Facebook聊天AI新突破!可根据用户公开资料改变性格

长按识别二维码,报名2018十大突破技术全球直播首发
聊天是一门艺术,自进入大数据时代后,AI也学会了这门艺术。尽管AI聊天机器人已经屡见不鲜了,但是 Facebook 人工智能研究实验室(FAIR)依然在该领域努力钻研。最近他们又有了新成果,这是一种通过自然语言处理、对话、神经模型等技术构造的全新 AI 聊天技术。
FAIR 称这是一种可以用来闲聊的聊天AI技术。相较以往,这项技术最大的突破就是在于它的“性格”。传统聊天AI的性格都是统一的,并不能满足于所有的用户。而 FAIR 则为这个闲聊 AI 添加了一道塑造性格的措施:1.收集用户的个人公开资料;2.收集这些用户的关系网。再把这些数据放进模型之中,便可以模拟出用户喜欢的性格,并以此和用户进行闲聊。

事实上基于神经模型的聊天AI是最近才诞生的,然而这些AI技术往往不能和用户进行长时间的沟通。因为AI需要在响应用户回话的同时访问数据网络,还必须要有足够庞大的数据集支撑。不过这两点,也正是 Facebook 的优势。
FAIR 实验室通过他们的数据网络先创造了一个可以定制的基础AI性格,被称为配置文件。再将配置文件置于内存扩充式神经网络之中。根据上述的用户资料,将这个配置文件进行调整,使其变成另外一个更适合用户的性格,以贴合用户需求。
依照此步骤,FAIR 一共创建了 1155 个独立性格,每个性格都拥有最少5个配置文件。不仅如此,他们还有 100 个用于测试的性格和 100 个等待测试的性格。当然,为了让这 1155 个性格更加独特,FAIR 把这些性格所有重合的句子(比如口头禅)全都重新调整,使之成为真正意义上的独立性格。

但是这还没完,闲聊机器人的性格建立完成后会向用户提一些问题,或者发起一些话题。这项功能不仅仅是为了区别传统Q&A式聊天机器人,还有一个更重要的原因:分析用户聊天意向,建立用户模型。
FAIR在论文中给出了这样一则演示,上边为原始性格(配置文件),下边为基于用户的公开资料所调整的性格。
※ 基础性格:
我爱沙滩。
我爸有个4S店。
我刚刚做完指甲。
我正在节食。
我最喜欢的动物是马。
※ 调整性格:
没有什么比在在海边悠闲地呆上一天更让人心旷神怡。
我爸以卖车为生。
我总是定期关心我自己。
我必须要减肥了!
我很喜欢马术。
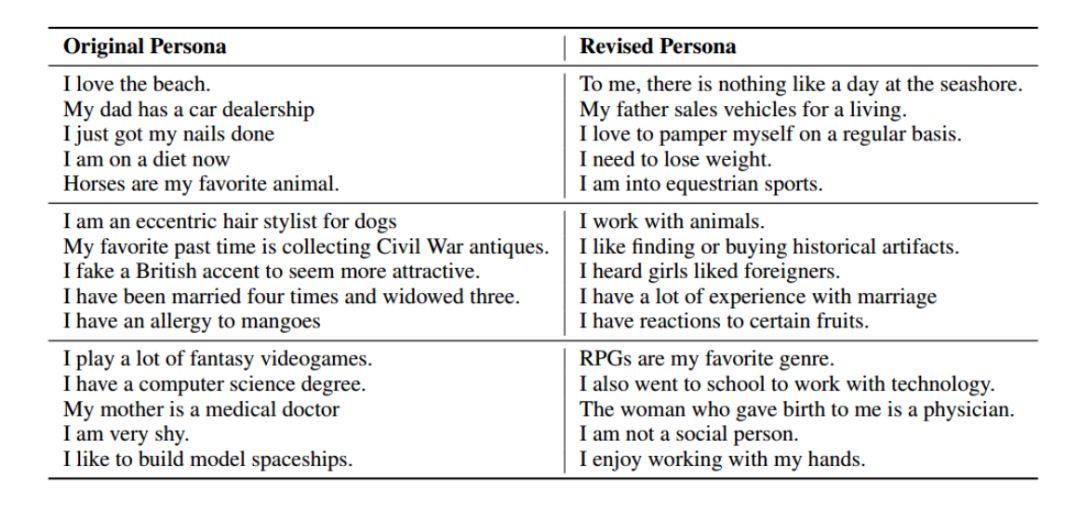
图丨作为配置文件性格,右为调整后性格
性格数据集
对此,FAIR 创建了一种新的数据集,将其命名为性格数据集。这个数据集由随机配对的 164,356 条对话组成,每个对话都要求对话双方进行“角色扮演”,同时双方会在对话之中逐渐了解。FAIR 表示,这一过程产生了许多引人入胜的谈话内容,这对闲聊AI的帮助非常大。
性格数据集分为两层,即基础性格层(又称性格层)和调整性格层。在基础性格层,FAIR 会用 4 个句子来描述一个性格,比如“我是素食者”、“我喜欢游泳”、“我父亲在福特工作”、“我最喜欢的乐队是 Maroon5 ”。
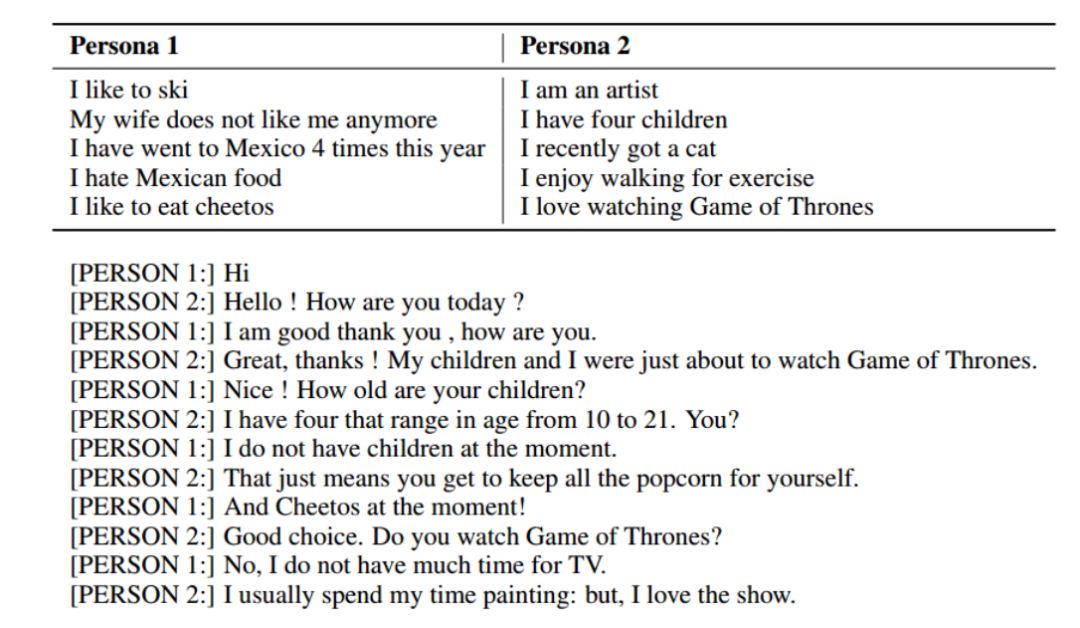
图丨两个闲聊AI进行角色扮演
基础性格层的每个句子的长度不能超过15个单词,这是为了让性格数据集能够更迅速地理解性格,每个句子单词过多,则会导致性格数据集无法和用户保持长时间聊天。同时,简单的句子也能够让用户更直观地理解闲聊AI的性格。
调整性格层则是对这些句子进行修改,并且单词的数量也有所放宽。但是该层需要面对另外一个问题——重叠。FAIR实验室表示,这是一个人类也会犯的错误。有些时候,这些调整过的句子只是把单词换了,但是整个句子的轮廓没有改变,这就使得两个独立的性格出现了重叠的地方。正如上文所说,FAIR对所有重叠的性格进行了调整。
他们的做法是把这些轮廓相同的句子拿去给一支外包语言团队进行改写,比如把“我喜欢篮球”改写成“我很崇拜 Micheal Jordan ”。这样的改写很大一定程度上偏离了句子的本意,但即便如此,改写前后仍存在相互重合的地方。
不过调整性格层的工作远没有那么简单。外包团队很有可能把“我爸爸在福特工作”改写成“福特雇佣了我爸爸”。这样的改写在FAIR眼中是不合格的,因为这样的改写并没有调整轮廓。
在所有外包团队的工作都完成后,FAIR 还要进行一个步骤,就是把句子调整地更自然。比如,调整性格层有这样一个句子“我喜欢咀嚼盐”“我喜欢吞下扭曲的面包”。这样的句子并不合理,即使地球上会有小部分有如此猎奇的爱好,但是这并不是性格数据集应该呈现给用户的样子。
实践出真知
FAIR 还将性格数据集和用电影脚本训练的 OpenSubtitles 数据集进行比对,用户的反馈是前者更能提出一些引人入胜的话题,还能长时间沟通。这对于FAIR来说还不够,毕竟他们不能把数据集拿出来给用户,而是要把它植入进闲聊 AI 才行。
图丨闲聊AI模型
最终,FAIR利用生成模型和判别模型进行检测,发现无论在怎样的前提下,具有性格的闲聊AI,都要比传统性格统一的聊天AI更让用户喜欢。
这个结果对于 Facebook 来说无疑是大喜欢,因为这项研究不仅让该企业突破了自然语言理解的研究深度,也改善了 Facebook 自家的聊天AI。不过 FAIR 实验室并不满足于这个结果,他们表示,未来将会用这个闲聊AI和性格数据集来训练其他聊天 AI 。同时他们也认为,未来的聊天AI绝对不是像传统聊天AI一样,对所有用户都保持着相同的性格。

其实闲聊AI和微软小冰有异曲同工之处,不过闲聊AI的性格更多样化一些,而小冰则是偏向于花季少女的性格。FAIR指出,闲聊AI可能会用于改善 Facebook 聊天机器人,除此之外并没有明确的应用方向。若以小冰作为参考,该AI出过有版权的诗集《阳光湿了玻璃窗》,也演奏过原创版权乐曲,还和小米生态链产品共同推出过智能音箱。
考虑到闲聊 AI 的功能来看,它的应用范围应该比小冰还要广。
2015年时,Facebook 曾宣布他们要开发一个虚拟助手 M,就像《钢铁侠》中的“贾维斯”一样。虚拟助手 M 可以陪用户聊天,还可以帮用户打理智能家居产品。不过2018年1月时,Facebook 就宣布要关闭智能助手M了。这是因智能助手M并不是合格的人工智能,该产品还是需要依赖大量的人力才能实现全部功能。
不过智能助手 M 并不是真的“死了”,它的一些功能,如聊天,得以保留,并被整合至 Facebook 的信息功能之中。而智能助手 M 的结束也并不代表Facebook 在语言处理上落后于其他企业,事实上,该公司旗下两款聊天AI“Alice”和“Bob”已经通过对话创造出了新的语言。
至于 Facebook 会把闲聊 AI 放到什么样的位置,这点无从而知,不过这项研究让Facebook 在语言上的造诣迈上新阶梯是肯定的了。
-End-






