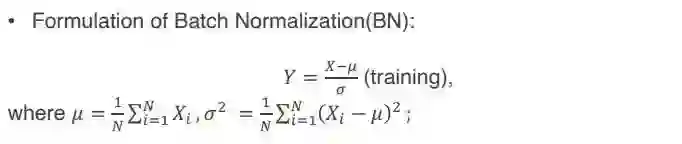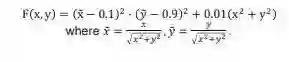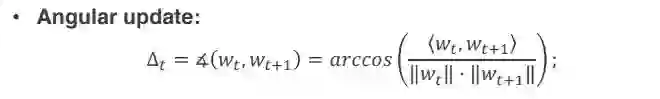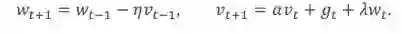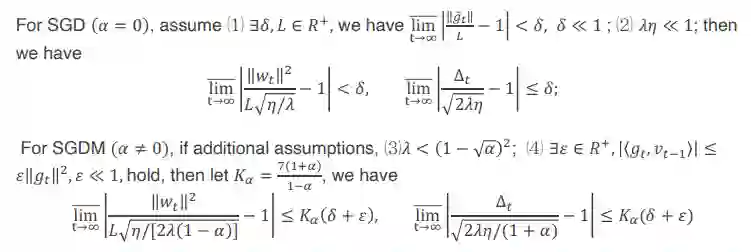![]()
本文内容整理自 PaperWeekly 和 biendata 在 B 站组织的直播回顾,点击文末阅读原文即可跳转至 B 站收看本次分享完整视频录像,如需嘉宾课件,请在 PaperWeekly 公众号回复关键词课件下载获取下载链接。
作者简介:
万若斯,现为旷视研究院基础模型组的算法研究员。在北京大学数学科学学院取得应用数学学士学位,并在北京大学前沿交叉学院获得数据科学硕士学位。主要研究方向是深度学习模型与训练方法的理论基础。
批归一化(Batch Normalization,BN)和权重衰减(weight decay,WD)以其出色稳定的表现成为了当今各种深度学习模型的标准配置,但它们的理论机制,一直以来仅有模糊的定性分析。
本文将主要介绍 BN 和 WD 对深度神经网络的训练过程的共同作用的球面优化机制(Spherical Motion Dynamics, SMD)。基于球面优化机制的定量理论结果,不受限于模型的结构、数据集或任务类型,可以在诸如 ImageNet,COCO 等基于真实数据的复杂计算机视觉任务上得到完美验证。
![]()
放缩不变性
首先回顾一下关于 batch normalization(以下简称 BN)的形式和性质。BN 是深度神经网络技术里面最常用的标准方法之一,除了比较特殊的一些情形以外,几乎所有的神经网络如果训练出现了问题,加个 BN 基本上都可以得到一些不错的结果。BN 的主要形式如下(训练阶段):
![]()
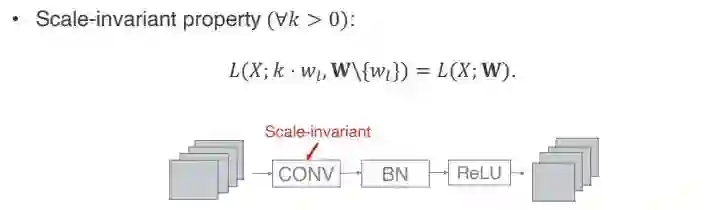
如果一个网络带上 BN 会有什么样的性质?本文将重点探讨其中的一个性质,即 scale invariant property,中文翻译为放缩不变性。
它的具体含义是,一般构建一个神经网络,以经典网络 ResNet 为例,它组成元件顺序为,首先是 conv 层,接一个 BN 层,再经过一个 relu,下面又重复 conv、BN、relu,后面可能会接个 short cut。单就 conv 层本身的参数而言,由于它后面经过了一个 BN,所以它会有一个 scale invariant 性质。具体的数学定义如下:
![]()
给定任意一个正系数 K,如果其他的参数都不变,只对 conv 层的参数放大 K 倍,它的 loss 不会有任何变化。其实不只是 loss 不会有变化,如果做分类任务,分类的值相对大小也不会有任何变化。这个 scale invariant property 是由于 BN 在 conv 后面除以 variance 所导致的。
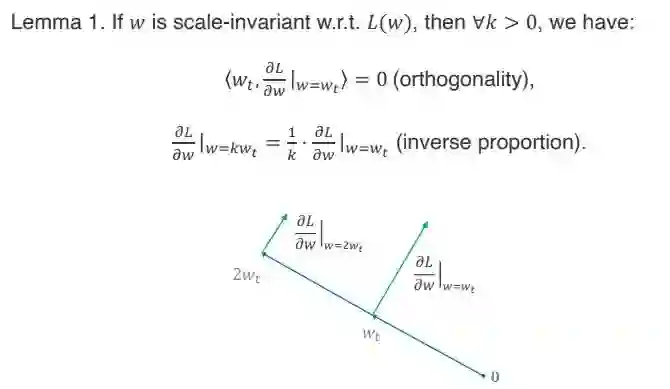
由于 scale invariant property 会有更进一步的性质,这里面以 lemma 1 的形式给出来了。主要有两个性质,第一个是正交性,如果我们把 Weight(以下简称 Wt)看成是一个向量,在 Wt 上的梯度也看成一个向量,它们内积为 0,就是严格正交。
第二个是所谓的反比例关系,就是如果把梯度乘上 K 倍,它所对应的 gradience 方向和原来保持一致,但是它 gradience 方向的模长会是原来的 1/k。
![]()
下面来探讨一下,这两个性质对优化造成的影响。如果只考虑 SGD 的更新或者 GD 的更新,不考虑 Weight Decay(以下简称 WD)的话,那么就会有影响。
第一个影响是 Wt 的模长始终在增加。原因是一般 gradience 是乘上一个 learning rate, 然后去更新 Wt,那么就会形成一个直角三角形。然后新的 Wt 的模长是这个直角三角形的斜边,它始终会大于原来的 Wt。而且每一次用 SGD 的更新,都会比原来的大,所以只要这个 gradience 不恰好等于 0,那么 Wt 的模长便单调递增。
但是这个单调递增会导致另外一个性质,即梯度的模长可能会因为 Wt 的增加而减少。梯度模长本身除了它自己的一些方向不变,然后得到的那个梯度以外,还跟这个 Wt 的模长成反比。
![]()
所以可以想象一下,假设初始化一个网络,它的 loss 可能很大,需要进行优化。经过传统的优化的理论,应该会找到一个 local minima,一般来说 local minima 是个 stationary point,它的 gradience 范数很小。
但是在带有 BN 的情况下,如果不改变 Wt 的方向,只是无限的增大这个 Wt 的范数长度,最后得到的这个 gradience 它的范数仍然很小,就不能确定它是否是一个 stationary point,但可以肯定它不是一个 local minimal。
此时就会出现一个问题,似乎传统的优化,在带 BN 的网络里面会出现一些奇怪的现象,而且也可以说明了一点,WD 是必要的。
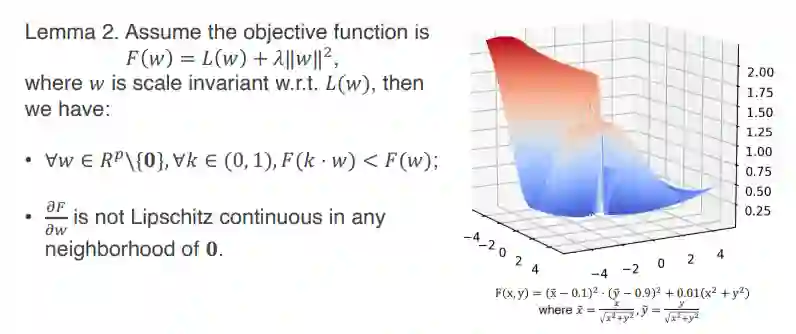
再来探讨一下,如果加了 WD 又会发生什么样的事?假设 objective function 如下:
![]()
此时会有以下两个结论,第一个结论是,由于 W 的 scale environment 性质,所以 W 的范数大小是不会影响到 loss 的大小,但是它的范数大小会影响到 L2 recognize part 的大小。因此,如果对 W 乘上任意一个 0~1 之间的一个系数,都可以得到 objective function,它会严格的比原来小。
这样就有个直观的理解,对于一个带 BN 的网络,在它的定义上面(注意:定义域是不包含 0 的),任何一个点都不是它的 local minimal。它附近总有一些点,或者值会比它更小。
这样如果以收敛性的角度去看问题,或者说以 gradient flow,就是所谓的 learning rate 无穷小形成一个 gradient 流的情况去优化的状况,就会出现一个很自然的现象,即 Wt 会无限的趋近于 0。
但是 Wt 趋近于 0 又会出现另外一个问题。objective function 这个梯度在 0 附近,不是一个 lipschitz 的梯度。这个条件其实在很多非凸优化里面都是一个非常常用的必要条件。所以大家会默认符合这个条件。
但实际上在最常用的带 BN 和 WD 的网络,它很可能不符合这个要求。原因在于在带 BN 的网络中,V=0 这个位置是一个所谓的奇点。举例说明,lose function 的形式如下:
![]()
可以看到单就 loss 而言,它的 lipschitz 是非常规整的,它的最小解为 1。但是一旦加上了 BN 和 WD 之后,它的 lipschitz 是非常奇怪的。
直观来讲,这个收敛可能收敛到接近 0 的位置,但是这个 0 的位置又因为过于突兀的变化,有可能跑到其他的位置。所以这里面就展示了带 BN 和 WD 的网络,不能够直接单纯的把它作为 objective function 的一个部分,把它们 join 的去考虑怎么去对它们优化,形成了什么样的性质。
因为如果这样考虑,得到的很多最基本的 assumption 都可能是不满足的。我们实际中我们还是用 objective,不需要什么精心调参,也可以得到不错的结果,这是为什么呢?
![]()
在解释这个问题之前,首先介绍一些基本概念。第一个概念是单位梯度(Unit gradient),考虑到 WtWt 的 gradient 的范数大小会受到 Wt 范数本身大小的影响,所以定义单位梯度公式如下:
![]()
这样就可以把 Wt 的范数和 gradient 方向给它的影响各自区分开。
第二个概念是角度更新量(Angular update), 这个词是来自于物理学中,球面运动的角速度的概念,就是圆周运动角速度概念。这里借用了这个概念,用它来衡量一次更新前后 Wt 和 Wt+1 之间的角度。具体数学公式如下:
![]()
这里均假设 Wt 为非 0,这样定义的原因是去掉 Wt 的范数的影响,因为一般情况下,只要 Wt 方向固定,它的范数完全不会影响到深度学习网络的性能表现。Angular update 是真正可以表示出单步更新内 weight 变化情况的量。
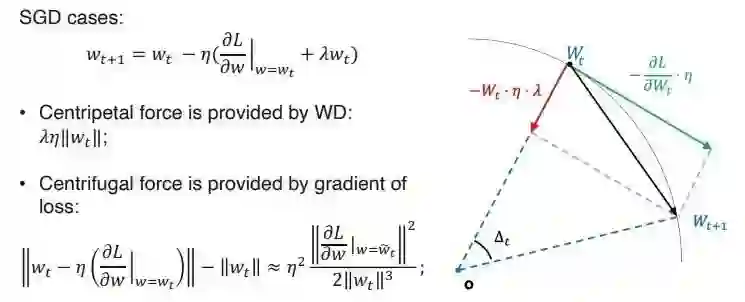
有了以上两个概念就可以理解球面优化动态过程了,为了说明方便,在这里只讨论了 SGD case,SGD 的一般更新法则如下图的公式所示,通过示意图可以看到,对于 wt 的范数的影响,如果借用物理学里圆周运动或球面运动概念的话,其实可以分为两个影响,第一个影响就是所谓的向心力,向心力实际上是完全由 WD 所提供的,它的大小就等于范数。
这个就意味着向心力是一个正比于球面半径的力;第二个影响力是离心力,离心力是由于 gradience 始终是垂直于 Wt 方向的。所以它总是会倾向于把 Wt 的 norm 变大,可以大致的推算出离心力的大小。可以看出离心力是一个反比例关系,它的反比例是关于 Wt 的三次方。
公式中的 unit gradient,刚才已经介绍了它是跟范数没有关系的量,故假设它约等于不变。直觉上来讲,这个向心力和离心力应该是会达到一个平衡的。因为向心力的大小是正比于这个球面半径的,离心率是反比关系的。这样的话如果球面半径过小,那么向心力就比较偏弱,离心力比偏强,所以球的半径就会偏大。
但球门半径大了以后,向心力又会变强,离心力会变弱。这样它就会有一个平稳状态,而当向心力和离心力已经达到平衡的时候,就应该满足下图中第一个等式关系。当这个等式关系成立以后,就可以去推导此时的 Angular update,推导公式如下图第二个公式,
![]()
所以这里可以得到一个结论,当达到平稳状态以后,角度更新量是约等于
,其中
是 wd 的系数,
是 learning rate,而这两个都是人为手调的,跟网络本身的形状或者是它的 grandience 大小、数据集等都没有关系。
所
以这里面就凸显一点,之前有很多文章讨论说,这个球面动态可以等效为一个 manifold organization,即在球面上优化。但根据上述的一些粗略的推导就可以看出,实际上它们是不是等价的。
因为 manifold 在一个单位球面上的优化,它的每一步的更新量是不定的,如果用 constant learning rate 的话,一方面它的 learning rate 是 constant,另一方面它的 gradience 是不可控的,它的更新量也是不可控的。而且理论上来说如果你这个 manifold loss 如果小的话,你的这个更新量会越来趋近于 0,它就意味着它收敛到一个 local minimal 或 stationary point。
其实在这之前已经有很多文章在做相关工作了,他们都是认为前文所说的平稳状态一定会出现,假设 Wt 的范数是 coverge 的情况下,得出相关的结果。如下图所示:
![]()
最早是于 2017 年 NeurIPS, 由 Twan van Laarhoven 提出了 efficient learningrate 的概念,就是上文所说的 scale invariant 性质,如何去真正衡量有效更新量?在他的那个论文里面倒是提到了这个应该对于 SGD/SGDM 的性质都是成立的。
2018 年的这篇 NeurIPS 作者的结论比其他的都薄弱,但是与众不同之处在于它假设没有 wt 的 converge,只是单纯的研究了 wt,wt+1 更新以后的结果,所以它的结果是非常的薄弱的,而且也只能适用于 SGD 形式。
2019 年的 NeurIPS,这篇文章实际上他本身做的是针对小 BN 提出了一个方法的文章,只不过他在讨论里面专门有一小节,提了一下关于 BN 的一些 efficient learning rate 的现象,得到了类似的结果,不过在他的那个描述里面, 只是把 Wt 放在一维圆上面去讨论的,没有推广到高维上。
还有 2019 年的 ICLR 最新的一篇,这一篇它形式看上去比较的复杂一点,公式如上图所示,这个是在 SGDM 里面成立的,它直接讨论了 SGDM 的形式,同时包含了 SGD 的形式。当然其中是用了非常强的假设,关于他们的累计相对更新量的比值必须是各自为 converge 的情况下,才会有这样的结论。
所以这里面就出现两个问题,第一个问题如果 Wt 真的 converge 了吗?大家都之前的讨论的都是假设它 converge 了,但是它是否真的 converge 了?第二个问题是绝大多数情况下考虑的都是 SGD 形式,但是大家更多常用的是 SGDM 的形式,那么 SGD 它是否也有像 SGD 这样的平稳状态的情形。
![]()
主要定理
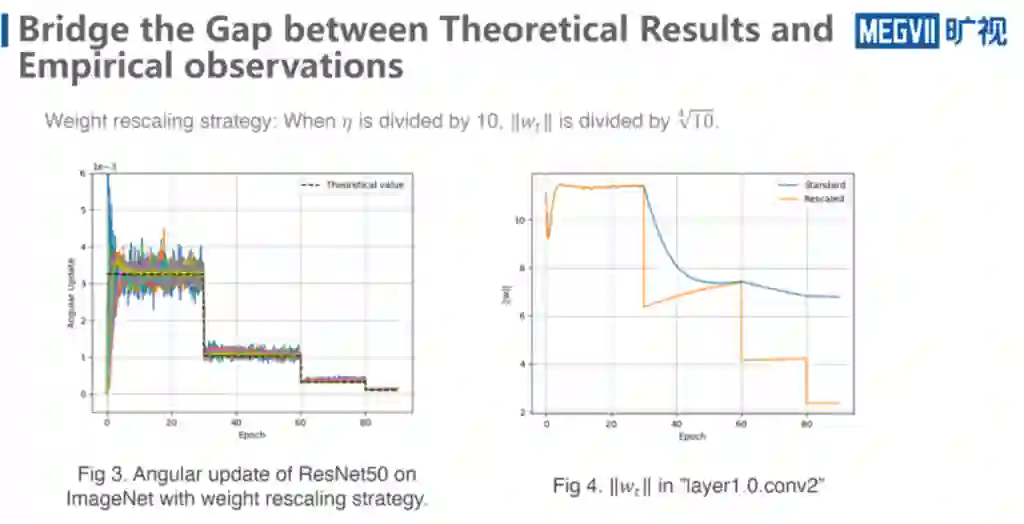
本文就是针对以上两个问题,给出相应的解答。下图是我们的主要定理,本文讨论的是最常用的 heavy ball method 的 SGDM 的形式。
![]()
SGDM 的公式如下,当 α=0 的时候,它恰好就是纯 SGD 形式。
![]()
下面是需要满足的两个 assumption 的情况。第一个 assumption 大致是在说 unit gradient,它平均表现会收敛到某一个值 L,但对 L 不做约束,它的相对误差会是一个比较小的值。第二个就是 WD 系数和 learning rate 的乘积远远要小于 1,就是一个比较小的数,这个一般来说常用的神经网络任务都是可以满足。
最后得到这个结果说明了 Wt 的平均值会 coverge 一个固定的值,而这个固定的值一方面依赖于这两个超参,另一方面依赖于 unit gradient 的一个大小。而 Angular update 就是角度更新量,则是会收敛到一个跟其他完全无关,只跟超参数 λ,η 有关的地方。
![]()
上图是 SGD 的情形,相对来说比较好做一些,比较难的就是 SGDM 形式,它需要依赖额外的两个 assumption,第一个 assumption 是 WD 的系数 λ 要小于某一个值,但一般来说 λ 本身就是特别小的。第二个 assumption 是关于第 T 次算出来的 gradience 和第 T 次的 momentum 的内积值要比较小,这是一个 technical 的一个 assumption,但是实际在实验中它基本上都是满足的,后面会展示到。
有了额外两个 assumption 就可以得到以下结论,在 moment 的情况下,weight 的范数也会收敛到一个值,只不过这个值相对于原来的话,它是乘上 2 (1-α),然后角度更新量的值则会是除以 (1+α)再开方,这里面是说明了这个 Angular update 它本身还是一个只跟超参有关的东西。
下面来介绍一下,从主要定理的结构中可以得到一些 Insight。主要列出其中三条:
![]()
第一条 insight 是:它完全解释了为什么 scale-invariant 带了 WD 的情况下是完全不会遇到 vanishing 和 exploding gradients 的问题,因为一般说 vanishing gradient 时它的 gradients 太小,结果会导致 learning rate 几乎不更新,exploding gradients 的 gradients 太大,导致 learning rate 每次更新都过大,就跑偏了。
但是如果有了球面优化的性质的话,经过一段时间的迭代之后,它会自动的去调整自己的 gradients 和 weight 的相对大小。最后当它平稳之后就会自然的满足 Angular update 下的情形,而 Angular update 实际上代表了真正的更新量,而这个更新量完全由超参决定,所以只要 gradients 不等于 0,然后训练只要不会出现 NAN,这个球面优化总是可以让你的这个训练最后变得正常起来。
第二条 insight 是:有了 BN 和 WD,SGD 和 SGDM 是不可能被限制在一个 sharp local minimum 里面,这个就是现在常讨论关于神经网络的泛化问题时,总会提到一个 sharp/flap local minimum,原因在于这个神经网络的本身它是一个非凸优化,而且它有很多很多的 local minimum,广泛的认知是说比较 sharp 的,即窄而细长的 local minimum 一般来说是比较糟糕的。
然后 flap minimum,即相对来说地势比较宽的会好一点。有了球形优化后,Angular update 是定义在球面上的一个 local minimum,当达到平稳状态后 Angular update 始终是个 fix,同时它又是由超参决定的,所以它的更新量一般不会落入比它小的半径内。
这是一个不太精确的东西,所以本文只是将其作为一个 insight 的给出。
但是它从某种上意义上说明了一个问题,因为过去人们认为正常 SGD 或者 SGDM 不会落到 sharp local minimum,把这全部归因为是随机的影响,认为说它可以 escape sharp local minimum ,但实际上由于 SD 和 SGD 它可能根本就不会落下去,或者说它落下去,可能一下就跑出来了,不是一个高概率 escape 的结论。
第三条 inside 是解释了为什么实际用 BN 和 WD 的时候,如果不做 learning rate decay,这个 loss 在下降到一定程度之后就不会再下降了。原因其实比较直观了,就是因为如果我们不 decay learning rate,同时不缩小 WD 的系数,也不碰这个 moment 系数的话,那么它的 Angular update 就始终是这个值,不会更小,那就意味着你不可能落到小于这个半径的坑里面。
这样会出现一个现象,找到一个 flap minimal,在这个地方来回震荡,一直落不下去。原因就是步子迈太大。而此时如果将 learning rate 减小,loss 便会收敛。
![]()
相关实验结果
以上是一些理论上的结果,下面来看一些实际的实验结果。本文直接用了计算机视觉界(CV)分类任务最常用的 baseline:ImageNet 和它最标准的 train setting,同时进一步对比了 detection 任务中的一个经典模型 Mask RCNN 网络和它的 train setting,在这种情况下,来验证球面优化的性质。
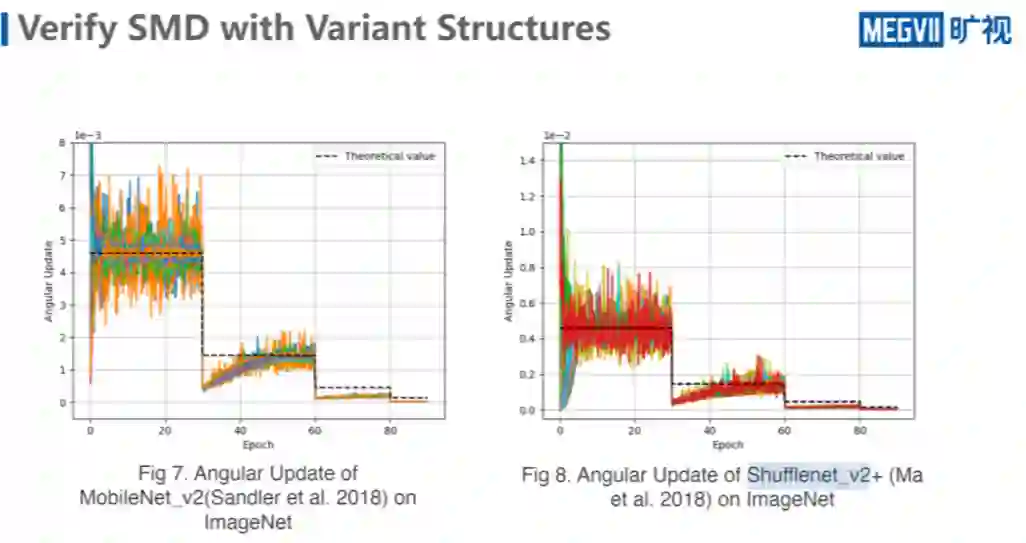
先看上图左边分类任务模型,其中不同的颜色的实线代表了一个 resnet50 的 conv 层,因为 resnet50 所有的 conv 层后面都接 BN,所以所有的 conv 层它都有 scale-invariant 的性质,而且它加入了 WD。
这里面包含了所有 conv,它在训练阶段的 angular update 表示一次前后更新的值,而且为了显示真实性,本文未对这个结果做任何的处理,这里面看到的就是它真实的 angular update,可以看到在第一个阶段,有些层它的 value 很大,有些层 value 很小,但是他们的平均都始终是维持在这个理论值附件,而这个理论值就是利用它们实际的超参算出来的值。
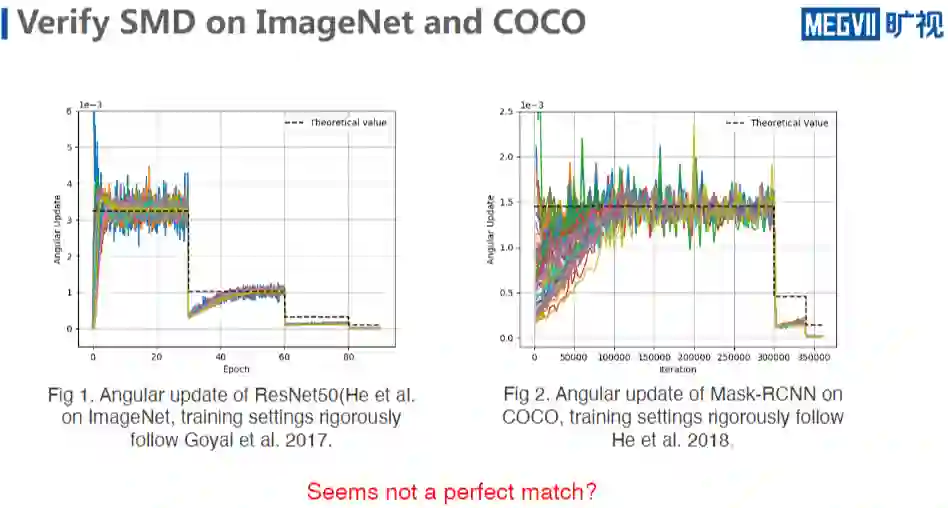
这里面的 learning schedule 采用的是,每 30 个 epoch,60 个 epoch、80 个 epoch,learning rate 会除以 10,可以看到至少在第一个阶段,它是比较符合的,第二个阶段的后半期,也是比较符合的,不符合的是这里面有一点 drop,最后阶段似乎是不符合的。
COCO 也是类似的,COCO 采取的是 4x,4x 大概 36 万次迭代,DK 的发生在 30 万次和 34 万次,learning rate 同样也是除以 10。可以看到至少在这个地方它是非常符合理论值,而且这里面的 gradience 也是用的 mask rcnn 里面接 BN 的 conv 层,计算出来的 angular update,也没有做任何的处理,出来的结果似乎是在部分阶段是吻合的非常好的,但是也在很多阶段,比如说倒数两个阶段似乎吻合的是有问题的。
看上去好像不是吻合的那么好,但实际上这个地方也是可以做解释的,原因就在于说这里做了一个 learning rate K,learning rate 除以了 10,但是根据上文推导的平衡公式,它在 unit 规点词保持不变的情况下,wt 应该是满足是跟根号 𝜂 的开 4 次方成正比的。
当我 learning rate 减少的时候,VDK 也会趋于减少。所以,除以 10 的时候,这个值如果打出来,会发现它其实恰好就等于里面平稳状态是 1/10。因为 learning rate 除以 10,此时 WT 相当于破坏了在第一个 learning rate 阶段的平稳状态,但没来得及于进入新的平稳状态。
所以回复结果,其实是在达到新的平稳状态的过程中。所以这个结果上面我后面会展示一张图,WT 在这个结果中是在逐渐变小的。因为我的 learning rate 除以了 10 倍,WT 会除以根号 10 的开 4 次方,这是第一个解释。
第二解释就是可以估算大概每次 learning rate 直接除以了 K 以后,大概至少需要多少步才能达到一个新的平衡条件。 可以具体地算一下。
在 ImageNet 任务里面,这里面每一个 Epoch 可大概是 5000 步(我这选取的是 256,所以我的每一个 Epoch 是 5000 步)。α=0.9,λ=10 的 - 4 次方, 𝜂 等于 10 的 - 3 次方,K=10,learning rate=10,这时候可以算出它至少需要 57 万步。
但是在实际的第三个阶段, 只有大概 10 万步迭代,所以说它还远远没有回复到新的平稳状态。就更不用说最后一个阶段只有 5 万步。但是最后一阶段 learning rate 更小,所以它需要的迭代次数又是原来的 10 倍。
最后一个就是 500 万步,所以就导致了实际上不是它不符,而是因为我这里面展示的是每个阶段它应该有的平稳状态的一个状态,但是实际里面它还没有进入到平稳状态。所以考虑能不能够去跳过 WT 变小的步骤,每当我做 learning rate decay 的时候,我就让它立即进入到一个新的平稳状态?答案是是可以的。
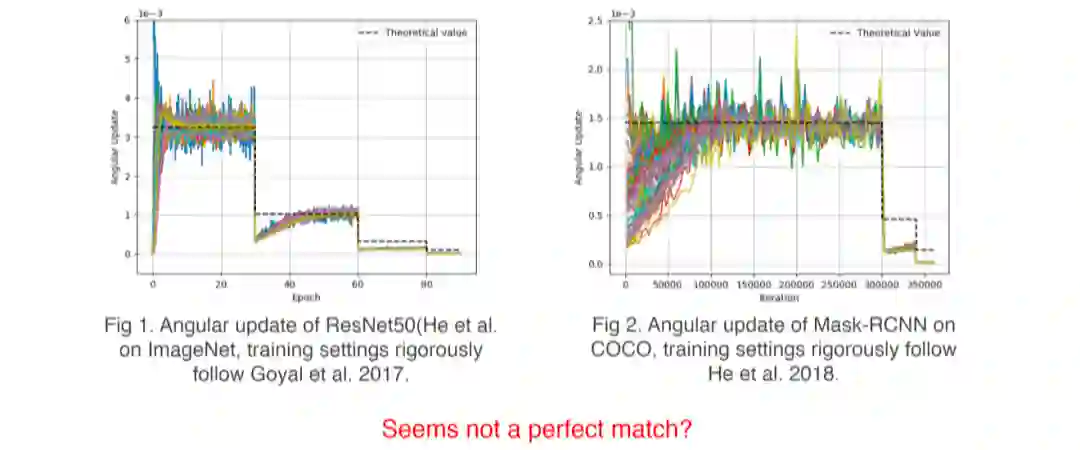
经过刚才推导,当 learning rate 除以 K 倍的时候,WT 的平稳状态情况下,应该是除以 K 的开 4 次方,可以试着每次做 learning rate decay 除以 K 时,我就可以去除以这个值可以看一下它的效果如何。
上图是 ImageNet 的实验结果,就是 rescaling 的结果。每次做 learning rate decay 的时候,把 scale weight 除以 10 的开 4 次方,只做了这一件事。现在看到此时它们每一个阶段的理论值和实际值都是完美符合的,而且这里面给出了蓝线是标准,不做干涉的情况下的 weight 的一个层。
可以看到原来每次做 learning rate decay 的时候,这边是缓缓下降的。Rescale 的时让它立即移除于原来的根号 10 的 4 次方,当然它这里面还是在变动,但这个变动是来自于 unit gradient 的缓缓变动,比 Angular update 回复的 condition 要快,所以可以看到角度更新,它仍然是满足这个理论值。
上述内容是是 ImageNet 实验,COCO 也是一样的,做 learning rate decay 的时候,只需要跟着去 decay weight,也可以达到这样的效果,理论值和真实值是完美符合的。
除此以外还测试其他的一些网络结构,比如说 MobileNet_v2 的 Performance,这里面的是没有做 rescaling 的结果,可以看到它还是有差距,前文已经做了解释,是正常现象。再比如说 Shufflenet_v2+,其中是有 SE 结构的,但是它对于那些具有放松不变性的 conv 层仍然具有这个性质,就说明这实际上确实是一个普遍的规律,而不是特殊情况。
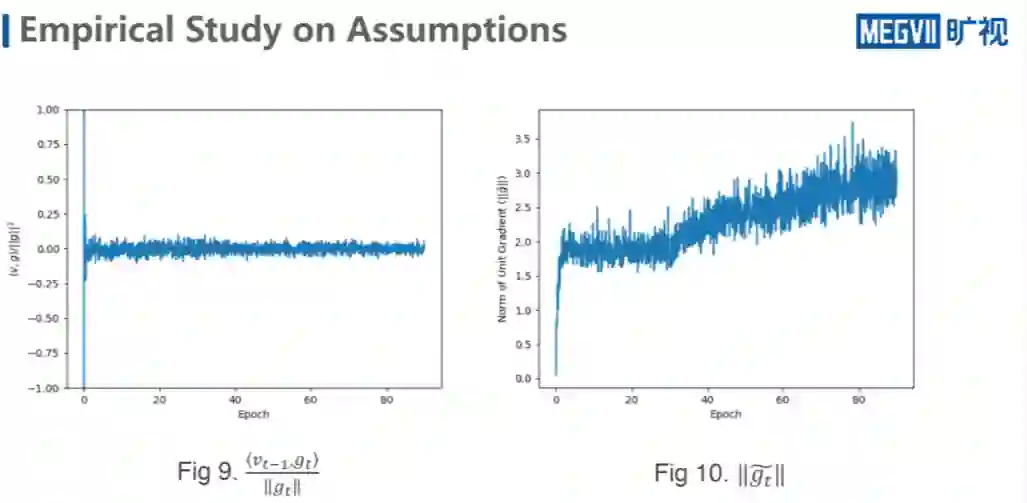
前文定义里面提到的两个 assumption做一次 empirical study。上图是第一个 assumption ,unit gradient 接近于 converge,可以看到在实际的取得某一个层中,在同一个 learning rate stage 的情况下确实变化不大,可以看到它的上升的过程。
由于上升幅度非常的慢,而且迭代次数非常多,所以如果把它拉升来看,其实在某一个局部内都是接近于 converge,说明在 unit gradient 是满足的。
第二个是关于内积的值和对应 GT 的范数。这个原理其实是有根据的,我 T-1 的 moment 是累积了前 7 次的 gradient 的向量,而我 GT 是取了 DT+1batch 的 sample,所以说这里 T+1 的 sample 是随机的,跟前面的没有任何关系,导致了它们之间某种程度上有一定的独立性。
另一方面又是维度非常的高。独立性和维度都非常好,就导致了 VT-1 和 GT 约等于是一个正交的关系,导致数值一直在零附近徘徊的。所以就从实验上来讲,这两个结果也都是 ImageNet 的结果。
所以这一全面优化的理论所依赖的强假设是很少的,而且所依赖的稍微强一点假设又都是符合实际情况的,这让优化的结果具有普适性,在一些哪怕最复杂的 CV 任务中也能得到验证。
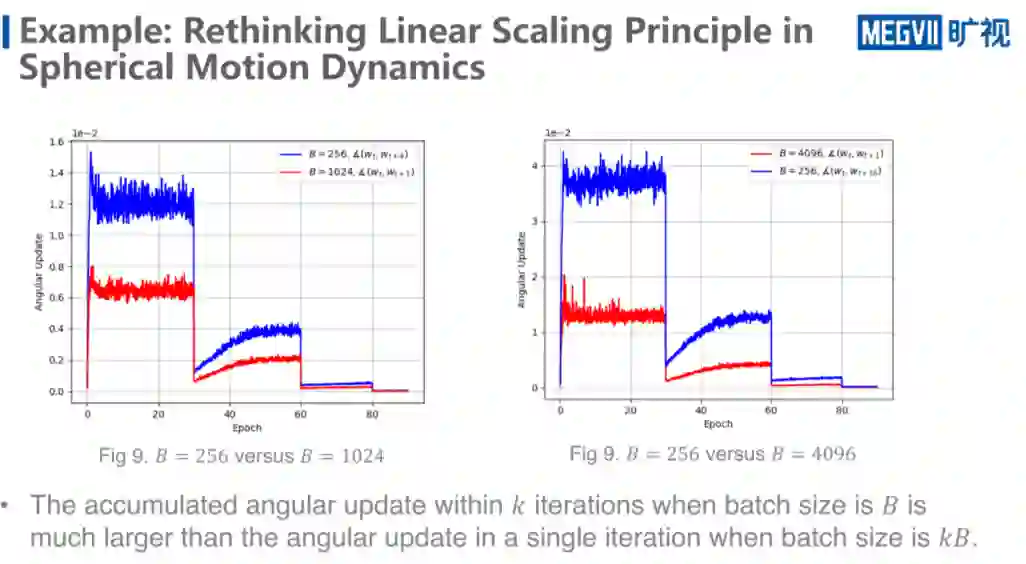
结尾部分我们看上图的例子, 来看看 Spherical Motion Dynamics 究竟会给一些什么样的启发,这个例子是关于 linear-scaling principle的,是2017 年的何恺明团队 random net 相关的一个说明性文章,总结出一个非常经典的调参方法:当 batch size 增大的时候,该怎么去调 learning rate。
他们给出的一个方法是,batch size 增大多少倍, learning rate 就增大多少倍,始终成正比。经过了无数的实践证明这个方法是非常稳定的,基本上效果都还不错的。
他们的 intuition 是来自于什么呢?假设我的 batch size 是 B,做如上图 T 加 K 次的 WT 的迭代。相当于是 B 乘 K 个样本,取梯度,然后累积。如果我的 batch size 是 KB 那是不是可以把它等效为,这里面是 K 次的 gradient,把它放到一次 gradient 里面去算它。
等效以后就发现 learning rate 似乎是原来的 K 倍了。但问题是在球面优化的 setting 下,实际的 update 的量实际上和 learning rate 是没有关系的,是完全由超参所决定的。
上图给出了两个 setting,一个是 baseline b 都是 256,WT 和 WT+4,这里是 T+4,就是 4 次累积的角度更新量的变化情况。红线是 batch size 乘了 4 倍以后,单步更新的角度变化情况。可以看到 linear-scaling principle 其实并没有去满足所谓的等效法则,它实际的更新量其实比大 batch 大太多了,上图是 16 倍。
补充说明比较有意思的一点,可以看到,即使是 4 次累积,好像也是满足于某一种平稳状态的分布的。我做了推导和实验,发现它确实应该有一些性质,但是并不是每一层都一样,好像还是跟层与层之间的关系有关系,但是这个红线它还是满足球面优化的性质,公式经验值和理论值是可以吻合的。
还是回到原来的话题,在 linear-scaling principle 的情况下,由于我的在同样的训练的 Epoch 数的情况下,我的 batch size 增大了,迭代数就减小了,所以我需要去增大我的 learning rate,去弥补我的减小的更新迭代次数所造成的训练不充分的损失,所以要把 learning rate 调大。但可以看到,小 batch 比大 batch 训练程度似乎少了太多,少了几倍。
经验上来讲,linear-scaling principle 确实在 ImageNet 任务上适用范围就是在 256 到 8k 左右都,掉点的次数都不多,但是一旦超过了 8k ,就会有非常显著的掉点。 掉点可能很大一部分程度上就来自于 Spherical motion dynamics 的缘故,一方面,这两个训练的程度差得实在是太远了,另一方面可能是因为迭代次数确实不够,或者说 update 实在是太大了,导致它不收敛。
总结一下全文,首先本文的工作揭示了 Spherical motion dynamics 在带 BN 和 WD 的 DNN 自然满足的状态。同时也展示了考虑 SMD 的影响是非常有必要的。其次从 SMB 中 得出了一个理论值,给出了关于角度更新量,同时这个理论值可以在真实的数据、复杂的数据中有效。SMD 同时可以给一些常见的、但又没有很好理论解释的实验现象提供一些非常直观的、本质的解释。
文章最后审视了一些常用的 parameter method 或优化方法,比方说最简单 SGDM 方法,会发现如果不考虑 SMD 的话,它的表现实验上和理论上会非常不一样,但是考虑 SMD 就会有很有趣的现象。无论是在使用还是设计新的方法,都可能需要有必要去考虑 SMD 的影响。
关于数据实战派
数据实战派希望用真实数据和行业实战案例,帮助读者提升业务能力,共建有趣的大数据社区。
![]()
![]()
如何才能让更多的优质内容以更短路径到达读者群体,缩短读者寻找优质内容的成本呢?答案就是:你不认识的人。
总有一些你不认识的人,知道你想知道的东西。PaperWeekly 或许可以成为一座桥梁,促使不同背景、不同方向的学者和学术灵感相互碰撞,迸发出更多的可能性。
PaperWeekly 鼓励高校实验室或个人,在我们的平台上分享各类优质内容,可以是最新论文解读,也可以是学习心得或技术干货。我们的目的只有一个,让知识真正流动起来。
📝 来稿标准:
• 稿件确系个人原创作品,来稿需注明作者个人信息(姓名+学校/工作单位+学历/职位+研究方向)
• 如果文章并非首发,请在投稿时提醒并附上所有已发布链接
• PaperWeekly 默认每篇文章都是首发,均会添加“原创”标志
📬 投稿邮箱:
• 投稿邮箱:hr@paperweekly.site
• 所有文章配图,请单独在附件中发送
• 请留下即时联系方式(微信或手机),以便我们在编辑发布时和作者沟通
🔍
现在,在「知乎」也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」订阅我们的专栏吧
关于PaperWeekly
PaperWeekly 是一个推荐、解读、讨论、报道人工智能前沿论文成果的学术平台。如果你研究或从事 AI 领域,欢迎在公众号后台点击「交流群」,小助手将把你带入 PaperWeekly 的交流群里。
![]()
![]()