【Time Series】温度预测挑战赛初赛复盘

简单复盘一下这个比赛。
1.赛题概要
1.1 赛事背景
随着计算机技术的发展,我国逐渐实现了从传统农业到现代农业的转变,正逐步迈向智慧农业。温室是现代农业技术应用的典型场景,其内部环境具有可操作性,能人为形成适宜植物生长的小型封闭生态系统,提升农产品的产量和质量,因此被广泛应用于农业生产中。在温室的各项环境因子中,作物对温度最为敏感。温度的高低影响植株细胞的酶活性,从而影响作物的生长速度、产量和质量,因此温度对作物生长发育影响极大。为了保证农产品的产量和质量,应保证作物正常生长,需对温室温度进行精确的调控。
1.2 赛事任务
温室温度调控需要对温室温度进行精准的预测,本次大赛提供了中国农业大学涿州实验站的温室温度数据作为样本,参赛选手需基于提供的样本构建模型,预测温室温度变化情况。
1.3 评审规则
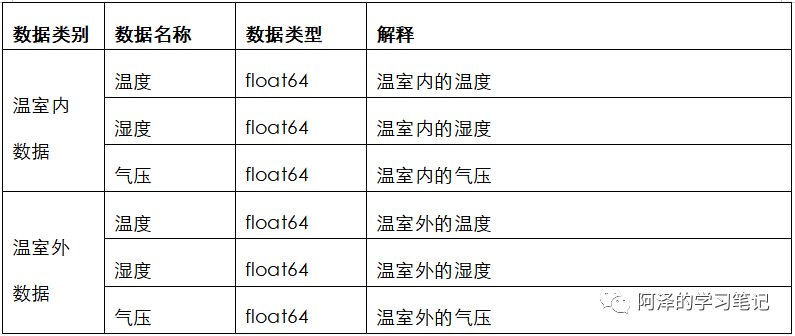
本次比赛为参赛选手提供了温室内外的部分传感器数据,包括温室内的温度、湿度、气压以及温室外的温度、湿度、气压。
本次比赛分为初赛和复赛两个阶段,初赛阶段提供约 30 天的传感器数据,其中前 20 天的数据作为训练数据,后 10 天的数据用于做温度预测;复赛阶段提供约 15 天的传感器数据,其中前 10 天的数据作为训练数据,后 5 天的数据用于做温度预测。
特别说明,温室内的湿度和气压以及温室外的温度、湿度和气压会对温室内的温度产生一定的影响。
采用 MSE 作为评估标准。
数据:
2.赛题分析
主要是把时间序列问题通过构造历史特征转为回归问题,由于数据量不多,所以没有尝试使用深度学习模型。
3.比赛记录
3.1 记录
-
【晖】拿到鱼佬 baseline 并涂涂改改,分数为 0.11701;
-
【晖】特征工程:室内外湿度差,分数为 0.11346;
-
【锦】模型策略:将室内外温度取 log 作差作为 label,分数为 0.10254;
「分析」:室内外温度变化方向类似,包括所有的突变异常,所以想到可以直接去预测室内外温度的差,然后利用室外温度来得到室内温度,取 log 是因为温度差的分布为偏态分布,而取完 log 后则为正态分布。
-
【晖】特征工程:对室内外气压差取 log,分数为 0.10224;
-
【泽】模型策略:修改 xgboost 的损失函数 mae -> rmse,分数为 0.1007;
「分析」:原先损失函数设置为 mae,主要目的是减少异常值的干扰,而现在的目标为温度差,几乎不存在异常,且线上评价指标为 mse,所以我们将损失函数改为 rmse,保持与线上评估标准保持一致。
-
【泽】特征工程:修改划窗统计特征的 Bug,分数为 0.10022;
-
【泽】模型策略:修改 xgboost 的 tree_method 为 gpu_hist,分数为 0.09907;
-
【昊】数据清洗:修正气压异常值并使用插值填补缺失值,分数为 0.09823;
「分析」:尝试的异常值的处理的效果,插值<向后填充<指数平滑;
-
【泽】特征工程:构造更长周期的开窗统计特征,分数为 0.0956;
-
【晖】数据清洗:气压缺失值采用向后填充,分数为 0.09366;
-
【泽】特征工程:(无记录),分数为 0.0935;
-
【锦】模型策略:将迭代次数降低到 20k,降低过拟和,分数为 0.09285;
「分析」:线下测试时,使用线下构造的验证集作为早停的标准,但根据线上结果反馈得知过拟合。
-
【昊】数据清洗:修改异常值处理的 Bug,分数为 0.09088;
-
发现了严重的 bug,决定修复,分数为 0.09471;
-
【昊】数据清洗:取消室内气压异常的处理,并将迭代次数控制为 26 k,分数为 0.09378;
-
【晖】数据清洗:室外气压异常修改为指数平均,分数为 0.09213;
-
【煜】特征工程:添加湿度和温度的分类特征,迭代次数 40k,分数为 0.0916;
-
【泽】模型策略:学习 label 误差并调参,分数为 0.08379;
「分析」:由于原本模型学习的室内外温度取 log 后的差,所以可以在模型还原后,可以继续学习残差。
-
【晖】特征工程:对 hour 和 day 构造分桶后,并在桶内构造统计特征,分数为 0.08357;
-
【泽】特征工程:修改统计值的 min 和 max 为 0.05 和 0.95 分位数,分数为 0.08207;
「分析」:由于没有对温度进行异常值修复,直接用 max 和 min 对异常值敏感,会把异常值计算进去,所以采用了 0.05 和 0.95 分位数,增强模型泛化能力。
-
【昊】特征工程:去掉 range 特征,分数为 0.08205;
-
【晖】数据清洗:填补训练集部分缺失值,分数为 0.08125;
-
【晖】特征工程:为 test 拼接一部分 train 数据,填补完整统计特征,分数为 0.08062;
「分析」:之前的开窗统计特征的是训练集和测试集分开构造的,将其拼接后再进行特征构造,相当于对 test 进行缺失值填补;
-
【昊】特征工程:对 test 拼接数据进行采样并统计中位数,分数为 0.08022;
-
【昊】数据清洗;对 test 的断层进行填充,分数为 0.0772;
「分析」:手术刀操作,对 test 中 50 多处断层数据进行缺失值填补,需要非常大的耐心,但收益也非常大。
3.2 汇总
-
数据清洗 0.01115; -
特征工程 0.01042; -
模型策略 0.02207;
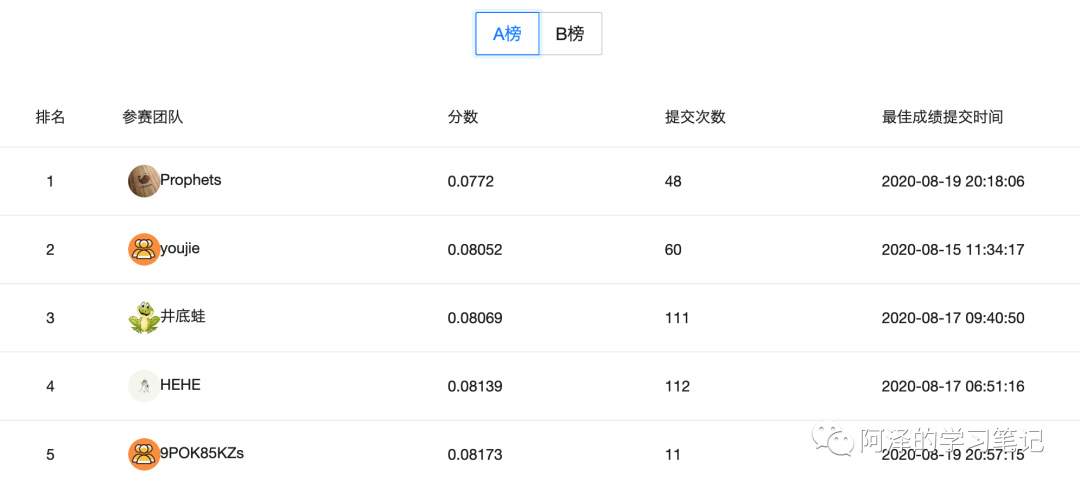
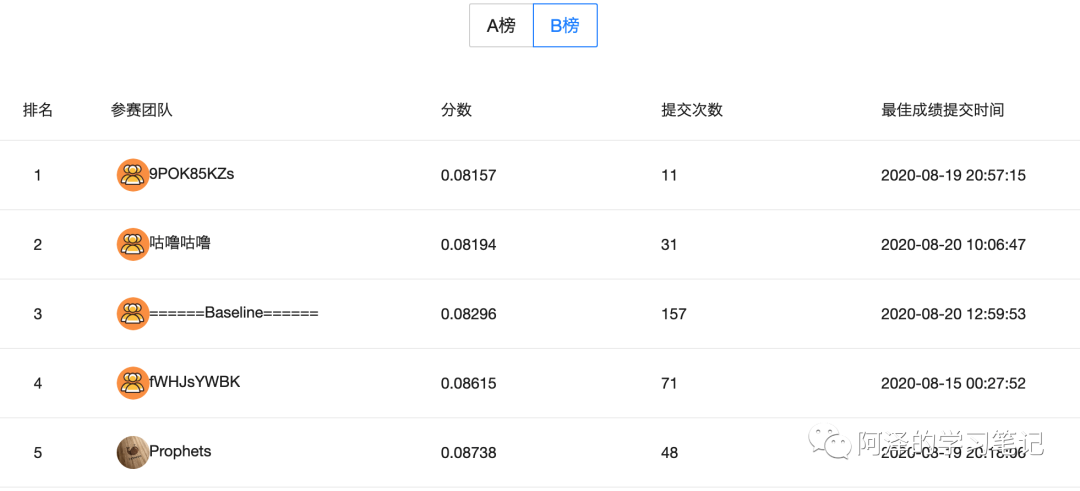
4.比赛结果
-
初赛 A 榜第一,B 榜第五; -
复赛由于个人原因没有参与下去,小队里也只有一个同学在不断尝试。
5.反思
-
数据清洗慢工出细活,需要多去学习; -
初赛 A/B 榜切换时,掉到第 5 名,主要原因有两个: -
测试集数据太少,容易抖榜; -
后期没有好好利用线下测试集,线上和线下同时提升更有意义; -
复赛确实没有心情和精力再去参加了,有点坑队友; -
抱歉锦同学,由于个人原因与之出现了不太好的插曲,以后要时刻注意着友谊第一,比赛第二。
由于微信平台算法改版,公号内容将不再以时间排序展示,如果大家想第一时间看到我们的推送,强烈建议星标我们和给我们多点点【在看】。星标具体步骤为:
(1)点击页面最上方"AINLP",进入公众号主页。
(2)点击右上角的小点点,在弹出页面点击“设为星标”,就可以啦。
感谢支持,比心

推荐阅读
征稿启示| 200元稿费+5000DBC(价值20个小时GPU算力)
完结撒花!李宏毅老师深度学习与人类语言处理课程视频及课件(附下载)
模型压缩实践系列之——bert-of-theseus,一个非常亲民的bert压缩方法
文本自动摘要任务的“不完全”心得总结番外篇——submodular函数优化
斯坦福大学NLP组Python深度学习自然语言处理工具Stanza试用
关于AINLP
AINLP 是一个有趣有AI的自然语言处理社区,专注于 AI、NLP、机器学习、深度学习、推荐算法等相关技术的分享,主题包括文本摘要、智能问答、聊天机器人、机器翻译、自动生成、知识图谱、预训练模型、推荐系统、计算广告、招聘信息、求职经验分享等,欢迎关注!加技术交流群请添加AINLPer(id:ainlper),备注工作/研究方向+加群目的。

阅读至此了,分享、点赞、在看三选一吧🙏


