Science:有调查有真相!某些AI领域多年无实际进展

来源:AI科技评论
作者 | 蒋宝尚
编辑 | 丛末
5 月 29 日,Science 刊登了一篇标题为“人工智能某些领域的核心进展一直停滞不前”的文章,在文章里,作者 Matthew Hutson 提到:一些多年之前的“老算法”如果经过微调,其性能足以匹敌当前的 SOTA。

对神经网络剪枝技术进行对比分析的论文是“What is the State of Neural Network Pruning?”,论文一作是来自麻省理工的研究员 Davis Blalock。
他们通过对比 81 相关篇论文,并在对照条件下对数百个模型进行修剪后,明显发现神经网络剪枝这一领域并没有标准化的基准和指标。换句话说,当前最新论文发表的技术很难进行量化,所以,很难确定该领域在过去的三十年中取得了多少进展。
主要表现在:
1、许多论文虽然声明提高了技术水平,但忽略了与其他方法进行比较(这些方法也声称达到了 SOTA)。这种忽略体现两个方面,一个是忽略 2010 年之前的剪枝技术,另一个是忽略了现在的剪枝技术。
2、数据集和架构都呈现“碎片化”。81 篇论文一共使用了 49 个数据集、132 个体系结构和 195 个(数据集、体系结构)组合。
3、评价指标“碎片化”。论文使用了各种各样的评价指标,因此很难比较论文之间的结果。
4、混淆变量。有些混淆的变量使得定量分析变得十分困难。例如,初始模型的准确度和效率、训练和微调中的随机变化等等。
在论文的最后,Davis Blalock 提出了具体的补救措施,并引入了开源的框架 ShrinkBench,用于促进剪枝方法的标准化评估。另外,此篇论文发表在了 3 月份的 MLSys 会议上。

论文下载地址:
https://dl.acm.org/doi/pdf/10.1145/3298689.3347058
深度度量学习:该领域 13 年来并无进展

论文下载地址:
https://arxiv.org/pdf/2003.08505.pdf

三个 toy示例:不同的精确指标如何评分。
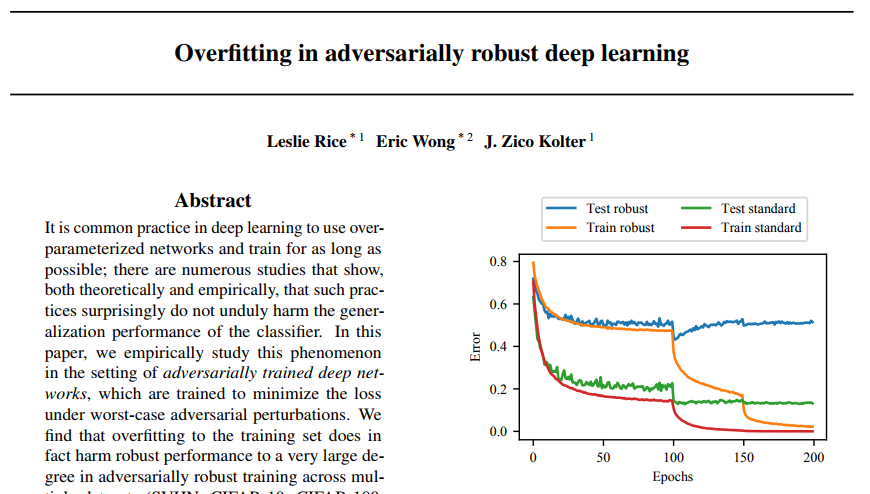
对“对抗性训练”进行研究的论文标题是“Overfitting in adversarially robust deep learning”,第一作者是来自卡内基梅陇大学的研究员 Leslie Rice。
在论文中,作者提到机器学习算法的进步可以来自架构、损失函数、优化策略等的改变,对这三个因素中的任何一个进行微调都能够改变算法的性能。
他的研究领域是对抗训练,他说:经过训练的图像识别模型可以免受黑客的 "对抗性攻击",早期的对抗训练方法被称为投影梯度下降算法(projected gradient descent)。
近期的很多研究都声称他们的对抗训练算法比投影梯度下降算法要好的多,但是经过研究发现,几乎所有最近的算法改进在对抗性训练上的性能改进都可以通过简单地使用“提前停止”来达到。另外,在对抗训练模型中,诸如双下降曲线之类的效应仍然存在,观察到的过拟合也不能很多的解释。
最后,作者研究了几种经典的和现代的深度学习过拟合补救方法,包括正则化和数据增强,发现没有一种方法能超得过“提前停止”达到的收益。所以,他们得出结论:PGD 之类的创新很难实现,当前的研究很少有实质性改进。

对语言翻译进行研究的论文名为“On the State of the Art of Evaluation in Neural Language Models,此论文是 DeepMind 和牛津大学合力完成。
在论文中,作者提到神经网络架构的不断创新,为语言建模基准提供了稳定的最新成果。这些成果都是使用不同的代码库和有限的计算资源进行评估的,而这种评估是不可控的。
根据其论文内容,作者一共主要研究了三个递归模型架构(recurrent architectures),分别是:LSTM、 RHN(Recurrent Highway Network)、NAS。研究 RHN 是因为它在多个数据集上达到了 SOTA,而研究 NAS 是因为它的架构是基于自动强化学习的优化过程的结果。
最后,作者通过大规模的自动黑箱超参数调优,重新评估了几种流行的体系结构和正则化方法,得出的一个结论是:标准的 LSTM 体系结构在适当的正则化后,其性能表现优于“近期”的模型。
via https://www.sciencemag.org/news/2020/05/eye-catching-advances-some-ai-fields-are-not-real








点击"阅读原文",查看更多精彩!



