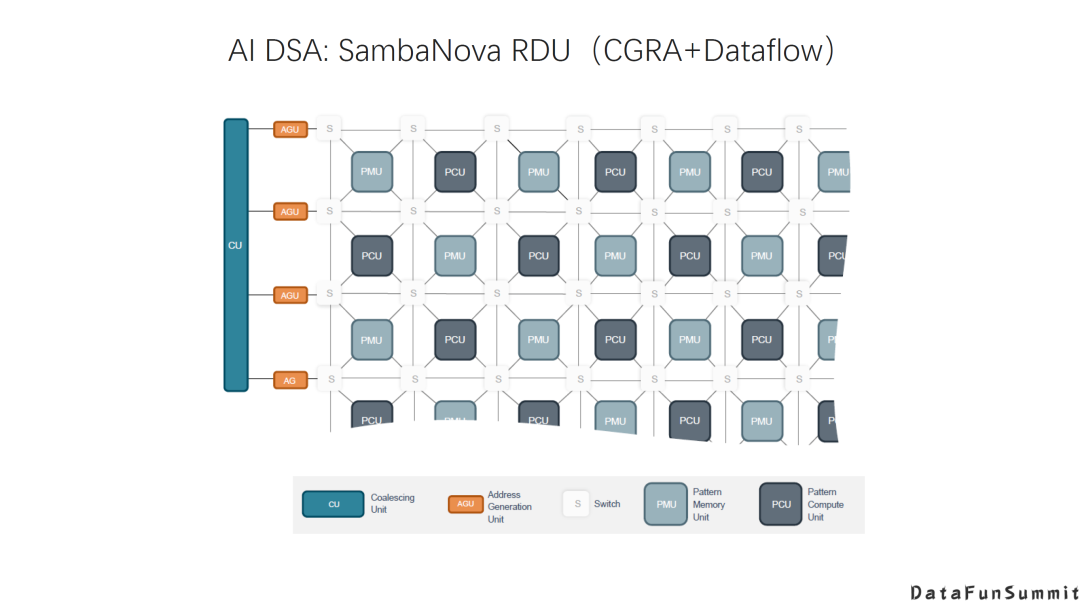
另外还有一类架构是基于CGRA架构,这种架构和传统的基于指令的处理器的架构有比较大的差别。它在整个架构有可重构的存储和处理模块,模块之间的互联也是可重构的。这种架构是采用Dataflow的方式来编程的,对于一些神经网络的模型,可以形成一个优化的数据流的结构,就能够实现比较高的效率。

再说一个很有意思的架构,就是特斯拉发布的Dojo D1。从基本的设计思路,然后到系统级的封装,都做了很多创新的工作。它的出发点是想设计一个专门针对神经网络训练的DSA,也很值得大家的关注。
1. 设计新的架构需要软硬件的全栈支持
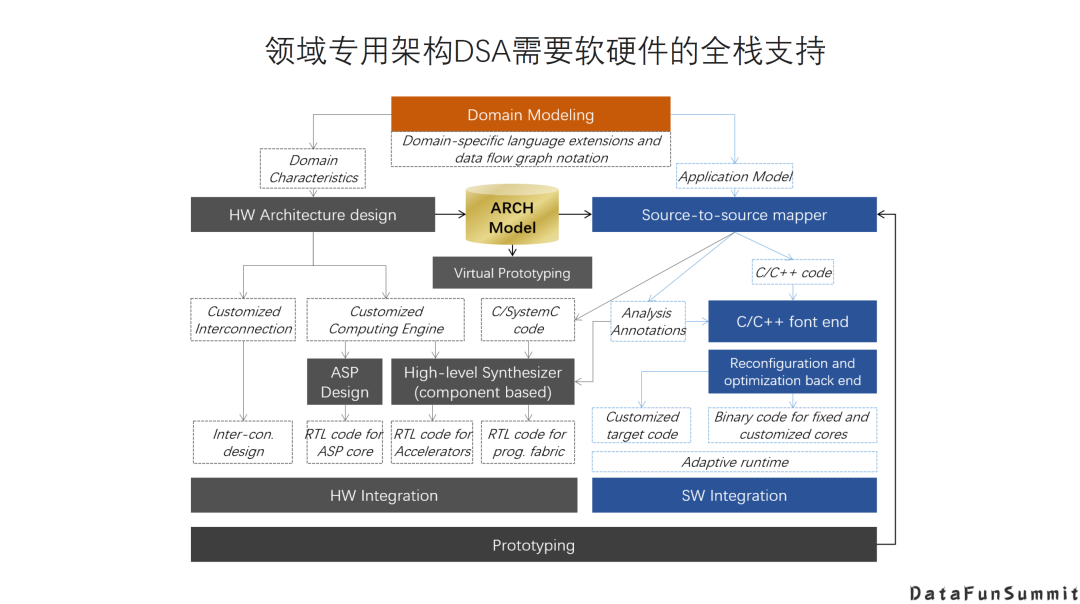
面向一个领域的DSA往往是设计一个新的架构,而一个新的架构并不是单纯的硬件设计,而是需要的软硬件的全栈支持。一个新的硬件架构,它可能有需要有新的指令集或者编程模型,需要有相应的软件工具,甚至可能需要有一个软硬件协同设计和验证的方法学。这些必须是一个完整的解决方案,才能让一个新的DSA能够得到比较好的应用。
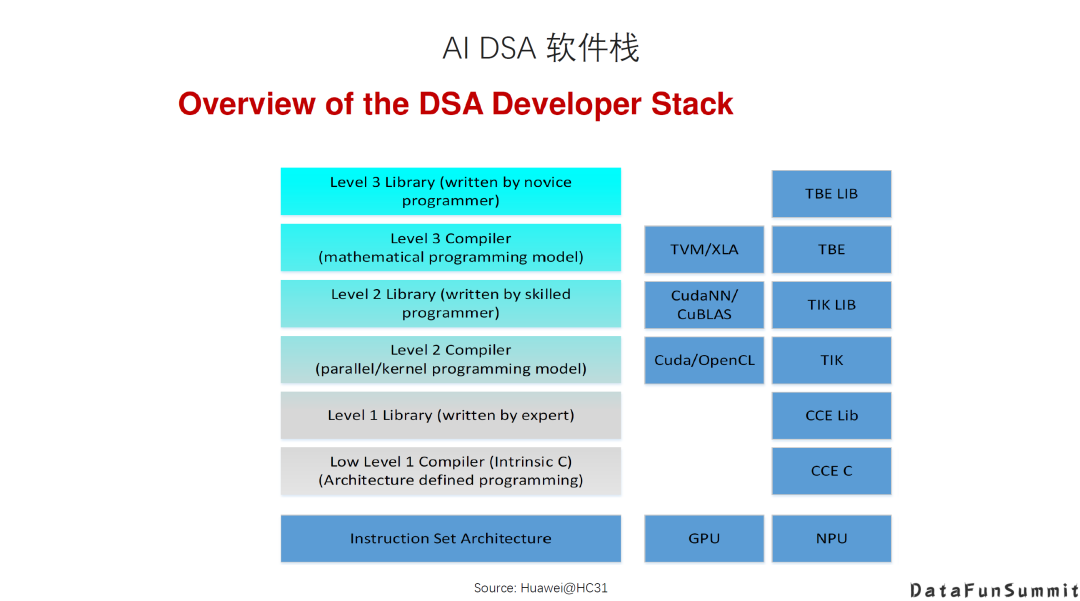
这也是华为在Hotchip上分享达芬奇设计的时候,介绍的DSA开发者软件栈。可以看到在这个软件栈里面,会有不同的层次的开发者参与,也需要提供不同层次的完整的软件工具,包括库,编程语言,编译器等等。
2. 软硬件技术栈的碎片化
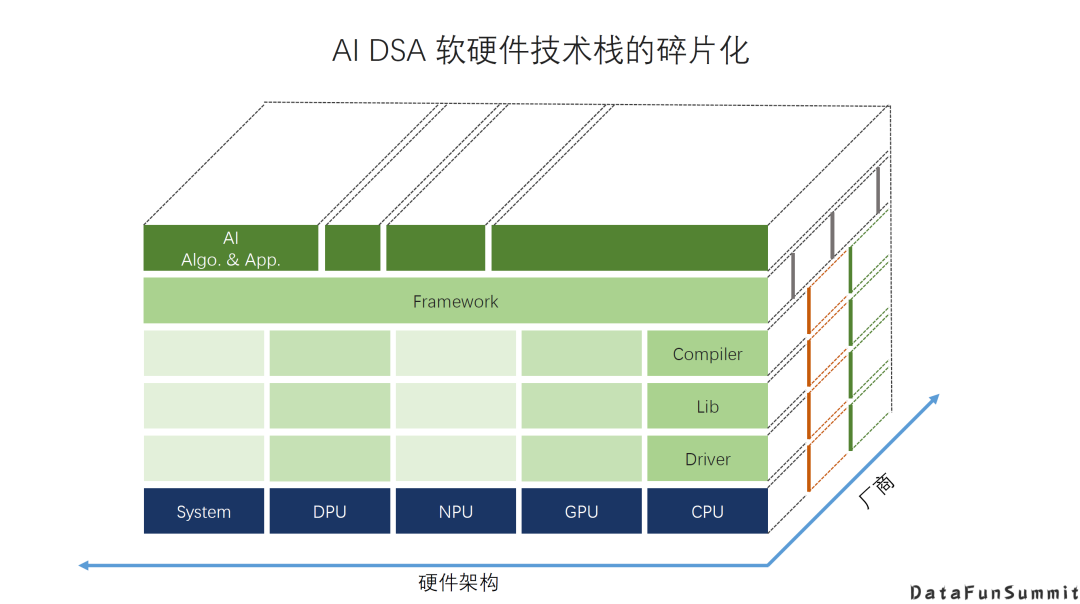
前面我们介绍了很多新的AI DSA架构,有一个比较大的挑战或者问题是相应的软件栈。不同的硬件架构,以及同一类架构不同细节差异。加上不同厂商的方案差异,都导致硬件和软件栈的碎片化现状和很多现实的问题。不同的厂商会有不同的架构的选择,或者是同一类的架构,也有不同的细节设计。不同厂商提供相应的软件栈,也都会有一些自己不同的实现方法。所以我们就看到各种各样的软硬件的组合,和大量的重复劳动,比如说硬件可能要适配很多不同的框架或者应用;而对于对于上层软件来说要适配不同的硬件。
当然现在也看到很多工作就是在解决,或者试图解决这个问题,特别是在框架和编译器层面,这也是后面大家会重点讨论的话题。一种解决的思路就是希望能在某一个层次上找到一个比较合理的抽象,大家能统一到一个一致的IR或者接口,至少可能在某一个层次上的先解决碎片化的问题。然后尽量把不同的硬件架构或者不同厂商的需要实现的部分变得比较薄一些。这样可能整体上提升AI DSA开发的效率,促进整个AI DSA生态的发展。
3. 分层抽象的理想与现实
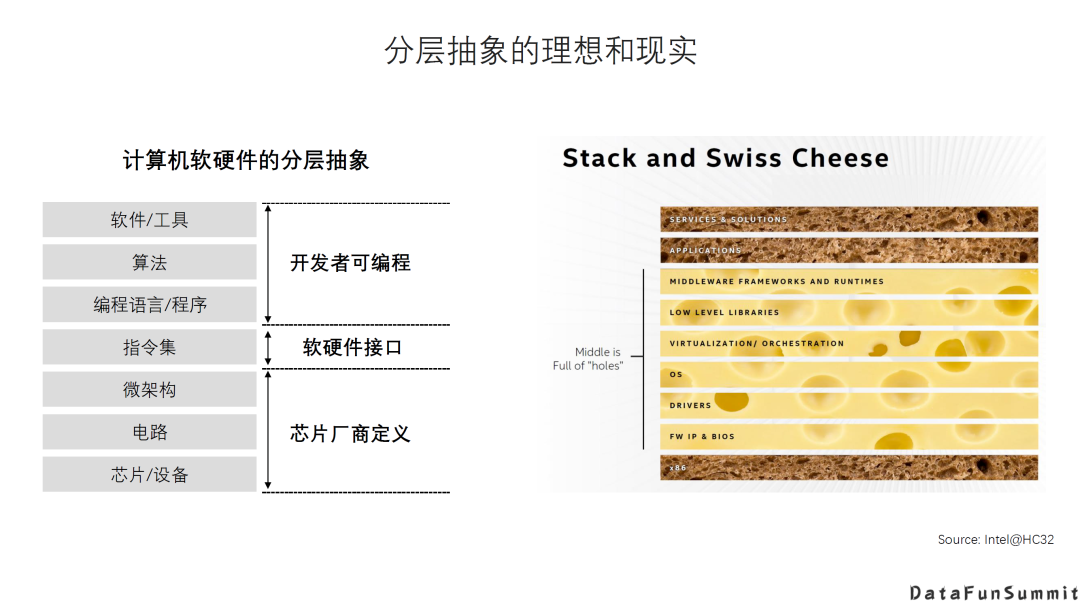
我们在做计算机软硬件设计时,左图描述的分层抽象是一个非常重要的方法学。通过一个定义比较清晰的层次和接口,能够采用分而治之的方法来解决复杂的问题,大家可以聚焦在自己的层次上,只要提供一个统一的接口就可以了,这是比较理想的情况。
然而现实的情况可能更多的是右侧的“奶酪模型”,大家出于不同的需求和目的,可能要在不同层次间打一些“洞”直接直接调用下面几层的接口或者提供的feature,导致整个理想的清晰的分层实际是很难实现的。
这里看到的“奶酪”情况还是针对比较成熟的CPU生态。而由于AI DSA来说,至少到目前为止,还没有大家公认的分层模型和接口的设计。为了追求硬件性能,或者是充分利用现在DSA硬件的创新,不得不让程序员或者软件工具直接面对很多硬件的复杂度,导致整个软件栈设计面临更大困难。
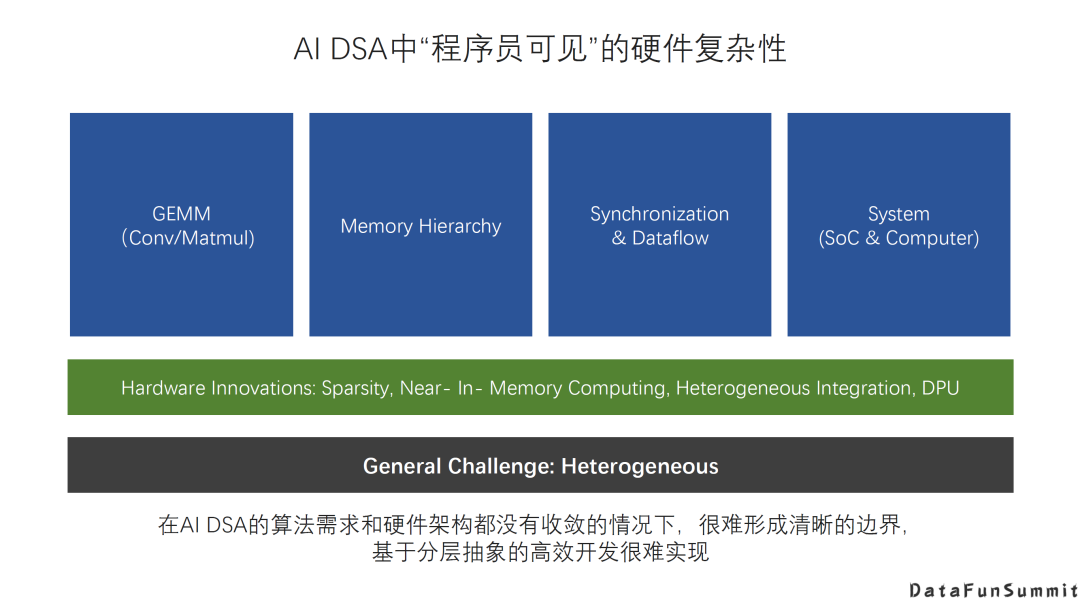
这里看一些例子。第一就是AI里最常见的核心运算,GEMM运算。对GEMM的实现不同硬件都有一些差异,软件(程序员)如果不能很好的利用硬件的细节特征,可能就无法实现对于GEMM硬件的高效利用;第二,在AI DSA比较常见的实践是很多Memory直接有软件(程序员)管理,增加了软件栈的复杂性,特别是如果Memory Hierarchy有较多层次的时候复杂性就会更高;第三,AI加速主要是通过大量的并行计算来实现,软件(程序员)必须充分利用硬件提供的同步机制,才能让并行运行的工作有效的配合起来;另外,从系统角度看,不管是SOC芯片,还是一个Server,甚至是整个数据中心,还包括很多涉及互联,网络,或者其它和硬件能力或者是硬件器件相关的因素需要考虑,都也会影响到模型的训练和部署效率。
从另一个角度来看,未来还我们还会看到更多硬件的创新,比如近存储计算或者是存内计算,芯片的异构集成,或者系统层面的一些变化,比如DPU的引入等等。这些也都会直接影响到编程模型,或者是大家使用硬件的方式,这些东西都会反映到程序员的编程的难度和软件栈优化的复杂性上面。
最后,还有一个非常基本的挑战,就是异构的挑战。到目前为止,解决的比较好的异构编程模型就是CUDA。但是随着DSA的更多应用,系统的异构特征会越来越强。要把异构特性的效率发挥得更高并且保证一定的Productivity,软件栈面临的压力是相当大的。
AI DSA诞生的大背景是:传统通用芯片无法满足新的计算模式的需求
AI DAS需要实现软硬件的全栈解决方案
AI DSA的发展方向取决于AI算法和应用的发展以及底层芯片技术的支撑,未来很长一段时间仍然可能是多种架构并存
由于软件硬件不同层次间还无法形成清晰的边界,巨大的软硬件的设计空间混杂在一起,给设计和优化带来巨大挑战
硬件架构的创新最终是以一个完整的软硬件技术栈提供给用户的,如果没有好的软件支持,硬件创新无法产生真正的收益
Q:MIMD实现的难度和优缺点
A:它是一个大规模多核并行的架构,每个核里又有多个thread在同时处理。要分硬件和软件两个层面来看。硬件方面的难度不太好讲。从软件层面来讲,它的难度主要还是在怎么比较均衡、有效地把workload mapping到这么多并行的thread上,以及怎么实现thread间的同步。
Q:对于DSA来讲,软硬件栈上对于推理和训练会有比较大的差别,其实这个可能是现在大家、一些厂商都会面临的一些问题。您对这种情况怎样看待呢?
因为训练和推理在需求上还是有比较大的差别的,包括数据精度上,包括它的计算图的复杂度和灵活性上,理论上能够支持训练的计算图的话,推理应该也可以实现。但是问题是效率,在同一个DSA上同时高效的来实现训练和推理,目前看还是有挺大的难度的。我们最终去判断一个推理的芯片是不是做得好,当然是看效率,反映在能效比和成本这些因素上;对于一个训练芯片来讲,可能更多要关注能是不是能有更强的扩展性,是不是能训练更大的模型。所以我个人感觉想统一在一个架构上有都能做的很好非常困难。
今天的分享就到这里,谢谢大家。
分享嘉宾:

专知便捷查看
便捷下载,请关注专知公众号(点击上方蓝色专知关注)
后台回复“人工智能芯片” 就可以获取《人工智能芯片专知资料》专知下载链接





