Pathdreamer:室内导航的世界模型


发布人:Google Research 的研究工程师 Jing Yu Koh 和高级研究员 Peter Anderson
人们在陌生的建筑物中走动时,会利用大量的视觉、空间和语义线索来有效地锁定目标位置。例如,即使在陌生的房子中,如果你看到餐饮区,就可以大致推测厨房和休息区域的位置,进而推断出常见家用物品的位置。对于机器人智能体来说,在陌生建筑中利用语义线索和统计规律的难度较大。典型的解决方法是隐式学习这些线索,通过端到端的无模型强化学习,了解这些线索的细节以及如何用于导航任务。不过,通过这种方式学习导航线索的学习成本太高,不便于检测,而且必须从头开始学习才能在其他智能体中重复使用。
无模型强化学习
https://ai.facebook.com/blog/near-perfect-point-goal-navigation-from-25-billion-frames-of-experience/

在陌生建筑物中走动的人们可以利用视觉、空间和语义线索预测转角的环境。具有此功能的计算模型是视觉世界模型
对于机器人导航和规划智能体来说,一种有吸引力的替代方法是使用世界模型封装周围环境中丰富且有意义的信息,让智能体可针对其所处环境中的具体情况预测出可靠结果。此类模型在机器人科学、模拟和强化学习中获得广泛关注,并已取得不错的结果,包括发现已知首个针对模拟 2D 赛车任务的解决方案,以及在 Atari 游戏中实现接近人类水平的表现。不过,与复杂而多元的真实环境相比,游戏环境仍然相对简单。
已知首个针对模拟 2D 赛车任务的解决方案
https://worldmodels.github.io/
在发表于 ICCV 2021 上的“Pathdreamer:室内导航的世界模型 (Pathdreamer: A World Model for Indoor Navigation)”一文中,我们推出了一个世界模型,该模型使用非常有限的观察结果和拟定的导航轨迹,为建筑内智能体看不到的区域生成高分辨率 360º 视觉观察结果。如下方视频中所示,Pathdreamer 模型可以合成单个视角的沉浸式场景,预测智能体移动至新视野或完全陌生的区域(例如转角)的观察结果。除了可用于视频编辑和生成动态照片,解决此任务可以整理关于人类环境的信息,以便帮助机器智能体在现实环境中完成导航任务。例如,要查找特定房间或陌生环境中物体的机器人,可以使用此世界模型执行模拟,以便在实际执行搜索任务前识别物体可能出现的位置。Pathdreamer 这一类的世界模型还可通过在模型中训练智能体,提升训练数据量以供智能体使用。
Pathdreamer:室内导航的世界模型
https://arxiv.org/abs/2105.08756

只需借助单个观察结果(RGB、深度图像和语义分割),并输入拟定导航轨迹,Pathdreamer 就能合成距离原始地点远至 6-7 米的位置(包括转角)的高分辨率 360º 观察结果。如需获得更多结果,请参考完整视频
完整视频
https://www.youtube.com/watch?v=StklIENGqs0


Pathdreamer 会将一个或多个先前观察结果作为输入,生成对未来地点的轨迹预测。这些预测可能提供到前台,或由智能体将其与返回的观察结果交互迭代后提供。输入和预测均由 RGB、语义分割 (Semantic segmentation) 和深度图像 (Depth map) 组成。具体来说,Pathdreamer 会使用 3D 点云代表环境中的表面。云中的点均添加了其 RGB 色彩值以及语义分割类,例如 wall、chair 或 table。
为预测新地点中的视觉观察结果,点云会首先在新地点以 2D 方式呈现,以便提供“指导”图像,Pathdreamer 可利用这些图像生成逼真的高分辨率 RGB、语义分割和深度图像。随着模型不断“移动”,新的观察结果(无论是真实或预测结果)均在点云中积累。使用点云作为记忆的一个优势在于时间一致性,再次访问的区域将以同一方式根据先前观察结果进行渲染。

Pathdreamer 内部通过包含语义标签(顶部)和 RGB 色彩值(底部) 的3D 点云代表环境中的表面。为了生成新的观察结果,Pathdreamer 会“穿过”点云来到新位置,并使用重新投射的点云图像作为“指导”
时间一致性
https://nvlabs.github.io/wc-vid2vid/
为了将指导图像转换为逼真可信的输出,Pathdreamer 工作方式分为两个阶段:第一阶段是结构生成器创建语义分割和深度图像;第二阶段是图像生成器将这些图像渲染到 RGB 输出中。概念上来说,第一阶段可提供场景的高水平可信语义表示,第二阶段将把这些表示渲染为逼真的彩色图像。两个阶段均基于卷积神经网络。
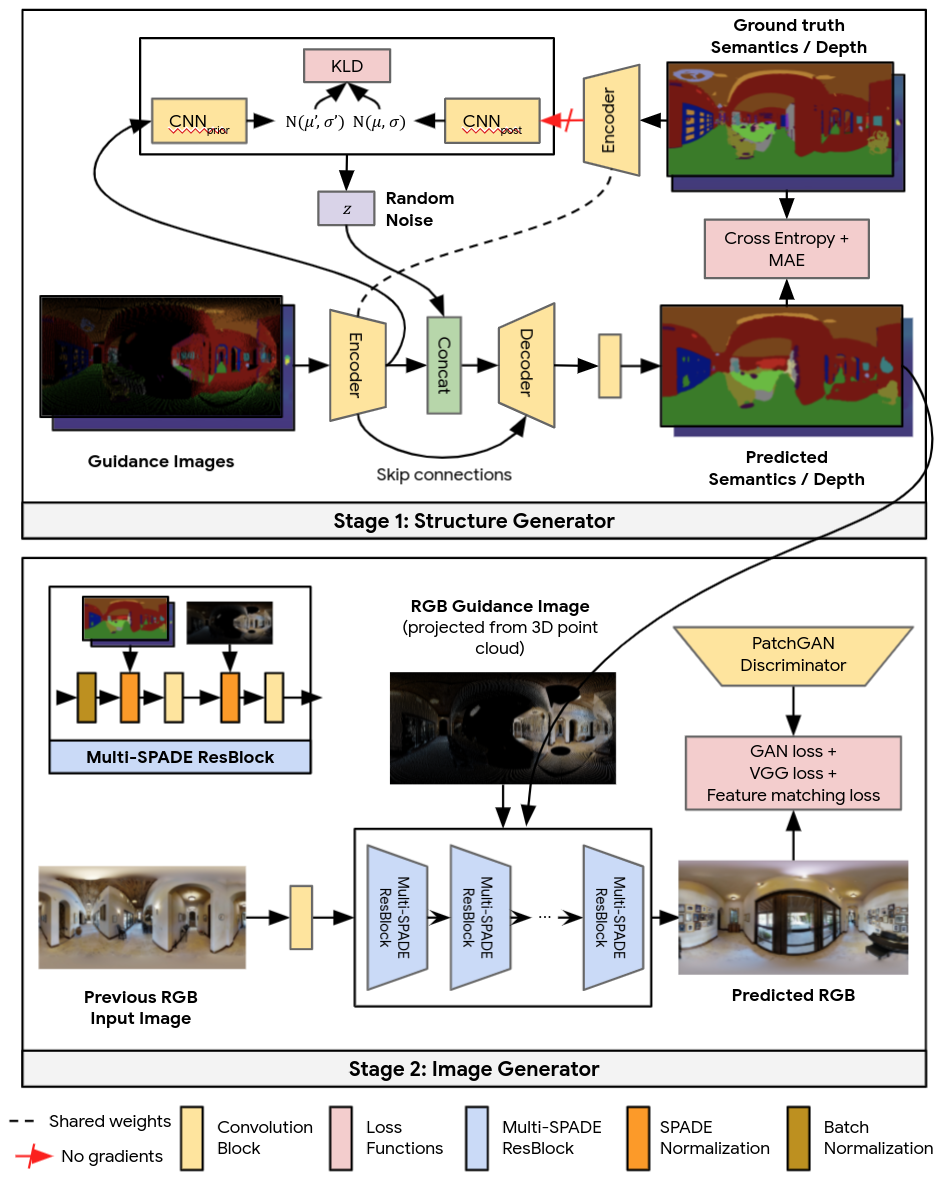
Pathdreamer 工作方式分为两个阶段:第一阶段是结构生成器创建语义分割和深度图像;第二阶段是图像生成器将这些图像渲染到 RGB 输出中。结构生成器根据噪声变量进行调节,使模型能为很难确定的区域合成多种场景
在很难确定的区域(例如预测可能为转角的区域或未探测过的房间),生成的场景可能性差异很大。结合随机视频生成中的概念,Pathdreamer 中的结构生成器根据噪声变量进行调节,该变量表示指导图像中未捕获的下个地点的随机信息。通过对多个噪音变量进行采样,Pathdreamer 可以合成多种场景,让智能体能对给定轨迹的多个可信结果进行采样。这些不同结果不仅反映在第一阶段输出(语义分割和深度图像)中,也反映在生成的 RGB 图像中。
随机视频生成
https://arxiv.org/abs/1802.07687
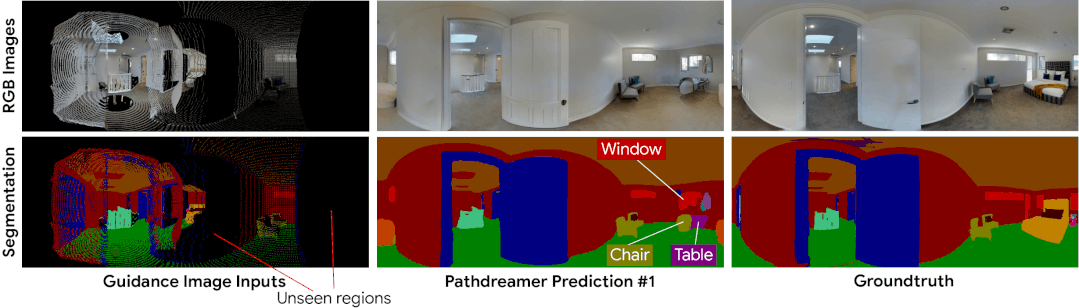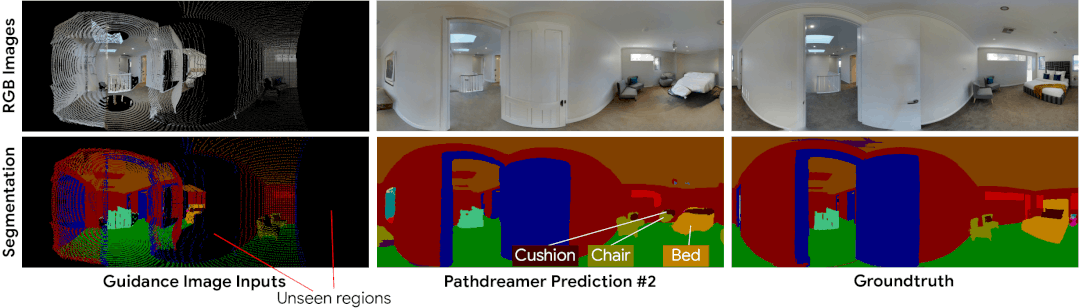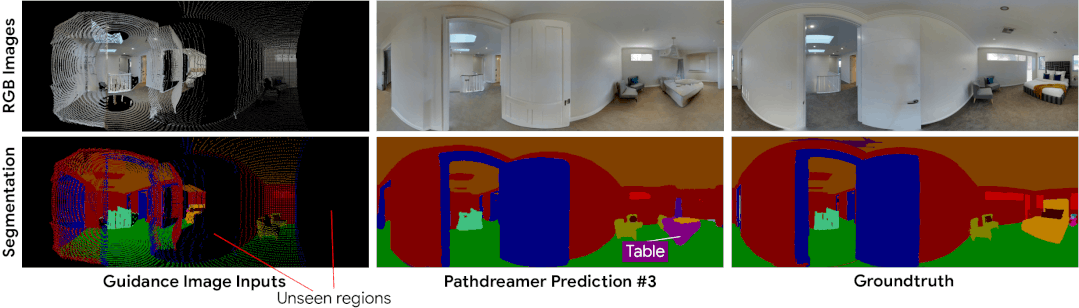
Pathdreamer 能够为很难确定的区域生成多种可信图像。最左列的指导图像表示智能体先前检测到的像素。黑色像素表示先前未检测到的区域,Pathdreamer 会通过对多个随机噪音向量进行采样为此类区域渲染出多种输出。在实践中,生成的输出可利用智能体探索环境时新观察到的结果
将图像和来自 Matterport3D 的 3D 环境重构数据进行训练,Pathdreamer 能够合成逼真图像以及连续的视频序列。因为输出图像为高分辨率 360º 格式,可以立即由现有导航智能体转换,用于任意相机视野范围。如需获取更多详情并亲自试用 Pathdreamer,欢迎查看我们的开放源代码。
Matterport3D
https://niessner.github.io/Matterport/
连续的视频序列
https://www.youtube.com/watch?v=HNAmsdk7lJ4
开放源代码
https://github.com/google-research/pathdreamer
作为视觉世界模型,Pathdreamer 显示了改善下游任务的巨大潜能。为了证明这一点,我们将 Pathdreamer 应用于 Vision-and-Language Navigation (VLN) 任务,在执行任务时,具身智能体必须遵循自然语言的指示,在逼真 3D 环境中导航到新地点。借助 Room-to-Room (R2R) 数据库,我们开展了一项实验,实验中智能体跟随指令提前规划路线:模拟穿过环境的多种导航轨迹可能,并根据导航指示对每种轨迹进行排名,选择最佳轨迹作为行进路线。此过程中需要考虑三个场景:Ground-Truth 场景中,智能体会通过与真实环境的互动(例如移动)进行路线规划;Baseline 场景中,智能体会通过与导航图(其中编码了建筑物中的可导航路线,但不提供任何视觉观察结果)的互动提前规划路线,不会移动;在 Pathdreamer 场景中,智能体通过与导航图的互动提前规划路线(不会移动),并且会接收 Pathdreamer 生成的相应视觉观察结果。
Room-to-Room
https://bringmeaspoon.org/
在 Pathdreamer 场景中,以三步的距离(约 6 米)进行提前规划时,VLN 智能体可实现 50.4% 的导航成功率,远高于基线场景中不借助 Pathdreamer 时40.6% 的导航成功率 。这表明, Pathdreamer 会对关于室内真实环境有用且可访问的视觉、空间和语义线索进行编码。作为完美世界模型的能力上限,在 Ground-Truth 场景中(通过移动进行路线规划),智能体的成功率为 59%,尽管我们注意到此场景需要智能体花大量时间和资源用于真实探索多种轨迹,而这在真实场景中由于代价太高而几乎不可行。
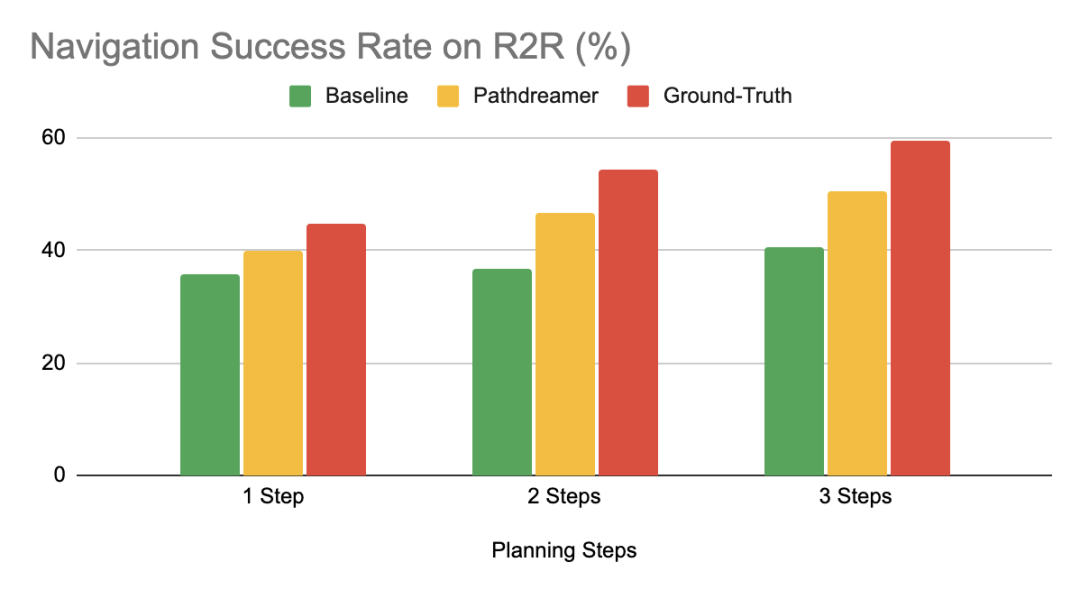
我们使用 Room-to-Room (R2R) 数据库评估了跟随指示的智能体的若干规划场景。使用导航图,并借助 Pathdreamer 合成的相应视觉观察结果提前规划路线,比单独使用导航图(Baseline 场景)提前规划路线更有效,可以达到使用完美符合现实的世界模型(Ground-Truth 场景)提前规划路线时约一半的效果
这些结果显示了将 Pathdreamer 等世界模型用于复杂具身导航任务的潜力。我们希望 Pathdreamer 能够提供一些基于模型的方法,帮助您应对具身导航任务(例如导航至指定物体和 VLN)难题。
将 Pathdreamer 应用于其他具身导航任务(例如 Object-Nav、连续 VLN 和街道导航)是未来的发展方向。
Object-Nav
https://arxiv.org/abs/2006.13171
连续 VLN
https://arxiv.org/abs/2004.02857
街道导航
https://ai.googleblog.com/2020/02/enhancing-research-communitys-access-to.html
我们还设想未来进一步优化 Pathdreamer 模型的架构和建模方向,并使用更多数据库进行测试,包括但不限于户外环境。如希望深入探索 Pathdreamer,请访问我们的 GitHub 代码库。
GitHub 代码库
https://github.com/google-research/pathdreame
此项目是 Jason Baldridge、Honglak Lee 和 Yinfei Yang 的协作成果。我们感谢 Austin Waters、Noah Snavely、Suhani Vora、Harsh Agrawal、David Ha 和在项目过程中提供反馈的其他人。我们还感谢 Google Research 团队的全面支持。最后,我们感谢 Tom Small 创建了第三张图片中的动画。

点击“阅读原文”访问 TensorFlow 官网

不要忘记“一键三连”哦~

分享

点赞

在看


